一.流的基本概念
在java.io包中,File类是唯一一个与文件本身有关的程序处理类,但是File类只能操作文件本身,而不能操作文件内容,IO操作的核心意义在于输入和输出操作.而对于程序而言,输入和输出可能来自不同的环境:
--通过电脑连接服务器上进行浏览的时候,实际上此时客户端发出了一个信息,服务器接收到此信息后作出了回应处理,在整个程序之中,对于服务器以及客服端来说,传递的实质上就是一种数据流的处理形式,而所谓的数据流指的就是字节数据.
--而对于这类流的处理形式,在java.io包中提供有两类支持:
字节处理流: OutputStream(输出字节流),InputStream(输入字节流)
字符处理流:Writer(输出字符流),Reader(输入字符流)
--以上四个类都是Abstract抽象类
--所有的流操作都应该采用如下统一的步骤进行,下面以文件处理的流程为例:
如果现在进行文件的读写操作,则一定要挺过File类找到一个文件的输入输出路径;
通过字节流或字符流的子类来完成父类对象的实例化;
利用字节流或字符流中的方法实现数据的输入与输出操作;
流的操作属于资源操作,资源操作必须进行关闭处理;
二. 字节输出流:OutputStream
字节的数据以Byte类型为主实现的操作,在进行字节内容输出的时候可以使用OutputStream类完成,这个类的基本定义如下:
public abstract class OutputStream
extends Object
implements Closeable, Flushable
--首先发现这个类继承了两个接口,于是基本的对应关系如下:
Closeable:首先需要知道OUtputStream是在JDK1.0时就已经存在的,而Closeable则是在JDK1.5的时候才提出的,而Closeable有继承了AutoCloseable,提供了close()方法
Flushable:此类也是在JDK1.5时提供的,提供了flush()方法
--OutputStream类定义的是公共的输出操作标准,而在这个操作标准里面一共定义有三个内容输出的方法:
1.输出单个字节数据public abstract void write(int b) throws IOException;
2.输出一组字节数据public void write(byte b[]) throws IOException 这也是使用最多的方法
3.输出部分字节数据public void write(byte b[], int off, int len) throws IOException
--但是需要注意的一个核心问题是:OUtputStream类毕竟是一个抽象类,而这个抽象类如果要想获得实例化对象,应该通过子类实例的向上转型完成,如果说现在要进行的是文件的处理操作,可以选用FileOutputStream子类:因为最终都要进行向上转型的处理操作,那么对于此时的FileOUtputStream子类核心的关注点就可以放在构造方法上了:
FileOutputStream(File file)
创建文件输出流以写入由指定的 File对象表示的文件。 覆盖
FileOutputStream(File file, boolean append)
创建文件输出流以写入由指定的 File对象表示的文件。 追加
--范例:使用OUtputStream类实现内容的输出
1 public class MyInputStreamReaderDemo {
2 public static void main(String[] args) throws IOException {
3 File file = new File("d:" + File.separator + "java_test" + File.separator + "demo01.txt");
4 if (!file.getParentFile().exists()) {
5 file.getParentFile().mkdirs(); //创建父目录
6 }
7 OutputStream output = new FileOutputStream(file);
8 String str = "www.baidu.com"; //准备要输出的内容
9 output.write(str.getBytes()); //将字符串改变为字节数组
10 output.close(); //关闭资源
11 }
12 }
--本程序采用了最为标准的形式完成了输出的操作处理,并且在整体的处理之中,只是创建了文件的父目录,并没有创建文件,可以发现文件会被自动创建
--由于OUtputStream的子类也属于AutoCloseable接口的子类,对于close()的方法也可以简化使用
1 public class MyInputStreamReaderDemo {
2 public static void main(String[] args) throws IOException {
3 File file = new File("d:" + File.separator + "java_test" + File.separator + "demo01.txt");
4 if (!file.getParentFile().exists()) {
5 file.getParentFile().mkdirs(); //创建父目录
6 }
7 try (OutputStream output = new FileOutputStream(file,true)) {
8 String str = "www.baidu.com
"; //准备要输出的内容
9 output.write(str.getBytes()); //将字符串改变为字节数组
10 } catch (IOException e) {
11 e.printStackTrace();
12 }
13 }
14 }
--是否使用自动的关闭取决于项目的整体结构,另外还需要知道的是,在整个程序中最终是输出了一组的字节数据,但是不要忘记OutputStream中定义的输出方法一共有三个,只不过其余的两个使用的机会较少.
