python2和python3区别
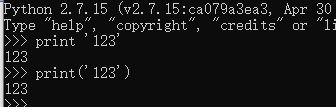
python2中,print 是语句 :用法 ---->print '***'
python3中,print 是函数:用法----->print('***')
不过python2.6和python2.7是允许使用部分python3的语法和函数的。比如print函数就可以
xange() range()
python2 :xrange()函数用法与range完全相同,只是返回的是一个"xrange object"对象(生成器),而非数组list。
python3:range生成的是数组,等差数列。python3中已经没有了xrange。
区别如下:
1.range和xrange都是在循环中使用,输出结果一样。
2.range返回的是一个list对象,而xrange返回的是一个生成器对象(xrange object)。
3.xrange则不会直接生成一个list,而是每次调用返回其中的一个值,内存空间使用极少,因而性能非常好。
input() raw_input()
python2:
input():只接受数字的输入,返回数字类型(int,float),对待数字输入时具有自己的特性。
raw_input():将所有输入看作是字符串对待,返回的数据类型为字符串。
python3:
input():整合了上述两种,接收的输入全部返回为字符串类型。
赋值(is / id )
li1 = [1,2,3] li2 = li1#li1 的值赋给li2,即li2也指向li1指向的内存中的[1,2,3] print(li1 is li2)# is print(id(li1))# id print(id(li2))

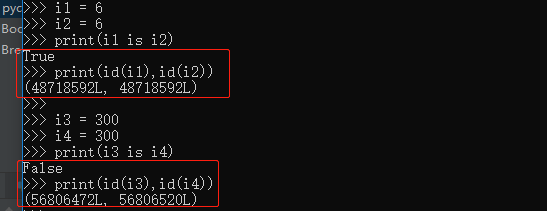
拓展:小数据池的概念:-5~256,仅限数字和字符串
i1 = 6 i2 = 6 print(i1 is i2) print(id(i1),id(i2)) i3 = 300#在终端命令行里面进行操作,pycharm值还是一样 i4 = 300 print(i3 is i4) print(id(i3),id(i4))

仅限数字和字符串
数字范围:-5~256,
字符串:1,不能含有特殊字符
2,s*20是同一地址,21之后不一致,s为单字符
编码 encode
各种编码之间的二进制不能互相识别,会出现乱码。
文件存储,传输,不能是unicode,(存储空间太大,英文两个字节,中文四个字节)
python2
字符串在python内部的表示是unicode编码,因此,在做编码转换时,通常需要unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转换成(解码)unicode编码。str.decode('gbk'),表示将gbk编码的字符串str解码成unicode编码。
encode的作用是将unicode编码的字符串转换成(编码)其他编码。str.encode('utf-8'),表示将unicode编码的字符串str编码成utf-8编码。
python3
文本总是用unicode进行编码,以str类型表示;而二进制数据以bytes类型表示。
Python3 中没有 decode 方法,就无法将其他编码的字符串解码,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,
所以就要用bytes的decode来解码,然后再编码成其他编码
这个 bytes 对象可以由 str.encode() 来编码返回
即bytes类型可由str.encode()返回生成,再由bytes的decode方法解码成其他编码方式的str类型。
s = 'asdf' s1 = s.encode('utf-8') print(s1,type(s1)) s2 = '汉字' s3 = s2.encode()#默认为 utf-8,看结果,两个汉字,共六个字节。 print(s3,type(s3))

s4 = s3.decode()#解码,bytes类型才能decode print(s4)

个人参考:https://www.cnblogs.com/abclife/p/7445222.html
decode() 方法以指定的编码格式解码 bytes 对象。默认编码为 'utf-8'。
pass