爬取网址:https://www.woyaogexing.com/touxiang/qinglv/
一、访问网址
html = requests.get(url, headers=headers).content.decode("utf-8")
得到的是html,很直观的可以右击检查查看element,就是这个里面的数据
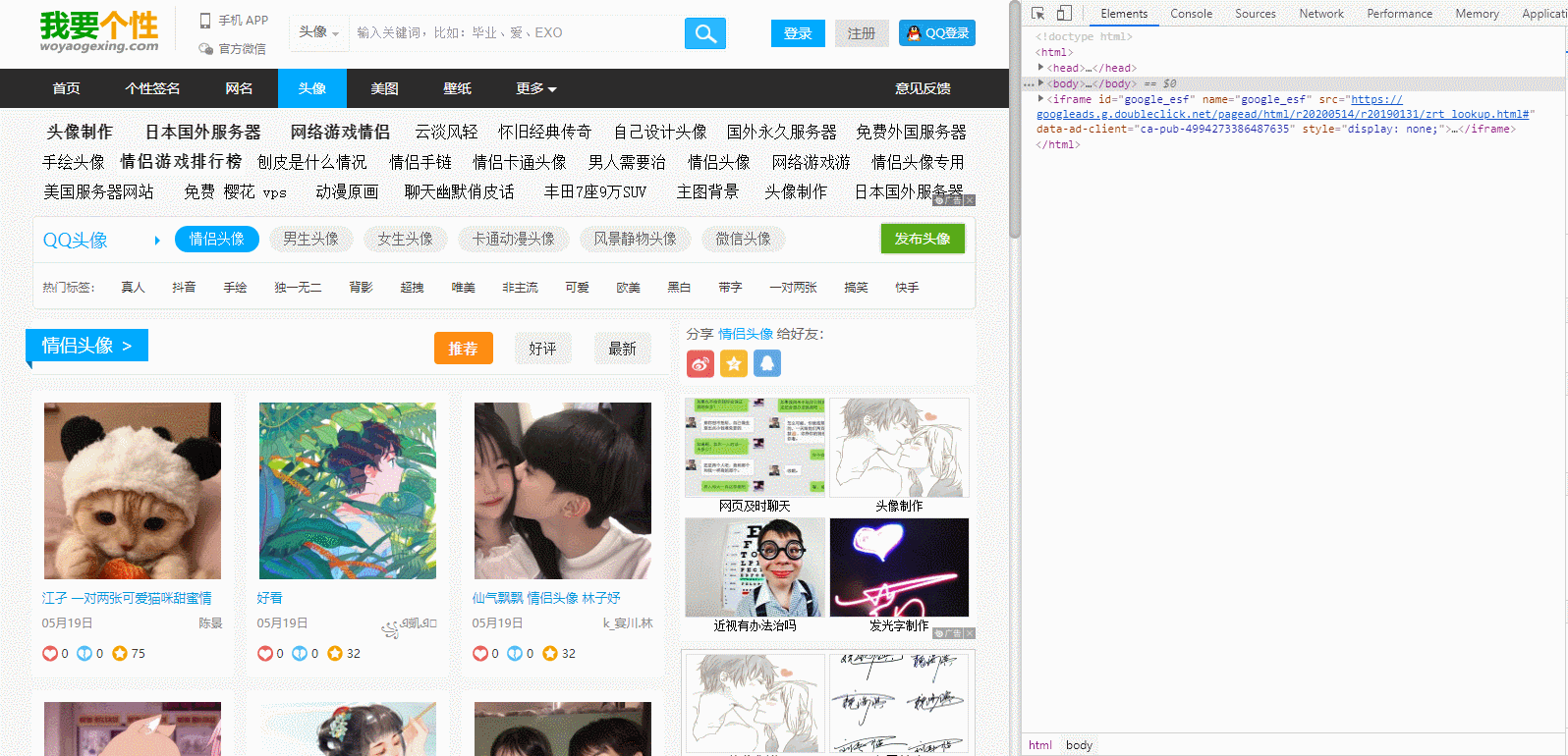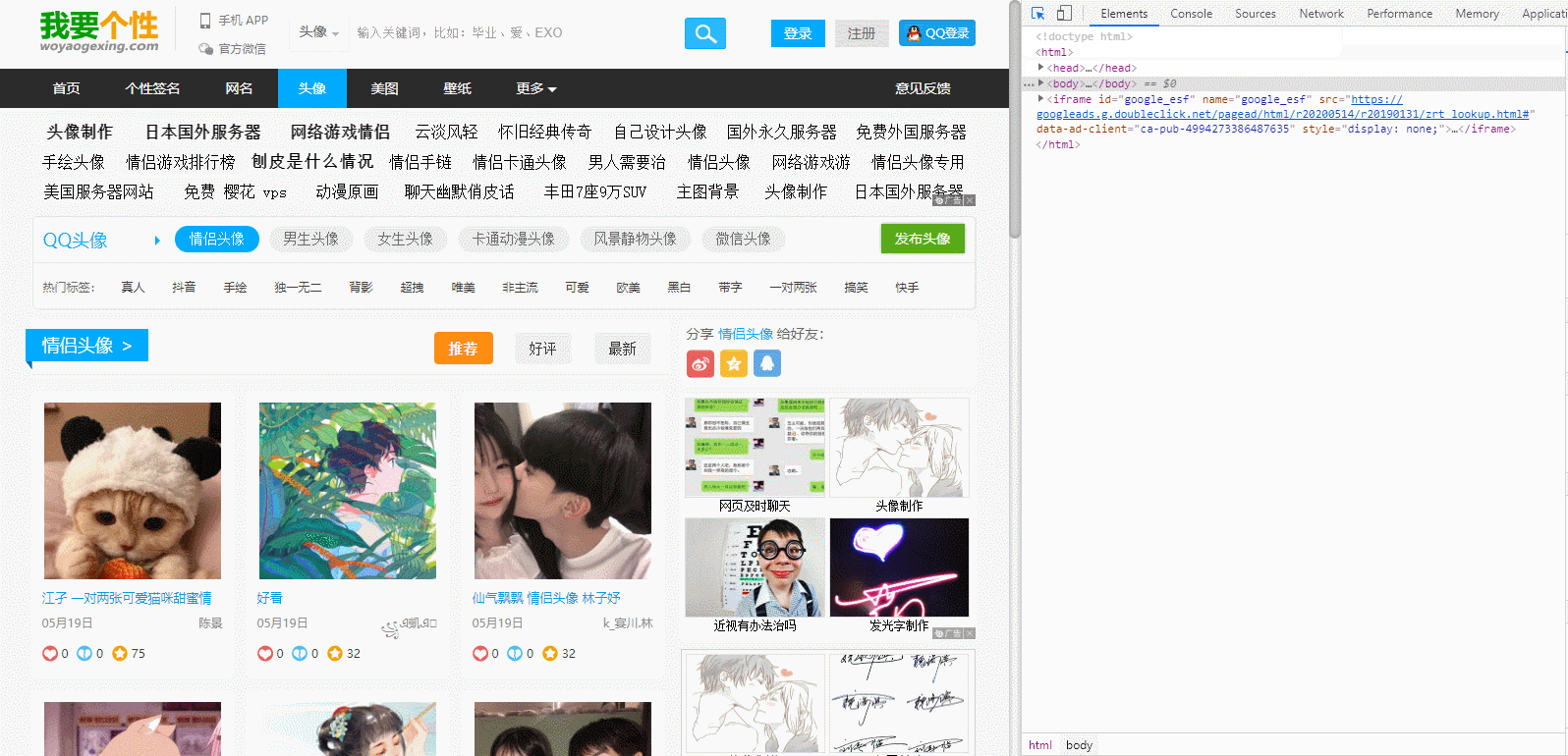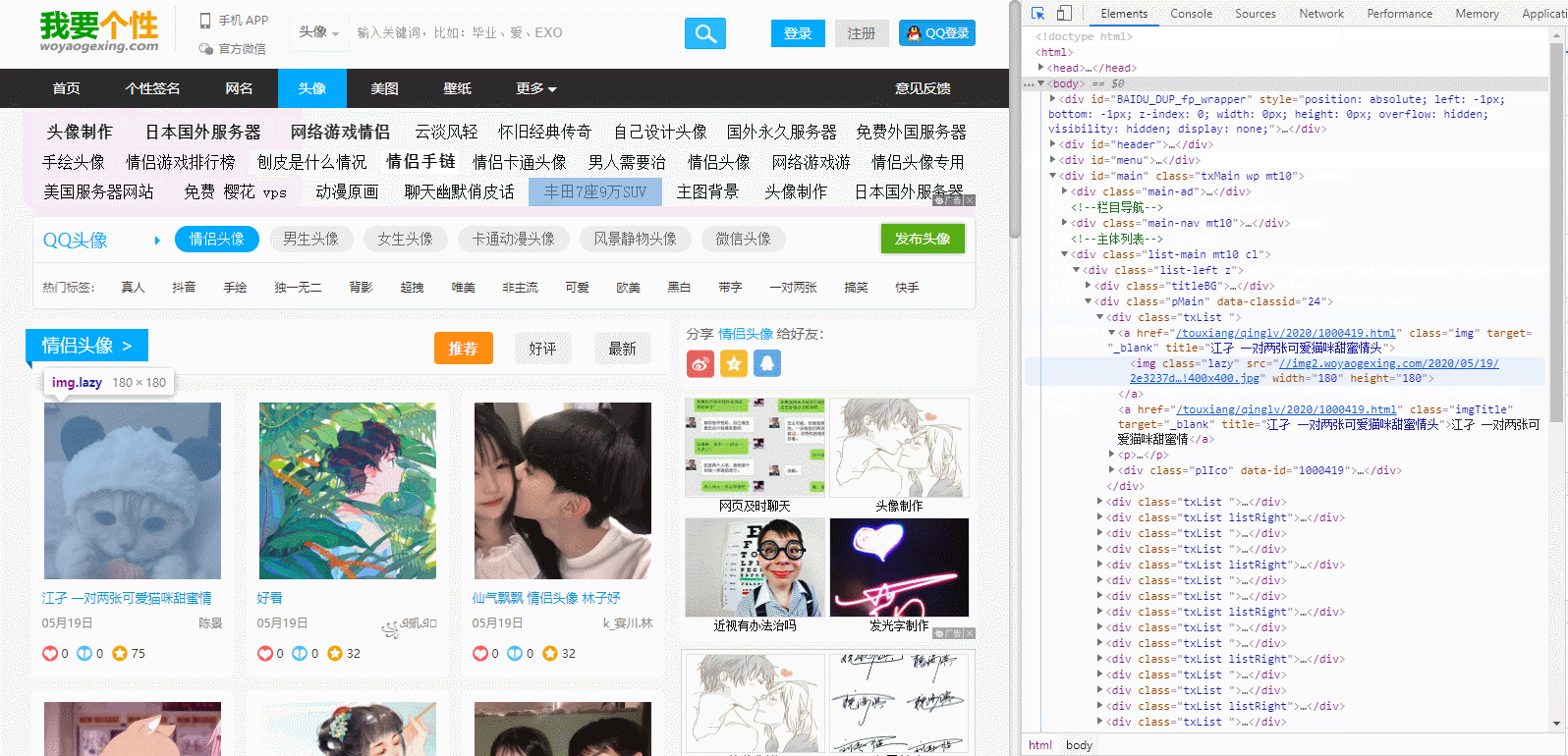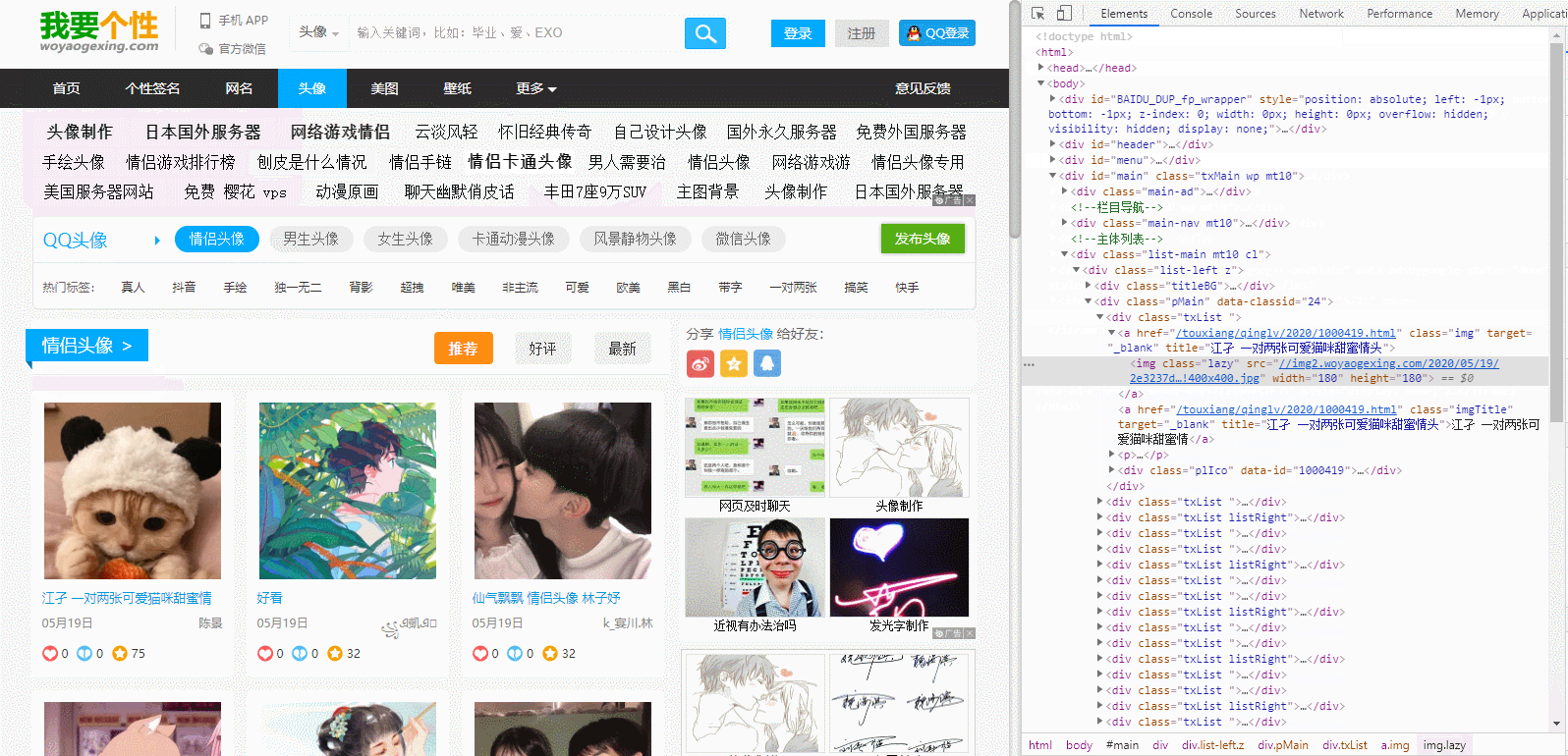
二、获取想要的url跳转,点击右侧检查页面左上角那个带箭头的图标,然后选中窗口页面的一个图片点击,右侧就可以定位到相应的html位置,href属性里面的数据就是我们需要匹配的跳转数据
divs = re.findall('<a href="(.*?)" class="img" target="_blank" title="(.*?)">', html)
得到的链接是:
[('/touxiang/qinglv/2020/1000686.html', '#沙雕#情头 望喜'), ('/touxiang/qinglv/2020/1000630.html', '今天在线蹲了我放总的新剧❤又是爱放姐的一天情头一波'), ('/touxiang/qinglv/2020/1000419.html', '江孑 