三.InputStream字节输入流
与OutputStream类对应的一个流就是字节输入流,InputStream类主要实现的就是字节数据读取,该类定义如下:
public abstract class InputStream implements Closeable,在InputStream类中定义有如下的几个核心方法:
读取单个字节数据:public abstract int read()throws IOException
读取一组字节数据:public int read(byte[] b) throws IOException 返回的是读取的个数,如果数据已经读取到底了,则返回-1
读取一组字节数据的部分内容:public int read(byte b[], int off, int len) throws IOException
--InputStream类属于抽象类,这是应该依靠他的子类来实例化对象,可以使用FileInputStream类完成:
1 public class MyInputStreamDemo {
2 public static void main(String[] args) throws IOException {
3 File file = new File("d:" + File.separator + "java_test" + File.separator + "demo01.txt");
4 InputStream inputStream = new FileInputStream(file);
5 byte [] data = new byte[1024]; //开辟一个缓冲区读取数据
6 int len = inputStream.read(data);//读取数据,数据全部保存在字节数组之中
7 System.out.println("读取到的数据: " + new String(data,0,len));
8 inputStream.close();
9 }
10 }
--对于字节输入流来说,最为麻烦的问题就在于:使用Read方法读取的时候,只能以字节数据为主进行接收
--特别需要注意的是从JDK1.9开始,在InputStream类中增加了一个readAllBytes()方法,如果当前要读取的内容很大,那么使用该方法读取的时候将会导致程序的崩溃.
四.字符输出流:Writer
使用OUtputStream字节输出流进行数据输出的时候使用的都是字节类型的数据,而很多的情况下字符串的输出时比较方便的,,所以对于java.io包而言,在JDK1.1的时候又推出了字符输出流Writer,这个类的定义如下:
since JDK1.1 :public abstract class Writer implements Appendable(JDK1.5), Closeable(JDK1.5), Flushable(JDK1.5)
--在Writer类里面提供有许多的输出操作方法:重点来看两个:
输出字符数组:public void writer(char[] cbuf) throw IOExpection
输出字符串: public void write(String str) throws IOExpection:
--范例:使用Writer输出
1 public class MyWriterDemo {
2 public static void main(String[] args) throws IOException {
3 File file = new File("d:" + File.separator + "java_test" + File.separator + "demo01.txt");
4 if(!file.getParentFile().exists()){ //保证父目录存在
5 file.getParentFile().mkdirs(); //创建父目录
6 }
7 Writer writer = new FileWriter(file);
8 String str = "要输出的内容";
9 writer.write(str);
10 writer.append("
追加输出内容");
11 writer.close();
12 }
13 }
--使用Writer输出的最大优势在于可以直接利用字符串完成,Writer是字符流,字符处理的优势在于中文数据上
五.字符输入流:Reader
Reader是实现字符输入流的一种类型,其本身属于一个抽象类,这个类的定义如下:
since JDK1.1:public abstract class Reader implements Readable(JDK1.5), Closeable(JDK1.5)
--Reader类并没有像Writer类一样提供有整个字符串的输入处理操作,只能够利用字符数组来实现接收:
1 public class MyReaderDemo {
2 public static void main(String[] args) throws IOException {
3 File file = new File("d:" + File.separator + "java_test" + File.separator + "demo01.txt");
4 if (file.exists()) {
5 Reader reader = new FileReader(file);
6 char data[] = new char[1024];
7 int len = reader.read(data);
8 System.out.println("读取到的内容: " + new String(data, 0, len));
9 reader.close();
10 }
11 }
12 }
--字符流读取的时候只能按照数组的形式来实现处理操作
六.字节流与字符流的区别
通过一系列的分析已经清楚了字节流与字符流的基本操作,但是对于这两类流依然存在区别:
--在输出的处理操作中:
--在使用OutputStream和Writer输出的时候都使用了close()来关闭输出流,在使用OutputStream进行输出的时候,发现如果没有使用close()方法关闭输出流内容依然可以实现正常的输出,但是Writer类进行输出的时候,如果不关闭(不使用close()方法关闭输出流),那么将无法看到输出的内容.jiuqiyuanying,是因为Writer使用到了缓冲区,在调用close()方法的时候实际上会出现有强制刷新缓冲区的情况,所以这个时候会将内容进行输出,所以此时如果在不关闭的情况要将全部的内容输出,可以使用flush()方法,并强制性清空.
