代码链接:https://github.com/zhuqunxi/pytorch-implement-NLP
P01 -- Two layer model
- Numpy to tensor: x_tensor = torch.from_numpy(np_x)
- Cpu tensor to cuda: x_tensor_cuda= x_tensor.cuda()
- Cuda data to Variable: x_tensor_cuda_var=Variable(x_tensor_cuda)
- Tensor to numpy: x_np=x_tensor.cpu().numpy()
- Variable to numpy: x_np=x_tensor_cuda_var.cpu().detach().numpy()
随机数据


1 import numpy as np 2 import torch 3 import torch.nn as nn 4 np.random.seed(1) 5 torch.manual_seed(1) 6 7 device = 'cuda' if torch.cuda.is_available() else 'cpu' 8 # device = 'cpu' 9 print('device:', device) 10 device = torch.device(device) 11 12 N, D_in, D_out =64, 1000, 10 13 train_x = np.random.normal(size=(N, D_in)) 14 train_y = np.random.normal(size=(N, D_out)) 15 16 class Two_layer(torch.nn.Module): 17 def __init__(self, D_in, D_out, H=100): 18 super(Two_layer, self).__init__() 19 self.linear1 = nn.Linear(D_in, H) 20 self.relu = nn.ReLU() 21 self.linear2 = nn.Linear(H, D_out) 22 def forward(self, x): 23 x = self.linear1(x) 24 x = self.relu(x) 25 x = self.linear2(x) 26 return x 27 28 model = Two_layer(D_in, D_out, H=1000) 29 30 loss_fn = nn.MSELoss(reduction='sum') 31 # optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-4) 32 optimizer = torch.optim.SGD(params=model.parameters(), lr=1e-4) 33 34 train_x = torch.from_numpy(train_x).type(dtype=torch.float32) 35 train_y = torch.from_numpy(train_y).type(dtype=torch.float32) 36 37 # train_x = torch.randn(N, D_in) 38 # train_y = torch.randn(N, D_out) 39 40 train_x = train_x.to(device) 41 train_y = train_y.to(device) 42 model = model.to(device) 43 44 import time 45 time_st = time.time() 46 for epoch in range(200): 47 y_pred = model(train_x) 48 49 loss = loss_fn(y_pred, train_y) 50 optimizer.zero_grad() 51 if not epoch % 20: 52 print('loss: ', loss.item()) 53 loss.backward() 54 optimizer.step() 55 print('training time used {:.1f} s with {}'.format(time.time() - time_st, device)) 56 57 """ 58 loss: 673.6837158203125 59 loss: 57.70276641845703 60 loss: 3.7402660846710205 61 loss: 0.2832883596420288 62 loss: 0.026732178404927254 63 loss: 0.0029198969714343548 64 loss: 0.00034921077894978225 65 loss: 4.434480797499418e-05 66 loss: 5.87546583119547e-06 67 loss: 8.037222301027214e-07 68 training time used 1.1 s with cpu 69 training time used 0.6 s with cuda 70 """
Mnist数据集
1 from keras.datasets import mnist 2 import torch 3 import numpy as np 4 np.random.seed(1) 5 torch.manual_seed(1) 6 7 device = 'cuda' if torch.cuda.is_available() else 'cpu' 8 # device = 'cpu' 9 print('device:', device) 10 device = torch.device(device) 11 12 (x_train, y_train), (x_test, y_test) = mnist.load_data() 13 print('x_train, y_train shape:', x_train.shape, y_train.shape) 14 print('x_test, y_test shape:', x_test.shape, y_test.shape) 15 x_train = x_train.reshape(x_train.shape[0], -1) 16 x_test = x_test.reshape(x_test.shape[0], -1) 17 print('x_train, y_train shape:', x_train.shape, y_train.shape) 18 print('x_test, y_test shape:', x_test.shape, y_test.shape) 19 20 N, D_in, D_out = 1000, x_train.shape[1], 10 21 22 class Two_layer(torch.nn.Module): 23 def __init__(self, D_in, D_out, H=1000): 24 super(Two_layer, self).__init__() 25 self.linear1 = torch.nn.Linear(D_in, H) 26 self.relu = torch.nn.ReLU() 27 self.linear2 = torch.nn.Linear(H, D_out) 28 def forward(self, x): 29 x = self.linear1(x) 30 x = self.relu(x) 31 x = self.linear2(x) 32 return x 33 34 model = Two_layer(D_in, D_out, H = 1000) 35 loss_fn = torch.nn.CrossEntropyLoss() 36 opt = torch.optim.Adam(params=model.parameters(), lr=1e-4) 37 x_train, y_train = torch.tensor(x_train,dtype=torch.float32), torch.tensor(y_train, dtype=torch.long) 38 x_test, y_test = torch.tensor(x_test,dtype=torch.float32), torch.tensor(y_test, dtype=torch.long) 39 40 x_train, y_train = x_train.to(device), y_train.to(device) 41 x_test, y_test = x_test.to(device), y_test.to(device) 42 model = model.to(device) 43 import time 44 time_st = time.time() 45 for epoch in range(50): 46 y_pred = model(x_train) 47 loss = loss_fn(y_pred, y_train) 48 49 if not epoch % 10: 50 with torch.no_grad(): 51 y_pred_test = model(x_test) 52 y_label_pred = np.argmax(y_pred_test.cpu().detach().numpy(), axis=1) 53 print('y_label_pred y_test shape:', y_label_pred.shape, y_test.size()) 54 acc_test = np.mean(y_label_pred == y_test.cpu().detach().numpy()) 55 loss_test = loss_fn(y_pred_test, y_test) 56 print('test loss: {}, acc: {}'.format(loss_test.item(), acc_test)) 57 58 y_label_pred_train = np.argmax(y_pred.cpu().detach().numpy(), axis=1) 59 acc_train = np.mean(y_label_pred_train == y_train.cpu().detach().numpy()) 60 print('train loss: {}, acc: {}'.format(loss.item(), acc_train)) 61 62 print('-' * 80) 63 64 opt.zero_grad() 65 loss.backward() 66 opt.step() 67 68 print('training time used {:.2f} s with device {}'.format(time.time() - time_st, device)) 69 70 ''' 71 x_train, y_train shape: (60000, 28, 28) (60000,) 72 x_test, y_test shape: (10000, 28, 28) (10000,) 73 x_train, y_train shape: (60000, 784) (60000,) 74 x_test, y_test shape: (10000, 784) (10000,) 75 y_label_pred y_test shape: (10000,) torch.Size([10000]) 76 test loss: 23.847854614257812, acc: 0.1414 77 train loss: 23.87252426147461, acc: 0.13683333333333333 78 -------------------------------------------------------------------------------- 