explain命令可以模拟优化器执行sql查询语句,从而知道mysql是如何处理你的sql语句的,并用于分析你的查询语句或是表结构的性能瓶颈。
- 使用方式为:explain+sql语句
- 通过explain可以得到
- 表的读取顺序
- 数据读取操作的操作类型
- 可用索引
- 实际使用索引
- 表间引用
- 每张表被优化器查询的行数
- 执行计划包含的信息有 id、select_type、table、type、possible_keys、key、key_len、ref、rows、filtered、Extra
eg如下
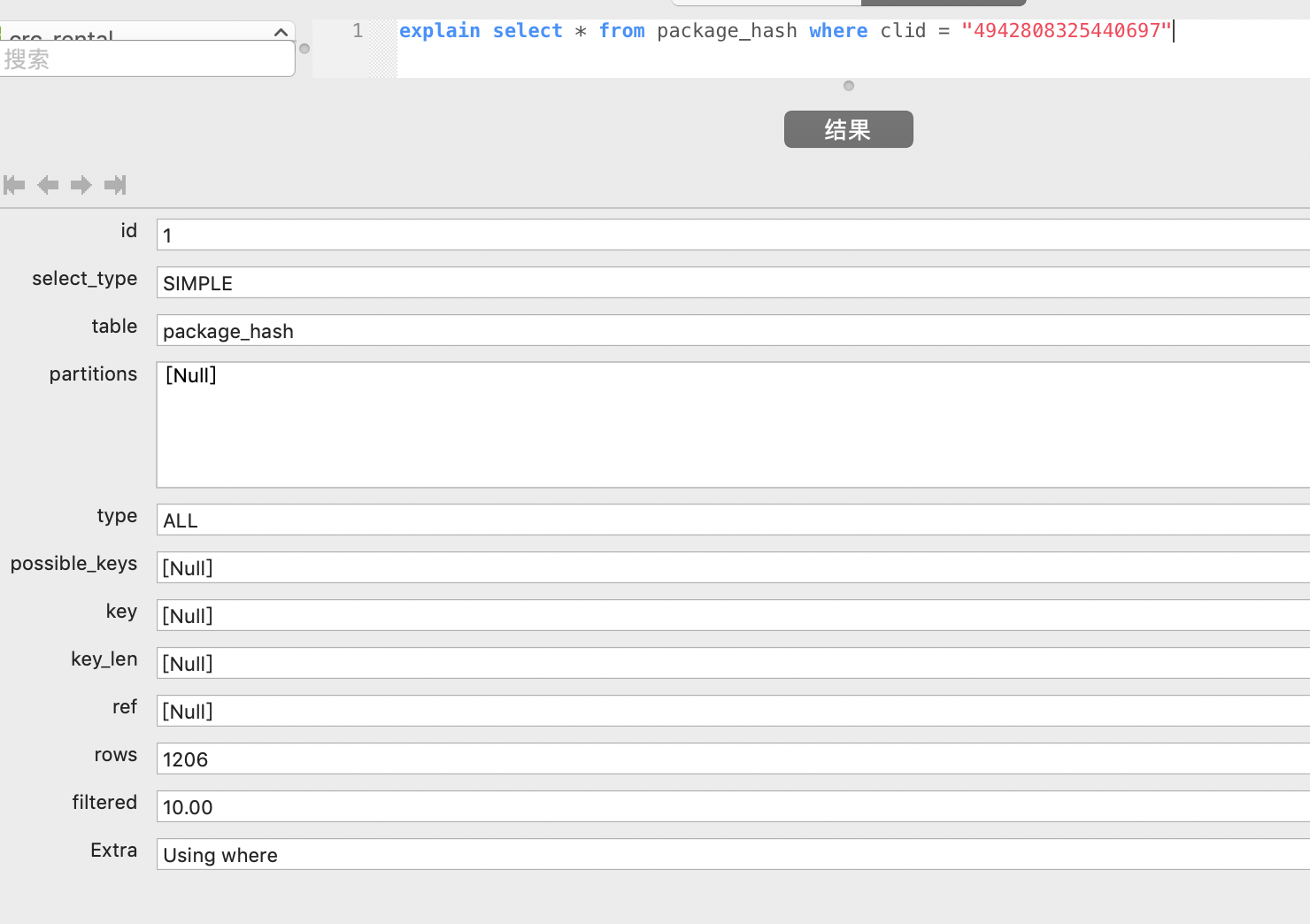
分析以上几个字段的含义
id
表示查询语句的顺序,如果行引用其他行的并集结果,则值可为null。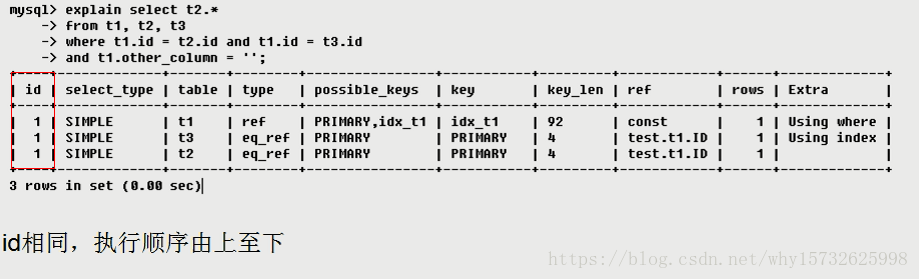
- id相同,执行顺序由上而下
- id不同,id值越大优先级越高,越被优先执行
select_type
表示查询使用的类型,值有:
- SIMPLE 简单查询,查询中不包含子查询或者union
- explain select * from test where id = 1000;
- PRIMARY 查询中有子部分,最外层查询为PRIMARY
- explain select * from (select * from test where id = 1000) a;
- SUBQUERY select或where里包含了子查询
- explain select * from test where id = (select id from test where id = 1000);
- DRIVED from中包含了子查询,该子查询就是DERIVED(衍生)(子查询结果放在临时表中)
- explain select * from (select * from test2 where id = 1000)a;
- UNION union中的第二个或随后的select查询,不依赖于外部查询的结果集
- explain select * from test where id = 1000 union all select * from test2 ;
- DEPENDENT UNION union中的第二个或随后的select查询,依赖于外部查询的结果集
- explain select * from test where id in (select id from test where id = 1000 union all select id from test2) ;
- UNION RESULT 从union表获取结果的select
- explain select * from test where id = 1000 union all select * from test2 ;
table
输出行所引用的表名
type
表示访问类型,最好到最差排序是 system > const > eq_ref > ref > range > index > a