--字节流在进行处理的时候不会使用到缓冲区,而字节流则会使用到缓冲区,另外使用缓冲区的字符流更加适合于进行中文数据的处理,所以在程序的开发之中,如果涉及到中文信息的输出,一般都可以选用字符流处理,但是从另一个方面来讲,字节流和字符流的基本处理形式是相似的,由于IO很多情况下都是进行数据的传输使用(二进制),所以在进行数据传输时以字节流为主.
七.转换流
所谓的转换流指的是可以实现字节流与字符流操作的功能转换,例如:进行输出的时候OutputStream需要将内容变为字节数字后才能输出,而Writer可以直接输出字符串,这一点是方便的,所以很多时候就认为需要提供有一种转换的机制,来实现不同流流行的转换机制:
--在java.io包中,提供有两个类:InputStreamReader,OutputStreamWriter:
--OutputStreamWriter的定义结构:public class OutputStreamWriter extends Writer
构造方法:public OutputStreamWriter(OutputStream out) 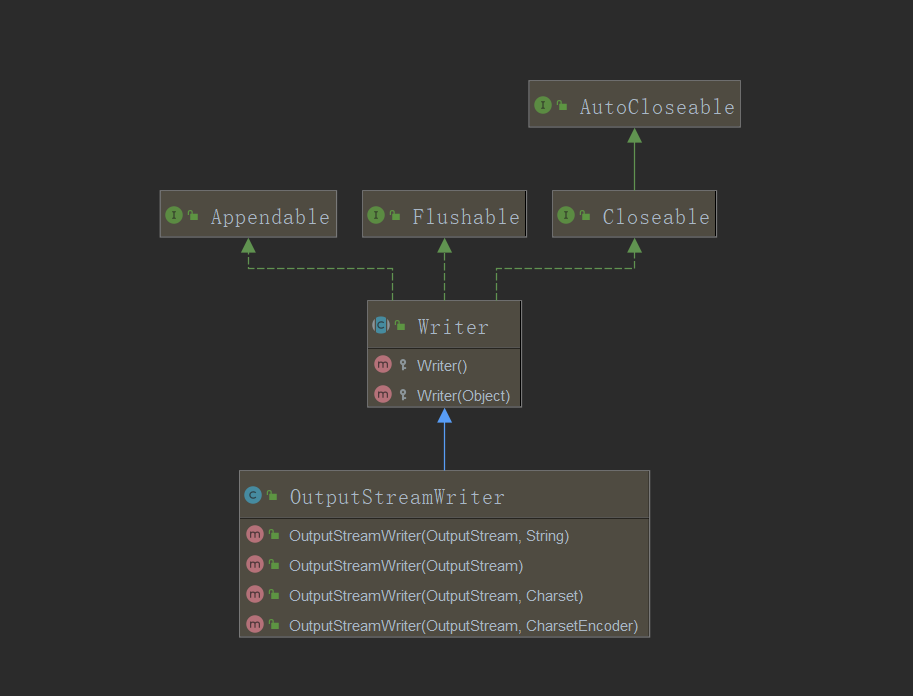
--InputStreamReader的定义结构:public class InputStreamReader extends Reader
构造方法:public InputStreamReader(InputStream in)