79 y_label_pred y_test shape: (10000,) torch.Size([10000]) 80 test loss: 3.340665578842163, acc: 0.7039 81 train loss: 3.514056444168091, acc: 0.6925166666666667 82 -------------------------------------------------------------------------------- 83 y_label_pred y_test shape: (10000,) torch.Size([10000]) 84 test loss: 1.7213207483291626, acc: 0.844 85 train loss: 1.8277908563613892, acc: 0.84025 86 -------------------------------------------------------------------------------- 87 y_label_pred y_test shape: (10000,) torch.Size([10000]) 88 test loss: 1.2859240770339966, acc: 0.8845 89 train loss: 1.3402273654937744, acc: 0.88125 90 -------------------------------------------------------------------------------- 91 y_label_pred y_test shape: (10000,) torch.Size([10000]) 92 test loss: 1.0803418159484863, acc: 0.8993 93 train loss: 1.084514856338501, acc: 0.8984833333333333 94 -------------------------------------------------------------------------------- 95 training time used 81.26 s with device cpu 96 training time used 3.61 s with device cuda 97 '''
P02 wordvec
Skipgram model
1 import numpy as np 2 import torch 3 import torch.nn as nn 4 import torch.nn.functional as F 5 from torch.utils.data import DataLoader, Dataset 6 import os 7 8 np.random.seed(1) 9 torch.manual_seed(1) 10 11 device = 'cuda' if torch.cuda.is_available() else 'cpu' 12 # device = 'cpu' 13 print('device:', device) 14 device = torch.device(device) 15 16 small = 5000000 17 training = True 18 N_epoch = 51 19 Batch_size = 128 20 show_epoch = 1 21 22 words = {} 23 with open('zhihu.txt', mode='r', encoding='utf8') as f: 24 lines = f.readlines() 25 print('len(lines):', len(lines)) 26 for idx, line in enumerate(lines): 27 # print(line) 28 for word in line.split(): 29 if word in words: 30 words[word] += 1 31 else: 32 words[word] = 1 33 if idx > small: 34 break 35 print(len(words)) 36 # print(words) 37 word2index = {word: idx for idx, word in enumerate(words.keys())} 38 indx2word = {idx: word for idx, word in enumerate(words.keys())} 39 # print(word2index) 40 # print(indx2word) 41 word_freq = np.array(list(words.values())) 42 word_freq = word_freq / np.sum(word_freq) 43 word_freq = word_freq ** (3 / 4.0) 44 word_freq = word_freq / np.sum(word_freq) 45 word_freq = torch.Tensor(word_freq) 46 # print(word_freq) 47 48 C, K = 3, 10 # C:窗口大小, K:每个positive样本对应K个negative样本 49 em_dim = 100 50 word_size = len(words) 51 52 53 def creat_train_data(): 54 Center_Outside_words, Center_Outside_words_index = [], [] 55 with open('zhihu.txt', mode='r', encoding='utf8') as f: 56 lines = f.readlines() 57 print('len(lines):', len(lines)) 58 for _, line in enumerate(lines): 59 # print(line) 60 line = line.split() 61 n = len(line) 62 for idx, word in enumerate(line): 63 st = max(idx - C, 0) 64 ed = min(idx + 1 + C, n) 65 for i in range(st, idx): 66 word_ = line[i] 67 Center_Outside_words.append([word, word_]) 68 Center_Outside_words_index.append([word2index[word], word2index[word_]]) 69 for i in range(idx + 1, ed): 70 word_ = line[i] 71 Center_Outside_words.append([word, word_]) 72 Center_Outside_words_index.append([word2index[word], word2index[word_]]) 73 if _ > small: 74 break 75 return Center_Outside_words, Center_Outside_words_index 76 77 Center_Outside_words, Center_Outside_words_index = creat_train_data() 78 Center_Outside_words_index = np.array(Center_Outside_words_index) 79 80 print(Center_Outside_words[:10]) 81 print(Center_Outside_words_index[:10]) 82 print('train data len:', len(Center_Outside_words)) 83 84 N_train = len(Center_Outside_words) 85 86 def get_batch(batch_step): 87 st, ed = batch_step * Batch_size, min(batch_step * Batch_size + Batch_size, N_train) 88 assert st < ed 89 center_word = torch.LongTensor(Center_Outside_words_index[st:ed, 0]) # (batch, ) 90 outside_word = torch.LongTensor(Center_Outside_words_index[st:ed, 1]) # (batch, ) 91 negtive_word = torch.multinomial(word_freq, K * (ed - st)).view(-1, K) # (batch, K) 92 93 # print(center_word.size(), outside_word.size(), negtive_word.size()) 94 # print(center_word, outside_word, negtive_word) 95 return center_word, outside_word, negtive_word 96 97 center_word, outside_word, negtive_word = get_batch(batch_step=0) 98 99 100 class Zhihu_DataSet(Dataset): 101 def __init__(self, Center_Outside_words_index, word_freq): 102 self.Center_Outside_words_index = Center_Outside_words_index 103 self.word_freq = word_freq 104 print('Center_Outside_words_index shape:', Center_Outside_words_index.shape) 105 106 def __len__(self): 107 return len(self.Center_Outside_words_index) 108 109 def __getitem__(self, index): 110 # center_word = torch.LongTensor([self.Center_Outside_words_index[index, 0]]) 111 # outside_word = torch.LongTensor([self.Center_Outside_words_index[index, 1]]) 112 113 center_word = torch.tensor(self.Center_Outside_words_index[index, 0],dtype=torch.long) 114 outside_word = torch.tensor(self.Center_Outside_words_index[index, 1],dtype=torch.long) 115 116 negtive_word = torch.multinomial(word_freq, K, replacement=True) # (batch, K) 117 # print(center_word.size(), outside_word.size(), negtive_word.size()) 118 return center_word, outside_word, negtive_word 119 120 121 122 zhihu_dataset = Zhihu_DataSet(Center_Outside_words_index, word_freq) 123 zhihu_dataloader = DataLoader(dataset=zhihu_dataset,batch_size=Batch_size, shuffle=True) 124 125 class Word2Vec_Zqx(nn.Module): 126 def __init__(self, word_size, em_dim): 127 super(Word2Vec_Zqx, self).