1.概述
在开发工作当中,提交 Hadoop 任务,任务的运行详情,这是我们所关心的,当业务并不复杂的时候,我们可以使用 Hadoop 提供的命令工具去管理 YARN 中的任务。在编写 Hive SQL 的时候,需要在 Hive 终端,编写 SQL 语句,来观察 MapReduce 的运行情况,长此以往,感觉非常的不便。另外随着业务的复杂化,任务的数量增加,此时我们在使用这套流程,已预感到力不从心,这时候 Hive 的监控系统此刻便尤为显得重要,我们需要观察 Hive SQL 的 MapReduce 运行详情以及在 YARN 中的相关状态。
因此,我们经过调研,从互联网公司的一些需求出发,从各位 DEVS 的使用经验和反馈出发,结合业界的一些大的开源的 Hadoop SQL 消息监控,用监控的一些思考出发,设计开发了现在这样的监控系统:Hive Falcon。
Hive Falcon 用于监控 Hadoop 集群中被提交的任务,以及其运行的状态详情。其中 Yarn 中任务详情包含任务 ID,提交者,任务类型,完成状态等信息。另外,还可以编写 Hive SQL,并运 SQL,查看 SQL 运行详情。也可以查看 Hive 仓库中所存在的表及其表结构等信息。下载地址,如下所示:
2.内容
Hive Falcon 涉及以下内容:
- Dashboard
- Query
- Tables
- Tasks
- Clients & Nodes
2.1 Dashboard
我们通过在浏览器中输入 http://host:port/hf,访问 Hive Falcon 的 Dashboard 页面。该页面包含以下内容:
- Hive Clients
- Hive Tables
- Hadoop DataNodes
- YARN Tasks
- Hive Clients Graph
如下图所示:

2.2 Query
Query 模块下,提供一个运行 Hive SQL 的界面,该界面可以用来查看观察 SQL 运行的 MapReduce 详情。包含 SQL 编辑区,日志输出,以及结果展示。如下图所示:

提示:在 SQL 编辑区可以通过 Alt+/ 快捷键,快速调出 SQL 关键字。
2.3 Tables
Tables 展示 Hive 中所有的表信息,包含以下内容:
- 表名
- 表类型(如:内部表,外部表等)
- 所属者
- 存放路径
- 创建时间
如下图所示:

每一个表名都附带一个超链接,可以通过该超链接查看该表的表结构,如下图所示:

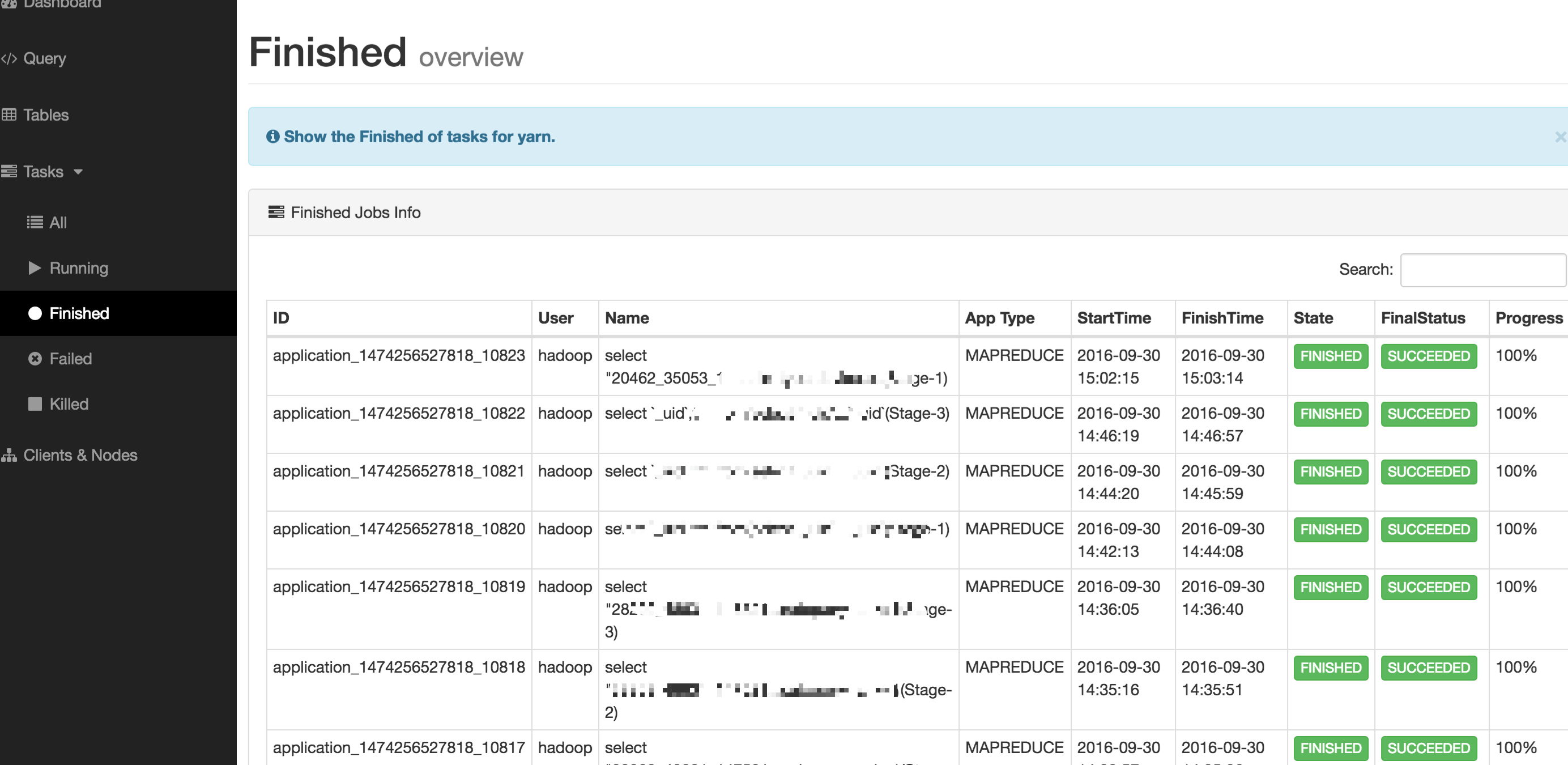
2.4 Tasks
Tasks 模块下所涉及的内容是 YARN 上的任务详情,包含的内容如下所示:
- All(所有任务)
- Running(正在运行的任务)
- Finished(已完成的任务)
- Failed(以失败的任务)
- Killed(已失败的任务)
如下图所示:
2.5 Clients & Nodes
该模块展示 Hive Client 详情,以及 Hadoop DataNode 的详情,如下图所示:

2.6 脚本命令
| 命令 | 描述 |
| hf.sh start | 启动 Hive Falcon |
| hf.sh status | 查看 Hive Falcon |
| hf.sh stop | 停止 Hive Falcon |
| hf.sh restart | 重启 Hive Falcon |
| hf.sh stats | 查看 Hive Falcon 在 Linux 系统中所占用的句柄数量 |
3.数据采集
Hive Falcon 系统的各个模块的数据来源,所包含的内容,如下图所示:

4.总结
Hive Falcon 的安装使用比较简单,下载安装,安装文档的描述进行安装配置即可,安装部署文档地址,如下所示:
5.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!