服务雪崩效应
基础服务的故障导致级联故障,进而造成了整个分布式系统的不可用,这种现象被称为服务雪崩效应。服务雪崩效应描述的是一种因服务提供者的不可用导致服务消费者的不可用,并将不可用逐渐放大的过程。
服务雪崩效应形成的原因
- 服务提供者不可用
- 硬件故障
- 程序Bug
- 缓存击穿
- 用户大量请求
- 重试加大流量
- 用户重试
- 代码逻辑重试
- 服务调用者不可用
- 同步等待造成的资源耗尽
服务雪崩的应对策略
- 流量控制
- 网关限流
- 用户交互限流
- 关闭重试
- 改进缓存模式
- 缓存预加载
- 同步改为异步刷新
- 服务自动扩容
- AWS的auto scaling
- 服务调用者降级服务
- 资源隔离
- 对依赖服务进行分类
- 不可用服务的调用快速失败
打铁还需自身硬,本篇文章不展开论述各种应对策略,主要探讨微服务自身如何来保护自己,避免奔溃?即微服务如何进行容错设计?
容量设计在生活中经常见到,每家每户都有保险丝,用电超负荷了,就会跳闸。微服务的容错组件Hystrix就吸收了这些思想。
Hystrix
Hystrix [hɪst'rɪks]的中文含义是豪猪科动物,如下图所示, 因其背上长满了刺,而拥有自我保护能力.
Netflix的 Hystrix 是一个帮助解决分布式系统交互时超时处理和容错的类库, 它同样拥有保护系统的能力.
![]()
Hystrix如何保护我们的应用?
How Does Hystrix Accomplish Its Goals?
- Wrapping all calls to external systems (or “dependencies”) in a HystrixCommand or HystrixObservableCommand object which typically executes within a separate thread (this is an example of the command pattern).(通过HystrixCommand封装外部系统的所有调用,它会在独立的线程中执行)即命令模式。
- Timing-out calls that take longer than thresholds you define. There is a default, but for most dependencies you custom-set these timeouts by means of “properties” so that they are slightly higher than the measured 99.5th percentile performance for each dependency.(简单说:修改超时时间的阈值,提高依赖的性能)
- Maintaining a small thread-pool (or semaphore) for each dependency; if it becomes full, requests destined for that dependency will be immediately rejected instead of queued up.(每个依赖维护一个小的线程池或者信号量,如果满了,请求调用依赖会被快速聚集而不是排队等待。)即资源隔离
- Measuring successes, failures (exceptions thrown by client), timeouts, and thread rejections.(测量成功率,失败率、超时次数、线程拒绝率)即服务监控的指标
- Tripping a circuit-breaker to stop all requests to a particular service for a period of time, either manually or automatically if the error percentage for the service passes a threshold.(当服务的错误率超过阈值时,通过手动或者自动的方式,对一定时间内特定的服务,采用链路中断器拒绝所有请求,)即熔断器、熔断机制
- Performing fallback logic when a request fails, is rejected, times-out, or short-circuits.(在请求失败、拒绝、超时、短路时执行回退逻辑)即请求回退
- Monitoring metrics and configuration changes in near real-time.(近实时监控指标和修改配置。)
下面主要展开讲述资源隔离、服务降级、服务熔断、请求合并以及服务监控等功能特性。
资源隔离
资源隔离--设计思想来源

货船为了进行防止漏水和火灾等风险的扩散,会将货仓分隔为多个隔离区域,这种资源隔离减少风险的方式被称为:Bulkheads(舱壁隔离模式).