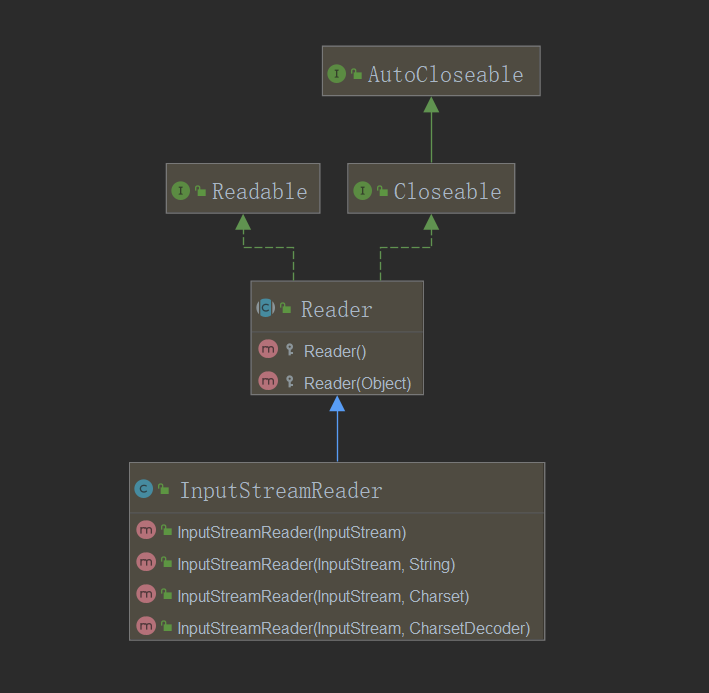
--通过类的继承结构和构造方法的研究,可以发现所谓的转换处理就是将接收到的字节流对象通过向上转型转变为字符流对象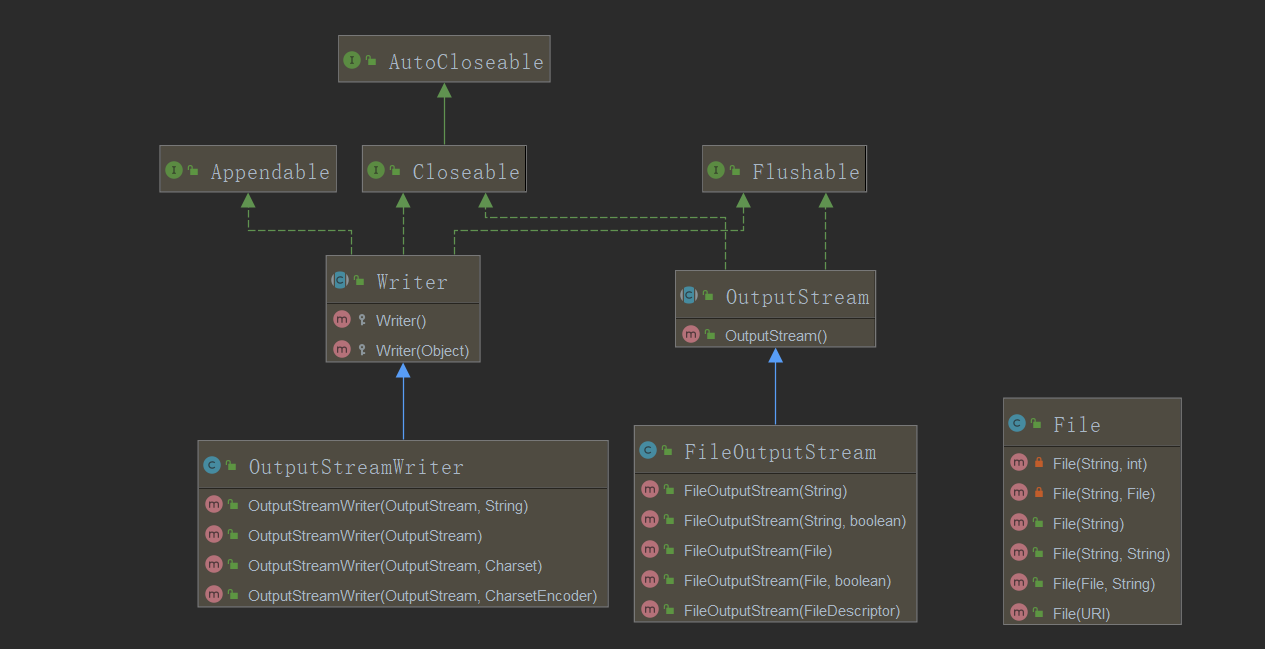
--范例:使用转换
1 public class MyOutputStreamWriterDemo {
2 public static void main(String[] args) throws IOException {
3 File file = new File("d:" + File.separator + "java_test" + File.separator + "demo01.txt");
4 if(!file.getParentFile().exists()){ //保证父目录存在
5 file.getParentFile().mkdirs(); //创建父目录
6 }
7 OutputStream outputStream = new FileOutputStream(file);
8 Writer writer = new OutputStreamWriter(outputStream);
9 writer.write("可以直接输入字符串"); //直接输出字符串,而且适用于中文
10 writer.close();
11 }
12 }