__init__() 128 self.word_em_center = nn.Embedding(num_embeddings=word_size,embedding_dim=em_dim) 129 self.word_em_outside = nn.Embedding(num_embeddings=word_size,embedding_dim=em_dim) 130 131 def forward(self, center_word, outside_word, negtive_word): 132 center_word_emd = self.word_em_center(center_word) # (batch, em_dim) 133 outside_word_emd = self.word_em_outside(outside_word) # (batch, em_dim) 134 negtive_word_emd = self.word_em_outside(negtive_word) # (batch, K, em_dim)) 135 136 # print(center_word_emd.size(), outside_word_emd.size(), negtive_word_emd.size()) 137 center_word_emd = center_word_emd.unsqueeze(dim=2) # (batch, em_dim, 1) 138 outside_word_emd = outside_word_emd.unsqueeze(dim=1) # (batch, 1, em_dim) 139 # print(center_word_emd.size(), outside_word_emd.size(), negtive_word_emd.size()) 140 center_outside_word = torch.bmm(outside_word_emd, center_word_emd).squeeze(1) 141 center_outside_word = center_outside_word.squeeze(1) # (batch, ) 142 center_negtive_word = torch.bmm(negtive_word_emd, center_word_emd).squeeze(2) # (batch, K) 143 # print(center_outside_word.size(), center_negtive_word.size()) 144 145 loss = - (torch.sum(F.logsigmoid(center_outside_word)) + torch.sum(F.logsigmoid(center_negtive_word))) 146 return loss 147 148 def get_emd_center(self): 149 return self.word_em_center.weight.cpu().detach().numpy() 150 151 model =Word2Vec_Zqx(word_size=word_size, em_dim=em_dim) 152 loss = model(center_word, outside_word, negtive_word) 153 print('loss:', loss.item()) 154 155 # 模型保存 156 check_path = './Checkpoints/' 157 filepath = check_path + 'word2vec_state_dict.pkl' 158 def find_similar_word(emd_center, word): 159 word_idx = word2index[word] 160 word_emd = emd_center[word_idx].reshape(-1, 1) 161 # similarity = np.matmul(emd_center, word_emd).flatten() 162 similarity = np.matmul(emd_center, word_emd).flatten() / np.linalg.norm(emd_center, axis=1) / np.linalg.norm(word_emd) 163 k = 10 164 topk_idx = np.argsort(-similarity)[:k] 165 166 print('与word=[{}]--相似的top {}的有:'.format(word, k)) 167 topk_word = [indx2word[_] for _ in topk_idx] 168 print(topk_word) 169 170 def train(model): 171 # opt = torch.optim.Adam(model.parameters(), lr=1e-4) 172 opt = torch.optim.SGD(model.parameters(), lr=1e-2) 173 model.to(device) 174 import time 175 time_st_global = time.time() 176 for epoch in range(N_epoch): 177 time_st_epoch = time.time() 178 for batch_step in range(N_train // Batch_size): 179 center_word, outside_word, negtive_word = get_batch(batch_step) 180 center_word, outside_word, negtive_word = center_word.to(device), outside_word.to(device), negtive_word.to(device) 181 loss = model(center_word, outside_word, negtive_word) 182 183 opt.zero_grad() 184 loss.backward() 185 opt.step() 186 print('# ' * 80) 187 print('epoch:{}, batch_step: {}, loss: {}'.format(epoch, batch_step, loss.item())) 188 print('epoch time {:.2f} s, total time {:.2f} s'.format(time.time() - time_st_epoch, time.time() - time_st_global)) 189 if not epoch % show_epoch: 190 if not os.path.exists(check_path): 191 os.makedirs(check_path) 192 torch.save(model.state_dict(), filepath) 193 emd_center = model.get_emd_center() 194 195 test_words = ['你', '为什么', '学生', '女生', '什么', '大学'] 196 for word in test_words: 197 print('-' * 80) 198 print('test word : {}, 次数: {}'.format(word, words[word])) 199 find_similar_word(emd_center=emd_center, word=word) 200 201 return model 202 203 def train_with_dataloader(model): 204 # opt = torch.optim.Adam(model.parameters(), lr=1e-4) 205 opt = torch.optim.SGD(model.parameters(), lr=1e-2) 206 model.to(device) 207 import time 208 time_st_global = time.time() 209 for epoch in range(N_epoch): 210 time_st_epoch = time.time() 211 for batch_step, (center_word, outside_word, negtive_word) in enumerate(zhihu_dataloader): 212 center_word, outside_word, negtive_word = center_word.to(device), outside_word.to(device), negtive_word.to(device) 213 loss = model(center_word, outside_word, negtive_word) 214 215 opt.zero_grad() 216 loss.backward() 217 opt.step() 218 print('#' * 80) 219 print('epoch:{}, batch_step: {}, loss: {}'.format(epoch, batch_step, loss.item())) 220 print('epoch time {:.2f} s, total time {:.2f} s'.format(time.time() - time_st_epoch, time.time() - time_st_global)) 221 if not epoch % show_epoch: 222 if not os.path.exists(check_path): 223 os.makedirs(check_path) 224 torch.save(model.state_dict(), filepath) 225 226 # emd_center = model.get_emd_center() 227 # test_words = ['你', '为什么', '学生', '女生', '什么', '大学'] 228 # for word in test_words: 229 # print('-' * 80) 230 # print('test word : {}, 次数: {}'.format(word, words[word])) 231 # find_similar_word(emd_center=emd_center, word=word) 232 233 return model 234 235 if training: 236 # model = train(model) 237 model = train_with_dataloader(model) 238 239 # 模型恢复 240 model.load_state_dict(torch.load(filepath)) 241 242 emd_center = model.get_emd_center() 243 244 245 test_words = ['你', '为什么', '学生', '女生', '什么', '大学'] 246 247 for word in test_words: 248 print('-' * 80) 249 print('test word : {}, 次数: {}'.format(word, words[word])) 250 find_similar_word(emd_center=emd_center, word=word) 251 252 print('end!!!')