官网关于资源隔离的举例如下:
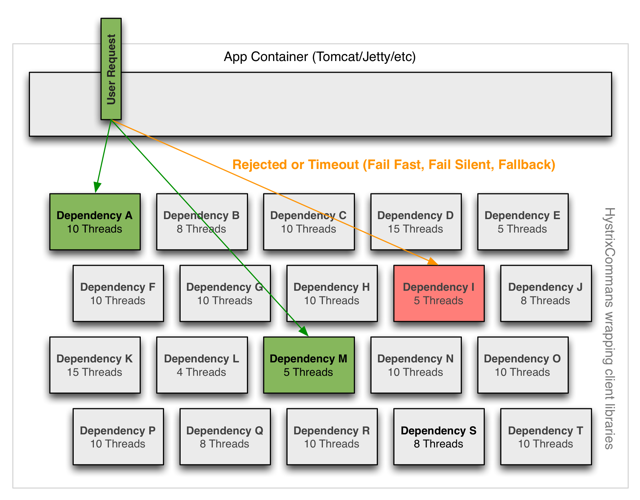
两种资源隔离模式
(1)线程池隔离模式:使用一个线程池来存储当前的请求,线程池对请求作处理,设置任务返回处理超时时间,堆积的请求堆积入线程池队列。这种方式需要为每个依赖的服务申请线程池,有一定的资源消耗,好处是可以应对突发流量(流量洪峰来临时,处理不完可将数据存储到线程池队里慢慢处理)
(2)信号量隔离模式:使用一个原子计数器(或信号量)来记录当前有多少个线程在运行,请求来先判断计数器的数值,若超过设置的最大线程个数则丢弃改类型的新请求,若不超过则执行计数操作请求来计数器+1,请求返回计数器-1。这种方式是严格的控制线程且立即返回模式,无法应对突发流量(流量洪峰来临时,处理的线程超过数量,其他的请求会直接返回,不继续去请求依赖的服务)
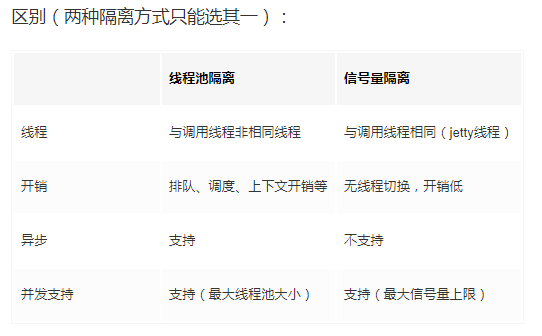
官网对比线程池与信号量
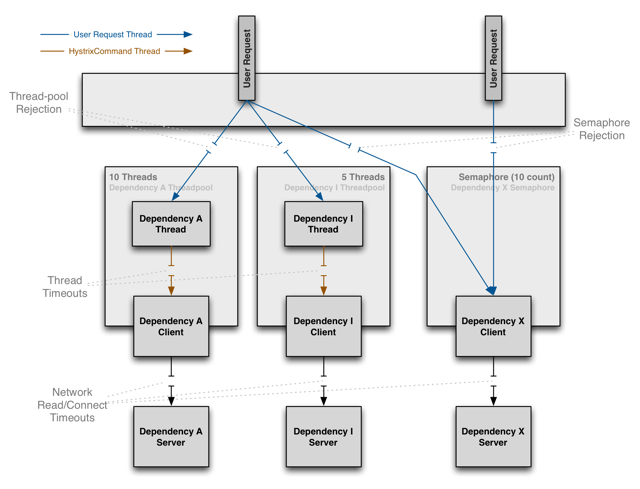
什么时候用线程池 or 信号量?
默认使用线程池
如果不涉及远程RPC调用(没有网络开销),比如访问内存缓存,则使用信号量来隔离,更为轻量,开销更小。
The Netflix API processes 10+ billion Hystrix Command executions per day using thread isolation. Each API instance has 40+ thread-pools with 5–20 threads in each (most are set to 10).