--转换流更多的时候是我们开发者去了解他(知道有这个功能),但同时更多的是要进行结构的分析处理.经过上述一些列的分析之后会发现OutputStream类有FileOutputStream直接子类,InputStream有FileInputStream直接子类,但是观察FileWriter,FileReader的继承关系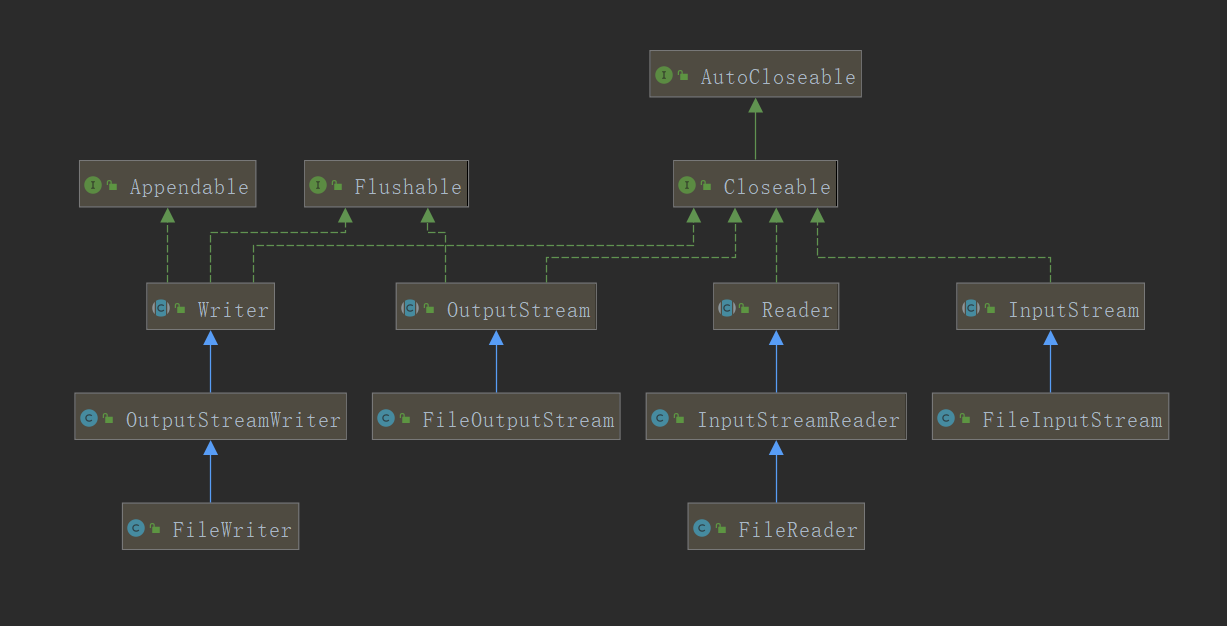
--可以发现Filewriter是OutputStreamWriter的子类,而OutputStreamWriter类有时Writer的直接子类,所以我们可以知道在程序定义的时候已经明确的指定了之间的转化关系,所以回到字符流为什么可以处理中文的问题上:简单的理解来说就是字符流可以做到对于数据的整体接收(存在缓存),在java的字符中,实际就是Unicode编码,使用Unicode(16进制编码),实际上所谓的缓存指的就是程序中间的一道处理缓冲区:
电脑文件读取的正常流程:电脑指令(获取文件) -->CPU --> 内存 --> 磁盘-->文件
--所谓的缓存,如果使用字节流来读取,并不是说表示整个过程中就会跳过内存,严格来讲这个内存将在程序运行周期一直存在.而是说在使用字节流读取的时候,其流程非常简单,就是直接向cpu去获取数据反馈.而对于字符流来说,会在向cpu索要数据时,准备一个缓冲区(任何适合于传输的数据都是字节数据例如:1011011101...),所有的数据都需要首先经过缓存的处理,在缓存之中就可以对数据进行一个先期处理,因此就可以更加方便的处理中文数据.