P03 RNN
mnist classification
1 from keras.datasets import mnist 2 import torch 3 import torch.nn as nn 4 import torch.nn.functional as F 5 import numpy as np 6 import time 7 np.random.seed(1) 8 torch.manual_seed(1) 9 10 device = 'cuda' if torch.cuda.is_available() else 'cpu' 11 # device = 'cpu' 12 print('device:', device) 13 device = torch.device(device) 14 15 N, D_in, D_out = 10000, 28, 10 16 H = 100 17 Batch_size = 128 18 lr=1e-2 19 N_epoch = 200 20 21 22 (x_train, y_train), (x_test, y_test) = mnist.load_data() 23 x_train, y_train = x_train[:N], y_train[:N] 24 x_test, y_test = x_test[:N], y_test[:N] 25 26 # 归一化很重要,不然有可能train不起来,或者test效果不行 27 x_train = x_train /255.0 28 x_test = x_test / 255.0 29 30 print('x_train, y_train shape:', x_train.shape, y_train.shape) 31 print('x_test, y_test shape:', x_test.shape, y_test.shape) 32 print('np.max(x_train), np.min(x_train):', np.max(x_train), np.min(x_train)) 33 print('np.max(y_train), np.min(y_train):', np.max(y_train), np.min(y_train)) 34 35 class RNN_zqx(nn.Module): 36 def __init__(self, D_in, H): 37 super(RNN_zqx, self).__init__() 38 self.rnn = nn.LSTM(input_size=D_in,hidden_size=H,num_layers=1,batch_first=True) 39 self.linear = nn.Linear(H, 10) 40 def forward(self, x): 41 all_h, (h, c) = self.rnn(x) 42 # all_h: (batch, seq_len, num_directions * hidden_size) 43 # h: (num_layers * num_directions, batch, hidden_size) 44 # print('all_h.size():', all_h.size()) 45 # print('h.size():', h.size()) 46 x = self.linear(h.squeeze(0)) 47 return x 48 49 model =RNN_zqx(D_in=D_in, H=H) 50 loss_fn = nn.CrossEntropyLoss() 51 opt = torch.optim.Adam(model.parameters(), lr=lr) 52 53 x_train, y_train = torch.Tensor(x_train), torch.LongTensor(y_train) 54 x_test, y_test = torch.Tensor(x_test), torch.LongTensor(y_test) 55 56 print('x_train.size(), y_train.size():', x_train.size(), y_train.size()) 57 x_train, y_train = x_train.to(device), y_train.to(device) 58 x_test, y_test = x_test.to(device), y_test.to(device) 59 mdoel = model.to(device) 60 61 time_st = time.time() 62 for epoch in range(N_epoch): 63 y_pred = model(x_train) 64 # print(y_pred.size()) 65 loss = loss_fn(y_pred, y_train) 66 67 if not epoch % 10: 68 with torch.no_grad(): 69 y_pred_test = model(x_test) 70 y_label_pred = np.argmax(y_pred_test.cpu().detach().numpy(), axis=1) 71 # print('y_label_pred y_test shape:', y_label_pred.shape, y_test.size()) 72 acc_test = np.mean(y_label_pred == y_test.cpu().detach().numpy()) 73 loss_test = loss_fn(y_pred_test, y_test) 74 print('test loss: {}, acc: {}'.format(loss_test.item(), acc_test)) 75 76 y_label_pred_train = np.argmax(y_pred.cpu().detach().numpy(), axis=1) 77 acc_train = np.mean(y_label_pred_train == y_train.cpu().detach().numpy()) 78 print('train loss: {}, acc: {}'.format(loss.item(), acc_train)) 79 80 print('-' * 80) 81 82 opt.zero_grad() 83 loss.backward() 84 opt.step() 85 86 print('Training time used {:.2f} s'.format(time.time() - time_st)) 87 88 ''' 89 device: cuda 90 x_train, y_train shape: (10000, 28, 28) (10000,) 91 x_test, y_test shape: (10000, 28, 28) (10000,) 92 np.max(x_train), np.min(x_train): 1.0 0.0 93 np.max(y_train), np.min(y_train): 9 0 94 x_train.size(), y_train.size(): torch.Size([10000, 28, 28]) torch.Size([10000]) 95 test loss: 2.3056862354278564, acc: 0.1032 96 train loss: 2.3057758808135986, acc: 0.0991 97 -------------------------------------------------------------------------------- 98 test loss: 1.6542853116989136, acc: 0.5035 99 train loss: 1.651445746421814, acc: 0.482 100 -------------------------------------------------------------------------------- 101 test loss: 1.0779469013214111, acc: 0.6027 102 train loss: 1.0364742279052734, acc: 0.6158 103 -------------------------------------------------------------------------------- 104 test loss: 0.7418596148490906, acc: 0.7503 105 train loss: 0.7045448422431946, acc: 0.7642 106 -------------------------------------------------------------------------------- 107 test loss: 0.5074136853218079, acc: 0.8369 108 train loss: 0.46816474199295044, acc: 0.8512 109 -------------------------------------------------------------------------------- 110 test loss: 0.3507310748100281, acc: 0.8931 111 train loss: 0.29413318634033203, acc: 0.9125 112 -------------------------------------------------------------------------------- 113 test loss: 0.25384169816970825, acc: 0.9292 114 train loss: 0.1905861645936966, acc: 0.9446 115 -------------------------------------------------------------------------------- 116 test loss: 0.21215158700942993, acc: 0.9406 117 train loss: 0.13411203026771545, acc: 0.9614 118 -------------------------------------------------------------------------------- 119 test loss: 0.19598548114299774, acc: 0.9467 120 train loss: 0.0968935638666153, acc: 0.9711 121 -------------------------------------------------------------------------------- 122 test loss: 0.6670947074890137, acc: 0.834 123 train loss: 0.6392199993133545, acc: 0.8405 124 -------------------------------------------------------------------------------- 125 test loss: 0.3550219237804413, acc: 0.8966 126 train loss: 0.29769250750541687, acc: 0.9112 127 -------------------------------------------------------------------------------- 128 test loss: 0.22847041487693787, acc: 0.9345 129 train loss: 0.16787868738174438, acc: 0.9545 130 -------------------------------------------------------------------------------- 131 test loss: 0.19370371103286743, acc: 0.9464 132 train loss: 0.1122715100646019, acc: 0.9692 133 -------------------------------------------------------------------------------- 134 test loss: 0.16738709807395935, acc: 0.9538 135 train loss: 0.08012499660253525, acc: 0.9787 136 -------------------------------------------------------------------------------- 137 test loss: 0.16035553812980652, acc: 0.9575 138 train loss: 0.06216369569301605, acc: 0.9838 139 -------------------------------------------------------------------------------- 140 test loss: 0.15690605342388153, acc: 0.9587 141 train loss: 0.04842701926827431, acc: 0.9877 142 -------------------------------------------------------------------------------- 143 test loss: 0.1597040444612503, acc: 0.9586 144 train loss: 0.03863723576068878, acc: 0.9909 145 -------------------------------------------------------------------------------- 146 test loss: 0.16320295631885529, acc: 0.9593 147 train loss: 0.031261660158634186, acc: 0.9933 148 -------------------------------------------------------------------------------- 149 test loss: 0.1675170212984085, acc: 0.959 150 train loss: 0.02533782459795475, acc: 0.9948 151 -------------------------------------------------------------------------------- 152 test loss: 0.17022284865379333, acc: 0.9592 153 train loss: 0.020637042820453644, acc: 0.9962 154 -------------------------------------------------------------------------------- 155 '''
rnn中pad和pack的使用
torch.nn.utils.rnn.pad_sequence()
torch.nn.utils.rnn.pack_padded_sequence()
torch.nn.utils.rnn.pad_packed_sequence()
LSTM (BiLSTM) 分词
1 import numpy as np 2 import torch 3 import torch.nn as nn 4 import torch.nn.functional as F 5 from torch.utils.data import DataLoader, Dataset 6 import os 7 import time 8 import matplotlib.pyplot as plt 9 10 np.random.seed(1) 11 torch.manual_seed(1) 12 13 device = 'cuda' if torch.cuda.is_available() else 'cpu' 14 # device = 'cpu' 15 print('device:', device) 16 device = torch.device(device) 17 18 small = 50000 19 training = True 20 show_loss = True 21 N_epoch = 10 22 Batch_size = 256 23 show_epoch = 1 24 H = 128 25 em_dim = 100 26 lr = 1e-2 27 fold=0 28 net = 'BiLSTM' 29 30 31 words = {} 32 max_seq = 0 33 34 label2idx = {'B': 0, 'I': 1, 'S': 2} 35 idx2label = {0: 'B', 1: 'I', 2: 'S'} 36 37 Sentences = [] 38 Sentences_label = [] 39 Sentences_origin = [] 40 41 with open('zhihu.txt', mode='r', encoding='utf8') as f: 42 lines = f.readlines() 43 print('len(lines):', len(lines)) 44 for idx, line in enumerate(lines): 45 # print(line) 46 line = line.split() 47 tmp = [] 48 mmp = [] 49 for word in line: 50 if len(word)==1: 51 mmp.append(label2idx['S']) 52 else: 53 mmp.append(label2idx['B']) 54 for _ in range(1, len(word)): 55 mmp.append(label2idx['I']) 56 57 for w in word: 58 if w in words: 59 words[w] += 1 60 else: 61 words[w] = 1 62 tmp.append(w) 63 Sentences.append(tmp) 64 Sentences_label.append(mmp) 65 max_seq = max(max_seq, len(tmp)) 66 assert len(mmp)==len(tmp) 67 # print(tmp) 68 if idx > small: 69 break 70 71 Sentences.sort(key=lambda x: len(x), reverse=True) 72 Sentences_label.sort(key=lambda x: len(x), reverse=True) 73 # for sentence in Sentences: 74 # print(sentence) 75 print('len(words):', len(words)) 76 # print(words) 77 print('max_seq len:', max_seq) 78 79 # print(words) 80 word2index = {word: idx + 1 for idx, word in enumerate(words.keys())} 81 indx2word = {idx + 1: word for idx, word in enumerate(words.keys())} 82 83 84 voc_size = len(words) + 1 85 word2index['<pad>'] = 0 86 indx2word[0] = '<pad>' 87 88 Sentences_idx, Sentences_len = [], [] 89 for sentence in Sentences: 90 tmp=[] 91 for w in sentence: 92 tmp.append(word2index[w]) 93 Sentences_idx.append(torch.LongTensor(tmp)) 94 Sentences_len.append(len(tmp)) 95 # print(tmp) 96 Sentences_idx = torch.nn.utils.rnn.pad_sequence(Sentences_idx,batch_first=True) 97 # print('-' * 80) 98 # print(Sentences_idx.size()) 99 # print(Sentences_idx) 100 101 102 # print('-' * 80) 103 Sentences_label_idx = [] 104 for i, sentences_label in enumerate(Sentences_label): 105 tmp = torch.LongTensor(sentences_label) 106 Sentences_label_idx.append(tmp) 107 # print(Sentences[i]) 108 # # print(lines[i]) 109 # print(tmp) 110 assert len(tmp) == len(Sentences[i]) 111 Sentences_label_idx = torch.nn.utils.rnn.pad_sequence(Sentences_label_idx,batch_first=True,padding_value=0) 112 # print('Sentences_label_idx:') 113 # print(Sentences_label_idx) 114 115 # a = torch.tensor(1.0) 116 # print(a) 117 # print(a.size()) 118 class MyDataSet(Dataset): 119 def __init__(self, data, lens, labels): 120 self.data = data 121 self.lens = lens 122 self.labels = labels 123 def __getitem__(self, idx): 124 now_data = self.data[idx] 125 now_len = self.lens[idx] 126 now_mask = [] 127 now_label = self.labels[idx] 128 for i in range(len(now_data)): 129 t = 1.0 if i < now_len else 0.0 130 now_mask.append(t) 131 now_mask = torch.Tensor(now_mask) 132 return now_data, now_len, now_mask, now_label 133 def __len__(self): 134 return len(self.data) 135 136 class FenCi_Zqx(nn.Module): 137 def __init__(self, voc_size, em_dim, H): 138 super(FenCi_Zqx, self).