Netflix API每天使用线程隔离处理10亿次Hystrix Command执行。 每个API实例都有40多个线程池,每个线程池中有5-20个线程(大多数设置为10个)
@HystrixCommand(fallbackMethod = "stubMyService",
commandProperties = {
@HystrixProperty(name="execution.isolation.strategy", value="SEMAPHORE")
}
)
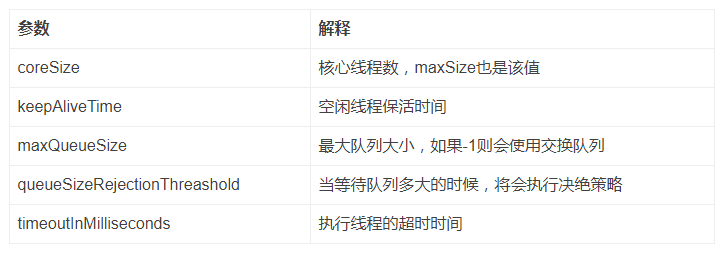
线程池核心配置:
服务降级、回退
降级就是当依赖的服务产生故障时,把产生故障的丢了,换一个轻量级的方案(比如返回一个固定值),是一种退而求其次的方法。比如微信刚上线红包功能时,过年那天大家都在发红包,很多人都会看到微信会弹出一个相同的页面,这个就是服务降级的使用,当服务不可用时,返回一个静态值(页面)。
Hystrix 6种降级回退模式:
- Fail Fast 快速失败
- Fail Silent 无声失败
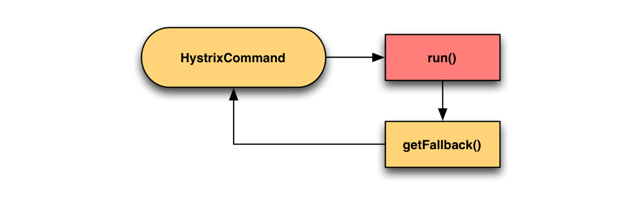
- Fallback: Static 返回默认值
- Fallback: Stubbed 自己组装一个值返回
- Cache via Network
Sometimes if a back-end service fails, a stale version of data can be retrieved from a cache service such as memcached. 利用远程缓存
通过远程缓存的方式。在失败的情况下再发起一次remote请求,不过这次请求的是一个缓存比如redis。由于是又发起一起远程调用,所以会重新封装一次Command,这个时候要注意,执行fallback的线程一定要跟主线程区分开,也就是重新命名一个ThreadPoolKey。
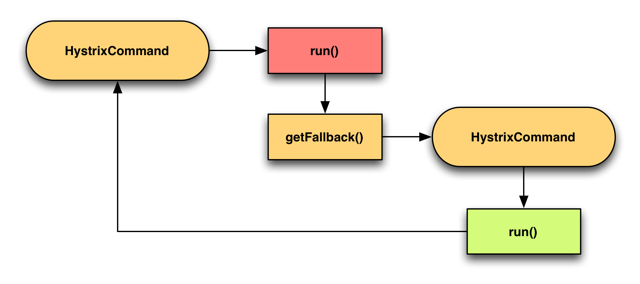
- Primary + Secondary with Fallback 主次方式回退(主要和次要)
这个有点类似我们日常开发中需要上线一个新功能,但为了防止新功能上线失败可以回退到老的代码,我们会做一个开关比如(使用zookeeper)做一个配置开关,可以动态切换到老代码功能。那么Hystrix它是使用通过一个配置来在两个command中进行切换。
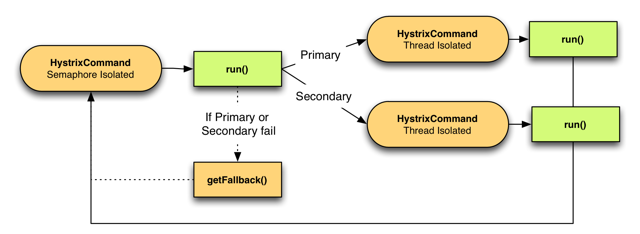
回退的处理方式也有不适合的场景:

以上几种情况如果失败,则程序就要将错误返回给调用者。
熔断器
熔断器就像家里的保险丝,当电流过载了就会跳闸,不过Hystrix的熔断机制相对复杂一些。
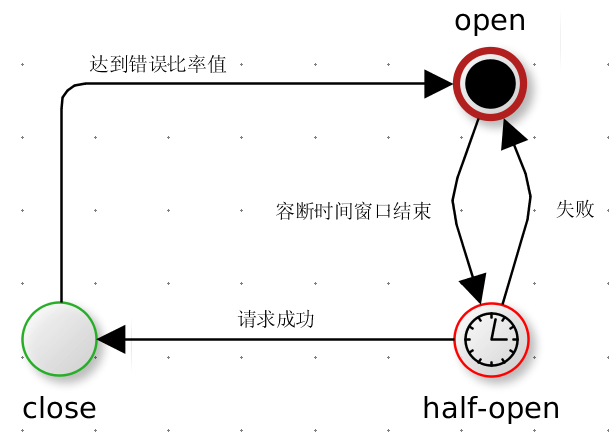

这两个图来自于两个博客,都是同一个意思。
服务的健康状况 = 请求失败数 / 请求总数.
熔断器开关由关闭到打开的状态转换是通过当前服务健康状况和设定阈值比较决定的.
- 当熔断器开关关闭时, 请求被允许通过熔断器. 如果当前健康状况高于设定阈值, 开关继续保持关闭. 如果当前健康状况低于设定阈值, 开关则切换为打开状态.