- system 表只有一行,是const的一个特例
- explain select * from (select * from test2 where id = 1000)a;
- const 表示通过索引一次就找到了,const用于比较primary key 或者unique索引,速度非常快。
- explain select * from test where id =1 ;
- eq_ref 唯一性索引扫描,每个索引键,表中只有一条记录与之匹配。主键或唯一索引扫描。
- explain select * from test,test2 where test.com_key=test2.com_key;
- ref 非唯一性索引扫描,就是一种索引访问,可能找到多个符合条件的行,属于查找和扫描的混合体。
- select * from test2 where name = "44444";
- ref_or_null 类似ref,添加了可以专门搜索null的行
- select * from test2 where name = "44444" or name is null;
- range 只检索给定范围的行,一般在where语句中出现between、<、>、in等查询,这种范围扫描索引比全表扫描好。
- select * from test2 where id > 44444;
- index 读全表,全遍历索引树,比all快,因为索引文件通常比数据文件小。(index从索引读,all从硬盘读)
- explain select count(*) from test
- index_merge 该访问类型使用了索引合并优化方法,可以考虑把单列索引换为组合索引,效率更高。
- explain select * from test where id = 1 or bnet_id = 1;
- all 扫全表,遍历全表以找到匹配的行。
- explain select * from test where textd = '&&&DDDDD';
possible_keys
显示可能应用在这张表中的索引,一个或多个,查询涉及到的字段上若存在索引,则索引将被列出,但不一定被查询实际使用。
key
实际使用的索引,如果为null,则没有使用索引(可能是没建立索引或索引失效)
key_len
标识索引中使用的字节数,可通过该列计算查询中使用的索引的长度,长度越短越好。值为索引字段的最大可能长度,非实际使用长度(根据表定义计算而得)。
ref
显示索引的哪一列被使用了,最好是个常数。
rows
根据表统计信息及索引选用情况,大致估算出找到所需记录所需要读取的行数,值越小越好。
Extra
不合适在其他列中显示但十分重要的额外信息。
参考:https://blog.csdn.net/why15732625998/article/details/80388236、https://juejin.im/post/5d75abcb6fb9a06b0d7cabb3