二叉搜索树(Binary Search Tree)为非线性结构,树与链表一样为动态数据结构也可称二叉搜索树为多个链表所组成实现的,由于二叉搜索树性能比较高所以属于比较常用的数据结构;二叉搜索树每个节点除了Key外还存在指向左子树的Left节点与指向右子树的Right节点,如左或右子树不存在则该节点值为Null;
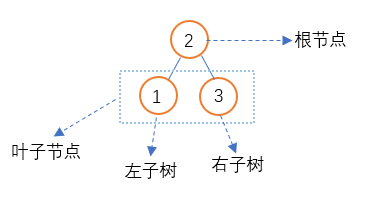
二叉搜索树为一种特殊的二叉树,与二叉树有类似的结构,存在唯一的根节点,每一个节点最多只存在两个子节点分别为左子树与右子树,当某个节点不存在任何子节点时又称为叶子节点,每个节点有且只有一个父节点,二叉树具有与生俱来的递归结构;
1、 唯一根节点
2、 每个节点最多只有两个节点
3、 叶子节点不存在任何子节点
4、 只有唯一父节点
二叉搜索树与普通二叉树的根本区别在于二叉搜索树中任意一个节点的值大于该节点左子树中任意节点的值,小于该节点右子树中任意一个节点的值;
1、 节点的左子树任意一个节点值比当前节点值小
2、 节点的右子树任意一个节点值比当前节点值大
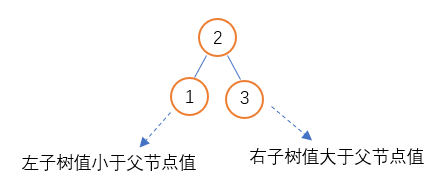
由于二叉搜索树左右子树所具有的独特特性,当使用二叉搜索树存储数据时数据的查找将具有非常高的性能,但就是因为该特性所以并非所有数据都可用二叉搜索树存储,能存储的数据元素必须具备可比较性;
二叉搜索树的实现
1、二叉搜索树定义
根据二叉搜索树的特性先定义该数据类型的结构;
type BST struct {
root *TreeNode
size int
compare Comparable
}
type TreeNode struct {
e interface{}
left *TreeNode
right *TreeNode
}
BST:为定义的二叉搜索树自定义对象
TreeNode:为树中每个节点的节点自定义对象
compare:为定义的用于树中节点元素进行数据对比的对象
size:二叉搜索树的元素个数
root:树的根节点
e:节点元素值
left:左子树
right:右子树
2、具体二叉搜索树方法实现
/**
元素比较
*/
type Comparable func(c1 interface{}, c2 interface{}) int
/**
创建二叉树
*/
func NewBST(comparable Comparable) *BST {
return &BST{size: 0, root: nil, compare: comparable}
}
/**
创建节点
*/
func newTreeNode(e interface{}) *TreeNode {
return &TreeNode{e: e, left: nil, right: nil}
}
/**
二叉树大小
*/
func (t *BST) Size() int {
return t.size
}
/**
是否未空
*/
func (t *BST) IsEmpty() bool {
return t.size == 0
}
/**
添加元素
*/
func (t *BST) Add(e interface{}) {
t.root = t.add(t.root, e)
}
/**
用于递归添加元素
*/
func (t *BST) add(node *TreeNode, e interface{}) *TreeNode {
if node == nil {
t.size++
return newTreeNode(e)
}
if t.compare(e, node.e) < 0 {
node.left = t.add(node.left, e)
} else if t.compare(e, node.e) > 0 {
node.right = t.add(node.right, e)
}
return node
}
/**
删除元素
*/
func (t *BST) Remove(e interface{}) {
t.root = t.remove(t.root, e)
}
/**
查找最小节点
*/
func (t *BST) Minimum() *TreeNode {
return t.minimum(t.root)
}
func (t *BST) minimum(node *TreeNode) *TreeNode {
if node.left == nil {
return node
}
return t.minimum(node.left)
}
func (t *BST) remove(node *TreeNode, e interface{}) *TreeNode {
if node == nil {
return nil
}
//值与当前节点值比较
if t.compare(e, node.e) < 0 {
node.left = t.remove(node.left, e)
return node
} else if t.compare(e, node.e) > 0 {
node.right = t.remove(node.right, e)
return node
} else { // t.compare(e,node.e)==0{
//需要删除的节点为当前节点时
if node.left == nil {
//右子树顶上
var rightNode = node.right
node.right = nil
t.size--
return rightNode
} else if node.right == nil {
//左子树顶上
var leftNode = node.left
node.left = nil
t.size--
return leftNode
}
//左右节点均不为空,找到比当前节点大的最小节点(此节点为右子树最小节点)
//用右子树最小节点替代需要删除的当前节点
var successor = t.minimum(node.right)
successor.right = t.removeMin(node.right)
successor.left = node.left
node.left = nil
node.right = nil
return successor
}
}
简要介绍
由于二叉搜索树所具有的特性,所有很多操作都可用递归来实现,比如元素的添加、删除、查找等等;
1、元素添加
二叉搜索树的元素添加关键在于递归与元素值的比较,关键三点:1、节点为空创建新节点为当前节点;2、元素比当前节点小,在左子树添加;元素比当前节点大,在右子树添加;
2、元素删除
二叉搜索树的元素删除关键在于删除节点后调整树结构已保持树具备左子树小于根节点值,右子树大于跟节点值的特性;
元素删除关键点:
1、 小于当前节点在左子树查找删除
2、 大于当前节点在右子树查找删除
3、 需删除的节点左子树不存在,右子树顶上
4、 需删除的节点右子树不存在,左子树顶上
5、 需删除节点左右子树均存在,找到比该节点大的最小节点(右子树最小节点),用该节点替换需要删除的节点
由于二叉搜索树的特性,通过中序遍历可得到排序好的数据,二叉搜索树的搜索、插入、删除时间复杂度为O(log(n)),n为树的深度;
参考资料: 《算法四》