- 当熔断器开关打开时, 请求被禁止通过.
- 当熔断器开关处于打开状态, 经过一段时间后, 熔断器会自动进入半开状态, 这时熔断器只允许一个请求通过. 当该请求调用成功时, 熔断器恢复到关闭状态. 若该请求失败, 熔断器继续保持打开状态, 接下来的请求被禁止通过.
熔断器的开关能保证服务调用者在调用异常服务时, 快速返回结果, 避免大量的同步等待. 并且熔断器能在一段时间后继续侦测请求执行结果, 提供恢复服务调用的可能.
熔断器工作流程图
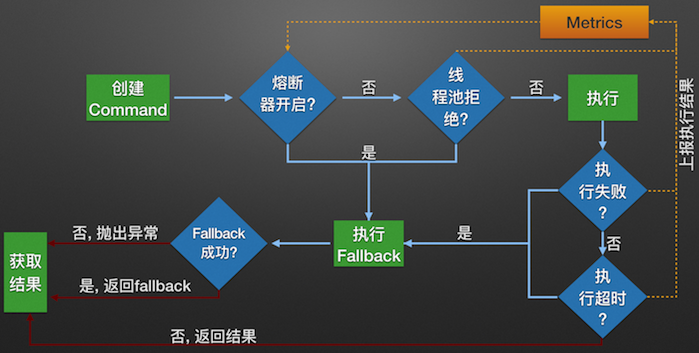
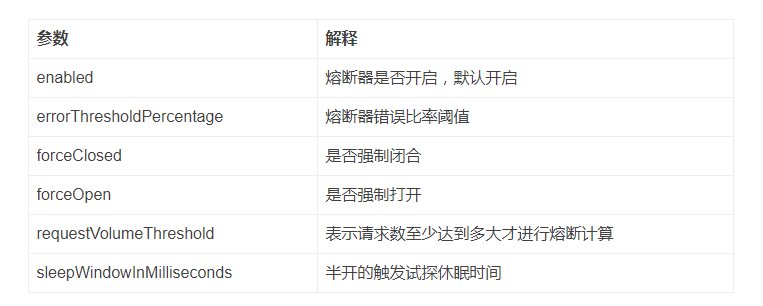
熔断器核心配置:
Hystrix工作流程图
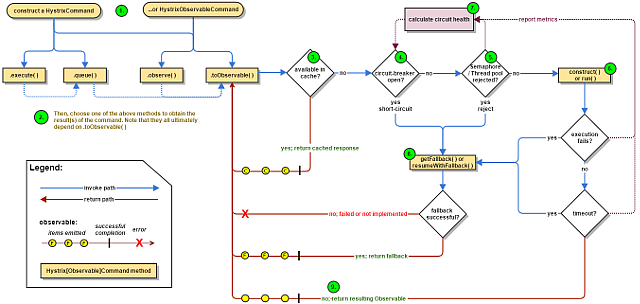
上图是官网原图,下图是中文版:
Hystrix sequence diagram
请求合并
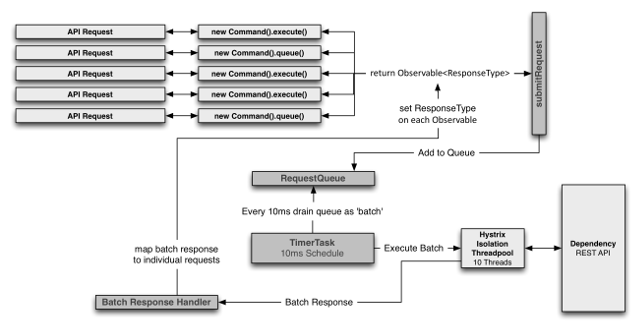
-
由于请求合并器的延迟时间窗会带来额外开销
服务监控
Hystrix还提供给我们一个监控功能Hystrix-dashboard,可以直接使用其开源项目进行配置,就能实时的观察我们的服务调用情况。
如果是集群,通过turbine进行监视。
监控如下:

命令模式
Hystrix采用命令模式,将上述这些功能特性植入我们的业务代码,值得学习。
参考文献
tips:本文属于自己学习和实践过程的记录,很多图和文字都粘贴自网上文章,没有注明引用请包涵!如有任何问题请留言或邮件通知,我会及时回复。