八.文件拷贝范例
在操作系统之中有一个copy复制命令,这个命令主要功能是可以实现文件的拷贝处理,我们可以模拟进行这一过程操作,通过输入需要拷贝的文件路径以及拷贝的目标路径,实现文件的拷贝处理:这种拷贝就有可能拷贝各种类型的文件,因此需要选中字符流来进行文件的拷贝,同时在拷贝的时候还需要考虑到大文件的拷贝问题;
--实现方案:
a.使用InputStream将全部要拷贝的内容直接读取到程序中,而后一次性的输出到目标文件;
缺陷:如果当前的文件很大,那么程序的运行可能导致系统的崩溃....
b.采用部分拷贝,拷贝一部分,读取一部分,输出一部分,如果采用本方法,最核心的操作为:
InputStream:public int read(byte[] b) throws IOException
OutputStream:public void write(byte b[]) throws IOException
--实现文件拷贝处理:
1 public class FileUtil { //定义一个文件操作的工具类
2 private File srcFile; //源文件路径
3 private File desFile; //目标文件路径
4
5 public FileUtil(File srcFile, File desFile) {
6 this.srcFile = srcFile;
7 this.desFile = desFile;
8 }
9
10 public FileUtil(String src, String des) {
11 this.srcFile = new File(src);
12 this.desFile = new File(des);
13 }
14
15 /**
16 * 文件的拷贝处理
17 *
18 * @return 拷贝成功结果
19 */
20 public boolean copy() throws IOException {
21 if (!this.srcFile.exists()) {
22 System.out.println("拷贝的源文件不存在");
23 return false; //源文件不存在,拷贝失败
24 }
25 if (!this.desFile.getParentFile().exists()) {
26 this.desFile.getParentFile().mkdirs(); //如果不存在父目录,则开始创建父目录
27 }
28 byte data[] = new byte[1024]; //开始一个拷贝的缓冲区
29 InputStream input = null;
30 OutputStream output = null;
31 try {
32 input = new FileInputStream(this.srcFile);
33 output = new FileOutputStream(this.desFile);
34 int len = 0;
35 while ((len = input.read(data)) != -1) {//拷贝文件
36 output.write(data, 0, len);
37 }
38 return true;
39 } catch (IOException e) {
40 throw e;
41 } finally {
42 if (input != null) {
43 input.close();
44 }
45 if (output != null) {
46 output.close();
47 }
48 }
49 }
50 }
51
52 class FileUtilTest {
53 public static void main(String[] args) throws IOException {
54 Scanner scanner = new Scanner(System.in);
55 System.out.println("请输入需要拷贝的文件路径:");
56 String src = scanner.next();
57 System.out.println("请输入目标文件路径:");
58 String des = scanner.next();
59 long start = System.currentTimeMillis();
60 FileUtil fileUtil = new FileUtil(new File(src), new File(des));
61 System.out.println(fileUtil.copy() ? "文件拷贝成功" : "文件拷贝失败");
62 long end = System.currentTimeMillis();
63 System.out.println("拷贝用时: " + (end - start));
64 }
65 }
--需要注意的是,从JDK1.9开始,InputStream和Reader类中都追加有了数据转存的处理操作方法:
InputStream:public long transferTo(OutputStream out) throw IOExpection 直接使用此方法也可以实现文件的拷贝,当然在开发中请注意所使用的jdk版本
--扩展程序:实现文件目录的拷贝,并且实现拷贝所有子目录中的文件:
1 package IO常用类库.字节流与字符流;
2
3 import java.io.*;
4 import java.util.Scanner;
5
6 /**
7 * @author : S K Y
8 * @version :0.0.1
9 */
10 public class FileUtil { //定义一个文件操作的工具类
11 private File srcFile; //源文件路径
12 private File desFile; //目标文件路径
13
14 public FileUtil(File srcFile, File desFile) {
15 this.srcFile = srcFile;
16 this.desFile = desFile;
17 }
18
19 public FileUtil(String src, String des) {
20 this.srcFile = new File(src);
21 this.desFile = new File(des);
22 }
23
24 /**
25 * 使用新的方法进行文件夹的拷贝,同时兼容了之前的单文件拷贝
26 *
27 * @return 拷贝结果
28 */
29 public boolean copyFile() throws IOException {