一对两张可爱猫咪甜蜜情头'), ('/touxiang/qinglv/2020/1000405.html', '好看'), ('/touxiang/qinglv/2020/1000369.html', '仙气飘飘 情侣头像 林子妤')]
三、访问跳转链接
url_pic = "https://www.woyaogexing.com" +url_title_tuple[0]
html_pic = requests.get(url_pic, headers=headers).content.decode("utf-8")
这个链接得到的数据就是单张图片的信息了,可以按照二的方法定位到图片

可以看到src里面已经有图片的下载链接了。
四、访问图片下载链接并保存
a. 匹配下载链接
imgs = re.findall('<img class="lazy" src="(.*?)" width="200" height="200" />', html_pic)
b. 访问下载链接
img_data = requests.get(img_url, headers=headers).content
c. 保存数据
with open(img_path, "wb") as f: f.write(img_data)
至此,图片已经下载下来了。
play.py


#!/usr/bin/env python # _*_ coding: UTF-8 _*_ """================================================= @Project -> File : Operate_system_ModeView_structure -> play.py @IDE : PyCharm @Author : zihan @Date : 2020/5/19 20:27 @Desc :获取情侣头像 =================================================""" import requests import re import os headers = { 'user-agent': "自己在浏览器中复制", } def get_matched_data(url, matched_string): html = requests.get(url, headers=headers).content.decode("utf-8") result = re.findall(matched_string, html) return result def save_data(img, title): img_url = "http:" + img img_data = requests.get(img_url, headers=headers).content img_path = "./picture/" + title + "/" + str(img.split("/")[-1]) print("正在下载:", str(img)) with open(img_path, "wb") as f: f.write(img_data) print(str(img.split("/")[-1]) + "下载完毕") def main(): url_enter = "https://www.woyaogexing.com/touxiang/qinglv/" match_url_title = '<a href="(.*?)" class="img" target="_blank" title="(.*?)">' url_title_tuple_list = get_matched_data(url_enter, match_url_title) for url_title_tuple in url_title_tuple_list: url_pic = "https://www.woyaogexing.com" + url_title_tuple[0] title_pic = url_title_tuple[1] title = re.sub("[/]+", "_", title_pic) if not os.path.exists("./picture/" + title): os.mkdir("./picture/" + title) match_img_src = '<img class="lazy" src="(.*?)" width="200" height="200" />' img_list = get_matched_data(url_pic, match_img_src) for img in img_list: save_data(img, title) if __name__ == '__main__': main()
Ok.