上篇文章简单的填了一个坑基于LSM数据库的实现了WAL,在该版本中如数据写入到内存表的同时将未持久化的数据写入到WAL文件,在未将数据持久化时程序崩溃,可通过WAL文件将数据还原恢复从而避免了数据的丢失。
目前此基于LSM的数据库还有三大坑:
1、索引问题
2、SSTable合并问题
3、单机版本问题;
本篇文章将解决其中的一个坑,索引问题;
索引问题
到目前为止还没有详细解释当前系统的索引问题到底是什么,不解决会导致什么问题;目前系统在写入数据将数据持久化到SSTable文件并写每一个SSTable文件对应的索引数据时是为每个数据项Key都记录了相应的索引数据,此时的索引为全量索引;
全量索引就会导致索引文件快速增大,索引文件过大后维护的性能、查询性能就会大幅下降;索引此时需要解决索引文件快速增大问题;这里引入了:稀疏索引,稀疏索引也是业内比较常见,普遍用到的数据结构;下面详细介绍对比全量索引与稀疏索引的区别;
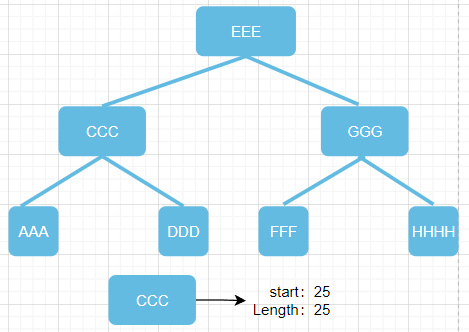
全量索引树为每个key存储对应的key在数据文件中的起始位置、数据项长度,导致其索引结构无比庞大;
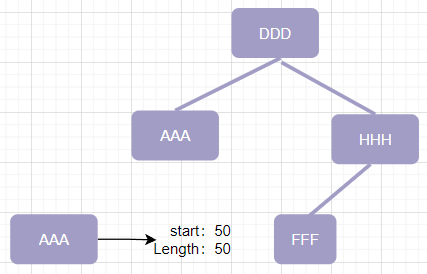
经过优化,此稀疏索引树结构每隔指定间隔才存储一个索引项;
存储的数据为每个间隔区间的所有key数据,Key为该批的第一个key,值为此批次的:起始位置、批次数据项长度,使得索引结构容量大大减少;
本图为间隔两个Key存储一个索引;
节点AAA: 存储AAA、CCC数据索引
节点DDD: 存储DDD、EEE数据索引
节点HHH: 存储HHH数据索引
节点FFF: 存储FFF、GGG数据索引
索引查询
此时稀疏索引的存储结构方式已经解决,在查询与之前也有不少区别;
全量索引:使用key在索引树查找对应数据项,根据索引存储的start、length去对应的数据文件读取相应的数据;
稀疏索引:在索引树中查找最后一个小于所查询key的key节点、第一个大于所查询key的key节点,使用该节点存储的start、length去对应数据文件读取相应的数据块,从中对比查找出所查询的key;
经过此次索引结构的优化,又填了一大坑,还有两大坑待解决:
1、SSTable合并问题
2、单机版本问题;