__init__() 139 self.emd = nn.Embedding(num_embeddings=voc_size,embedding_dim=em_dim) 140 if net == 'LSTM': 141 self.rnn = nn.LSTM(input_size=em_dim,hidden_size=H,num_layers=1,batch_first=True) 142 self.linear = nn.Linear(in_features=H,out_features=3) 143 if net == 'BiLSTM': 144 self.rnn = nn.LSTM(input_size=em_dim, hidden_size=H, num_layers=1, batch_first=True,bidirectional=True) 145 self.linear = nn.Linear(in_features=2*H, out_features=3) 146 def forward(self, sentence, sentence_len=None, mask=None): 147 emd = self.emd(sentence) # (batch, seq_len, em_dim) 148 all_h, (h, c) = self.rnn(emd) # LSTM: (batch, seq_len, H) BiLSTM: (batch, seq_len, 2*H) 149 # print('emd size:', emd.size()) 150 # print('all_h.size():', all_h.size()) 151 # out = all_h.view(-1, all_h.size(2)) # (batch * seq_len, H) 152 out = self.linear(all_h).view(emd.size(0), emd.size(1), 3) # (batch, seq_len, 3) 153 # print('out size:', out.size()) 154 return out 155 156 Sentences_len = torch.Tensor(Sentences_len) 157 train_idx = [i for i in range(len(Sentences_len)) if i % 5 == fold] 158 test_idx = [i for i in range(len(Sentences_len)) if i % 5 != fold] 159 print(train_idx, ' ', test_idx) 160 Train_Sentences_idx, Train_Sentences_len, Train_Sentences_label_idx = 161 Sentences_idx[train_idx], Sentences_len[train_idx], Sentences_label_idx[train_idx] 162 Test_Sentences_idx, Test_Sentences_len, Test_Sentences_label_idx = 163 Sentences_idx[test_idx], Sentences_len[test_idx], Sentences_label_idx[test_idx] 164 Train_data = MyDataSet(Train_Sentences_idx, Train_Sentences_len, Train_Sentences_label_idx) 165 Train_data_loader = DataLoader(dataset=Train_data, batch_size=Batch_size, shuffle=True) 166 Test_data = MyDataSet(Test_Sentences_idx, Test_Sentences_len, Test_Sentences_label_idx) 167 Test_data_loader = DataLoader(dataset=Test_data, batch_size=Batch_size, shuffle=False) 168 169 model = FenCi_Zqx(voc_size=voc_size, em_dim=em_dim, H=H) 170 loss_fn = nn.CrossEntropyLoss(reduction='none') 171 opt = torch.optim.Adam(model.parameters(), lr=lr) 172 173 174 print('Sentences_idx, Sentences_len, Sentences_label_idx shape') 175 print(len(Sentences_idx), len(Sentences_len), len(Sentences_label_idx)) 176 print(Sentences_idx.size(), Sentences_len.size(), Sentences_label_idx.size()) 177 print(Sentences_idx.shape, Sentences_len.shape, Sentences_label_idx.shape) 178 print('#' * 60) 179 print(model) 180 181 def valid(model): 182 # model.to(device) 183 # model.eval() 184 with torch.no_grad(): 185 avg_loss = 0 186 cnt=0 187 for batch_step, (now_data, now_len, now_mask, now_label) in enumerate(Test_data_loader): 188 cnt += 1 189 now_data, now_len, now_mask, now_label = 190 now_data.to(device), now_len.to(device), now_mask.to(device), now_label.to(device) 191 out = model(now_data, now_len, now_mask) 192 out = out.view(-1, 3) 193 now_mask = now_mask.view(-1) 194 now_label = now_label.view(-1) 195 loss = loss_fn(out, now_label) 196 # print('loss size:', loss.size()) 197 # print(out.size(), now_label.size(), now_mask.size()) 198 loss = torch.mean(loss * now_mask) 199 avg_loss += loss.item() 200 # print('loss size:', loss.size()) 201 # print('loss:', loss.item()) 202 203 avg_loss /= cnt 204 return avg_loss 205 206 207 def train(model): 208 print('start training:') 209 model.to(device) 210 time_st_global = time.time() 211 Train_loss,Valid_loss = [], [] 212 for epoch in range(N_epoch): 213 time_st_epoch = time.time() 214 avg_loss = 0 215 cnt = 0 216 for batch_step, (now_data, now_len, now_mask, now_label) in enumerate(Train_data_loader): 217 cnt += 1 218 now_data, now_len, now_mask, now_label = 219 now_data.to(device), now_len.to(device), now_mask.to(device), now_label.to(device) 220 out = model(now_data, now_len, now_mask) 221 out = out.view(-1, 3) 222 now_mask = now_mask.view(-1) 223 now_label = now_label.view(-1) 224 loss = loss_fn(out, now_label) 225 # print('loss size:', loss.size()) 226 # print(out.size(), now_label.size(), now_mask.size()) 227 loss = torch.mean(loss * now_mask) 228 avg_loss += loss.item() 229 # print('loss size:', loss.size()) 230 # print('loss:', loss.item()) 231 232 opt.zero_grad() 233 loss.backward() 234 opt.step() 235 avg_loss /= cnt 236 valid_avg_loss = valid(model) 237 print('#' * 80) 238 print('epoch:{}, steps: {}, train avg loss: {} -- valid avg loss : {} '.format(epoch, cnt, avg_loss, valid_avg_loss)) 239 print('epoch time {:.2f} s, total time {:.2f} s'.format(time.time() - time_st_epoch, 240 time.time() - time_st_global)) 241 if len(Valid_loss)==0 or valid_avg_loss < min(Valid_loss): 242 if not os.path.exists(check_path): 243 os.makedirs(check_path) 244 torch.save(model.state_dict(), filepath) 245 246 Train_loss.append(avg_loss) 247 Valid_loss.append(valid_avg_loss) 248 249 if show_loss: 250 plt.figure() 251 plt.plot(Train_loss,label='Train loss') 252 plt.plot(Valid_loss, label='Valid loss') 253 plt.legend() 254 plt.savefig('Train_Valid_loss' + net + '.png') 255 # plt.show() 256 return model 257 258 # break 259 260 check_path = './Checkpoints/' 261 filepath = check_path + 'p03_Fenci_state_dict_' + net + ' .pkl' 262 263 if training: 264 model = train(model) 265 266 267 # 模型恢复 268 model.load_state_dict(torch.load(filepath)) 269 270 271 test_words = [ 272 '我是中国人,我爱祖国', 273 '独行侠队的球员们承诺每天为达拉斯地区奋战在抗疫一线的工作人员们提供餐食', 274 '汤普森太爱打球,不能出场让他很煎熬', 275 '这个赛季对克莱来说非常艰难,他太热爱打篮球了,无法上场让他很受打击。', 276 '克莱和斯蒂芬会处在极佳的状态,准备好比赛。', 277 '勇士已经证明了他们也是一支历史级别的球队,维金斯在稍强于巴恩斯的前提下,仍然算得上是三号位上一位合格的替代者' 278 ] 279 280 np.set_printoptions(precision=3, suppress=True) 281 model.cpu() 282 model.eval() 283 for word in test_words: 284 print('-' * 80) 285 print('test word : {}'.format(word)) 286 word_idx = [word2index[w] for w in word] 287 word_idx = torch.LongTensor([word_idx]) 288 # print('word_idx.size():', word_idx.size()) 289 # word_idx.to(device) 290 out = model(word_idx) 291 # print('out.size():', out.size()) 292 out = out.squeeze(0).cpu().detach().numpy() 293 # print('out.shape():', out.shape) 294 # print(out) 295 out_label = np.argmax(out, axis=1) 296 # print(out_label) 297 298 for i, w in enumerate(word): 299 print('{} -> {} -> {}'.format(w, idx2label[out_label[i]], out_label[i])) 300 301 print('end!!!') 302 ''' 303 test word : 勇士已经证明了他们也是一支历史级别的球队,维金斯在稍强于巴恩斯的前提下,仍然算得上是三号位上一位合格的替代者 304 勇 -> B -> 0 305 士 -> I -> 1 306 已 -> B -> 0 307 经 -> I -> 1 308 证 -> B -> 0 309 明 -> I -> 1 310 了 -> S -> 2 311 他 -> S -> 2 312 们 -> I -> 1 313 也 -> S -> 2 314 是 -> S -> 2 315 一 -> S -> 2 316 支 -> S -> 2 317 历 -> B -> 0 318 史 -> I -> 1 319 级 -> B -> 0 320 别 -> I -> 1 321 的 -> S -> 2 322 球 -> B -> 0 323 队 -> I -> 1 324 , -> S -> 2 325 维 -> B -> 0 326 金 -> I -> 1 327 斯 -> I -> 1 328 在 -> S -> 2 329 稍 -> B -> 0 330 强 -> B -> 0 331 于 -> I -> 1 332 巴 -> B -> 0 333 恩 -> I -> 1 334 斯 -> I -> 1 335 的 -> S -> 2 336 前 -> B -> 0 337 提 -> I -> 1 338 下 -> S -> 2 339 , -> S -> 2 340 仍 -> B -> 0 341 然 -> I -> 1 342 算 -> I -> 1 343 得 -> I -> 1 344 上 -> S -> 2 345 是 -> S -> 2 346 三 -> S -> 2 347 号 -> S -> 2 348 位 -> S -> 2 349 上 -> B -> 0 350 一 -> B -> 0 351 位 -> S -> 2 352 合 -> B -> 0 353 格 -> I -> 1 354 的 -> S -> 2 355 替 -> B -> 0 356 代 -> I -> 1 357 者 -> I -> 1 358 359 '''
HMM分词
1 import numpy as np 2 import os 3 import time 4 import matplotlib.pyplot as plt 5 import torch 6 import torch.nn as nn 7 np.random.seed(1) 8 9 small = 50000 10 training = True 11 show_loss = True 12 N_epoch = 10 13 Batch_size = 256 14 show_epoch = 1 15 H = 128 16 em_dim = 100 17 lr = 1e-2 18 fold=5 19 net = 'HMM' 20 check_path = './Checkpoints/' 21 filepath = check_path + 'p03_Fenci_state_dict_' + net + ' .pkl' 22 23 words = {} 24 max_seq = 0 25 26 # label2idx = {'B': 0, 'I': 1, 'S': 2, 'BOS': 3, 'EOS': 4} 27 # idx2label = {0: 'B', 1: 'I', 2: 'S', 3: 'BOS', 4: 'EOS'} 28 29 Sentences = [] 30 Sentences_tag = [] 31 32 with open('zhihu.txt', mode='r', encoding='utf8') as f: 33 lines = f.readlines() 34 print('len(lines):', len(lines)) 35 for idx, line in enumerate(lines): 36 # print(line) 37 line = line.split() 38 tmp = [] 39 mmp = [] 40 for word in line: 41 if len(word)==1: 42 mmp.append('S') 43 else: 44 mmp.append('B') 45 for _ in range(1, len(word)): 46 mmp.append('I') 47 for w in word: 48 if w in words: 49 words[w] += 1 50 else: 51 words[w] = 1 52 tmp.append(w) 53 Sentences.append(tmp) # 存下以字单位的sentence 54 Sentences_tag.append(mmp) #存下每个sentence中每个字对应的BIS标签 55 max_seq = max(max_seq, len(tmp)) 56 assert len(mmp)==len(tmp) 57 assert len(tmp)> 0 # 判断是否存在空的sentence 58 # print(tmp) 59 if idx > small: 60 break 61 62 print('len(words):', len(words)) 63 print('max_seq len:', max_seq) 64 65 for idx, sentence in enumerate(Sentences): 66 print('-' * 80) 67 print(sentence) 68 print(Sentences_tag[idx]) 69 if idx > 5: 70 break 71 72 Train_Sentences, Train_Sentences_tag = [], [] 73 Valid_Sentences, Valid_Sentences_tag = [], [] 74 for i in range(len(Sentences)): 75 if i % fold: 76 Train_Sentences.append(Sentences[i]) 77 Train_Sentences_tag.append(Sentences_tag[i]) 78 else: 79 Valid_Sentences.append(Sentences[i]) 80 Valid_Sentences_tag.append(Sentences_tag[i]) 81 82 loss_fn = nn.CrossEntropyLoss(reduction='none') 83 84 def train(Train_Sentences, Train_Sentences_tag): 85 N = len(Train_Sentences) 86 tag, tag2word, tag2tag = {}, {}, {} 87 tag['BOS'] = N 88 tag['EOS'] = N 89 for i in range(N): 90 sentence = Train_Sentences[i] 91 sentence_tag = Train_Sentences_tag[i] 92 n = len(sentence) 93 assert len(sentence) == len(sentence_tag) 94 assert n > 0 95 if ('BOS', sentence_tag[0]) in tag2tag: 96 tag2tag[('BOS', sentence_tag[0])] += 1 97 else: 98 tag2tag[('BOS', sentence_tag[0])] = 1 99 if (sentence_tag[-1], 'EOS') in tag2tag: 100 tag2tag[(sentence_tag[-1], 'EOS')] += 1 101 else: 102 tag2tag[(sentence_tag[-1], 'EOS')] = 1 103 104 for i in range(n): 105 tg, w = sentence_tag[i], sentence[i] 106 if tg in tag: 107 tag[tg] += 1 108 else: 109 tag[tg] = 1 110 if (tg, w) in tag2word: 111 tag2word[(tg, w)] += 1 112 else: 113 tag2word[(tg, w)] = 1 114 115 if i < n - 1: 116 next_tg = sentence_tag[i + 1] 117 if (tg, next_tg) in tag2tag: 118 tag2tag[(tg, next_tg)] += 1 119 else: 120 tag2tag[(tg, next_tg)] = 