30 if (this.srcFile.isFile()) {
31 copy(); //用于兼容之前的方法
32 } else { //实现多文件的拷贝
33 copyFile(srcFile);
34 }
35 return true;
36 }
37
38 /**
39 * 私有方法,进行文件夹拷贝的递归操作
40 * @param nowFile 当前的文件
41 * @throws IOException
42 */
43 private void copyFile(File nowFile) throws IOException {
44 if (nowFile.isDirectory()) {
45 File[] files = nowFile.listFiles(); //列出全部目录组成
46 if (files != null) {
47 for (int i = 0; i < files.length; i++) {
48 copyFile(files[i]);
49 }
50 }
51 } else { //当前是文件
52 String replace = nowFile.getPath().replace(this.srcFile.getPath() + File.separator, desFile.getPath() + File.separator);
53 File newFile = new File(replace);
54 this.copyFile(nowFile, newFile);
55 }
56 }
57
58 /**
59 * 私有方法,拷贝文件
60 * @param srcFile 当前的文件
61 * @param desFile 目标文件
62 * @throws IOException
63 */
64 private void copyFile(File srcFile, File desFile) throws IOException {
65 if (!srcFile.exists()) {
66 System.out.println("当前的拷贝路径不存在");
67 }
68 InputStream input = null;
69 OutputStream output = null;
70 try {
71 input = new FileInputStream(srcFile);
72 if (!desFile.getParentFile().exists()) desFile.getParentFile().mkdirs();
73 output = new FileOutputStream(desFile);
74 byte data[] = new byte[1024]; //开始一个拷贝的缓冲区
75 int len;
76 while ((len = input.read(data)) != -1) {//拷贝文件
77 output.write(data, 0, len);
78 }
79 } catch (IOException e) {
80 throw e;
81 } finally {
82 if (input != null) {
83 input.close();
84 }
85 if (output != null) {
86 output.close();
87 }
88 }
89 }
90
91 /**
92 * 文件的拷贝处理
93 *
94 * @return 拷贝成功结果
95 */
96 @Deprecated //使用注解声明该方法已经过时
97 public boolean copy() throws IOException {
98 if (!this.srcFile.exists()) {
99 System.out.println("拷贝的源文件不存在");
100 return false; //源文件不存在,拷贝失败
101 }
102 if (!this.desFile.getParentFile().exists()) {
103 this.desFile.getParentFile().mkdirs(); //如果不存在父目录,则开始创建父目录
104 }
105 byte data[] = new byte[1024]; //开始一个拷贝的缓冲区
106 InputStream input = null;
107 OutputStream output = null;
108 try {
109 input = new FileInputStream(this.srcFile);
110 output = new FileOutputStream(this.desFile);
111 int len = 0;
112 while ((len = input.read(data)) != -1) {//拷贝文件
113 output.write(data, 0, len);
114 }
115 return true;
116 } catch (IOException e) {
117 throw e;
118 } finally {
119 if (input != null) {
120 input.close();
121 }
122 if (output != null) {
123 output.close();
124 }
125 }
126 }
127 }
128
129 class FileUtilTest {
130 public static void main(String[] args) throws IOException {
131 Scanner scanner = new Scanner(System.in);
132 System.out.println("请输入需要拷贝的文件路径:");
133 String src = scanner.next();
134 System.out.println("请输入目标文件路径:");
135 String des = scanner.next();
136 long start = System.currentTimeMillis();
137 FileUtil fileUtil = new FileUtil(new File(src), new File(des));
138 System.out.println(fileUtil.copyFile() ? "文件拷贝成功" : "文件拷贝失败");
139 long end = System.currentTimeMillis();
140 System.out.println("拷贝用时: " + (end - start));
141 }
142 }