1 121 Prob_tag2tag, Prob_tag2word = {}, {} 122 for tg1, tg2 in tag2tag.keys(): 123 Prob_tag2tag[(tg1, tg2)] = 0.0 + tag2tag[(tg1, tg2)] / tag[tg1] 124 for tg, w in tag2word.keys(): 125 Prob_tag2word[(tg, w)] = 0.0 + tag2word[(tg, w)] / tag[tg] 126 # print('tag:{} tag2word:{} tag2tag:{} '.format(tag, tag2word, tag2tag)) 127 print('tag:{} tag2word:{} tag2tag:{} '.format(len(tag), len(tag2word), len(tag2tag))) 128 # print(' Prob_tag2word:{} Prob_tag2tag:{} '.format(Prob_tag2word, Prob_tag2tag)) 129 print(' Prob_tag2word:{} Prob_tag2tag:{} '.format(len(Prob_tag2word), len(Prob_tag2tag))) 130 return tag, tag2word, tag2tag, Prob_tag2tag, Prob_tag2word 131 Tag, Tag2word, Tag2tag, Prob_tag2tag, Prob_tag2word = train(Train_Sentences, Train_Sentences_tag) 132 133 def predict_tag(sentence, True_sentence_tag=None): 134 n = len(sentence) 135 tags = ['B', 'I', 'S', 'BOS', 'EOS'] 136 dp = [{'B': 0.0, 'I': 0.0, 'S': 0.0, 'BOS': 0.0, 'EOS': 0.0} for _ in range(n + 1)] 137 pre_tag = [{'B': None, 'I': None, 'S': None, 'BOS': None, 'EOS': None} for _ in range(n + 1)] 138 for t in range(n): 139 w = sentence[t] 140 # print('w:', w) 141 for tg in tags: 142 prob_tag2word = 1e-9 if (tg, w) not in Prob_tag2word else Prob_tag2word[(tg, w)] 143 if t == 0: 144 prob_tag2tag = 1e-9 if ('BOS', tg) not in Prob_tag2tag else Prob_tag2tag[('BOS', tg)] 145 dp[t][tg] = np.log(prob_tag2tag) + np.log(prob_tag2word) 146 pre_tag[t][tg] = 'BOS' 147 else: 148 max_prob = None 149 best_pre_tag = None 150 for pre_tg in tags: 151 prob_tag2tag = 1e-9 if (pre_tg, tg) not in Prob_tag2tag else Prob_tag2tag[(pre_tg, tg)] 152 tmp = dp[t - 1][pre_tg] + np.log(prob_tag2tag) + np.log(prob_tag2word) 153 if max_prob == None or max_prob < tmp: 154 max_prob = tmp 155 best_pre_tag = pre_tg 156 dp[t][tg] = max_prob 157 pre_tag[t][tg] = best_pre_tag 158 159 max_prob = None 160 best_pre_tag = None 161 tg = 'EOS' 162 for pre_tg in tags: 163 prob_tag2tag = 1e-9 if (pre_tg, tg) not in Prob_tag2tag else Prob_tag2tag[(pre_tg, tg)] 164 tmp = dp[n - 1][pre_tg] + np.log(prob_tag2tag) 165 if max_prob == None or max_prob < tmp: 166 max_prob = tmp 167 best_pre_tag = pre_tg 168 dp[n][tg] = max_prob 169 pre_tag[n][tg] = best_pre_tag 170 171 ans_tag = [] 172 t = n 173 174 # print('#' * 80) 175 # print('sentence:', sentence) 176 # print('True sentence tag:', True_sentence_tag) 177 # print('len(sentence):', len(sentence)) 178 # print('n:', n) 179 if True_sentence_tag is not None: 180 True_sentence_tag.append('EOS') 181 sss = sentence + ['END'] 182 while pre_tag[t][tg] is not None: 183 if True_sentence_tag is None: 184 # print('t: {}, pre_tag[t][tg]: {} -> tg: {} -- word:{}'.format( 185 # t, pre_tag[t][tg], tg, sss[t])) 186 pass 187 else: 188 assert len(True_sentence_tag) == n + 1, (n, len(True_sentence_tag)) 189 print('t: {}, pre_tag[t][tg]: {} -> tg: {} -- True tag: {}, -- word: {}'.format( 190 t, pre_tag[t][tg], tg, True_sentence_tag[t], sss[t])) 191 192 ans_tag = [pre_tag[t][tg]] + ans_tag 193 tg = pre_tag[t][tg] 194 t = t - 1 195 196 return ans_tag[1:] # 去掉BOS 197 198 # predict_tag(sentence=Sentences[0], True_sentence_tag=Sentences_tag[0]) 199 predict_tag(sentence=Sentences[0], True_sentence_tag=None) 200 201 202 def fenci_example(): 203 204 test_sentences = [ 205 '我是中国人,我爱祖国', 206 '独行侠队的球员们承诺每天为达拉斯地区奋战在抗疫一线的工作人员们提供餐食', 207 '汤普森太爱打球,不能出场让他很煎熬', 208 '这个赛季对克莱来说非常艰难,他太热爱打篮球了,无法上场让他很受打击。', 209 '克莱和斯蒂芬会处在极佳的状态,准备好比赛。', 210 '勇士已经证明了他们也是一支历史级别的球队,维金斯在稍强于巴恩斯的前提下,仍然算得上是三号位上一位合格的替代者' 211 ] 212 213 np.set_printoptions(precision=3, suppress=True) 214 215 for sentence in test_sentences: 216 print('-' * 80) 217 print('test word : {}'.format(sentence)) 218 sentence = [w for w in sentence] 219 sentence_tag = predict_tag(sentence) 220 # predict_tag(sentence=Sentences[0], True_sentence_tag=None) 221 for i, w in enumerate(sentence): 222 print('{} -> {}'.format(w, sentence_tag[i])) 223 fenci_example() 224 225 print('end!!!') 226 ''' 227 test word : 克莱和斯蒂芬会处在极佳的状态,准备好比赛。 228 克 -> B 229 莱 -> I 230 和 -> S 231 斯 -> B 232 蒂 -> I 233 芬 -> I 234 会 -> S 235 处 -> B 236 在 -> I 237 极 -> B 238 佳 -> I 239 的 -> S 240 状 -> B 241 态 -> I 242 , -> S 243 准 -> B 244 备 -> I 245 好 -> S 246 比 -> B 247 赛 -> I 248 。 -> S 249 '''
CRF分词, ps:只训练了一个epoch,不知道为什么,中间梯度爆炸了, 后来查了下,应该要用logsumexp函数,见我写的 CRF layer
1 import numpy as np 2 import os 3 import time 4 import matplotlib.pyplot as plt 5 import torch 6 import torch.nn as nn 7 np.random.seed(1) 8 9 small = 50000 10 training = True 11 show_loss = True 12 show_acc = True 13 reused_W = False 14 N_epoch = 1 15 Batch_size = 256 16 show_epoch = 10 17 H = 128 18 em_dim = 100 19 lr = 1e-2 20 fold=5 21 net = 'HMM' 22 check_path = './Checkpoints/' 23 filepath = check_path + 'W_crf.npy' 24 regulization = 0 25 26 words = {} 27 max_seq = 0 28 29 # label2idx = {'B': 0, 'I': 1, 'S': 2, 'BOS': 3, 'EOS': 4} 30 # idx2label = {0: 'B', 1: 'I', 2: 'S', 3: 'BOS', 4: 'EOS'} 31 tag_num = 5 32 Sentences = [] 33 Sentences_tag = [] 34 35 with open('zhihu.txt', mode='r', encoding='utf8') as f: 36 lines = f.readlines() 37 print('len(lines):', len(lines)) 38 for idx, line in enumerate(lines): 39 # print(line) 40 line = line.split() 41 tmp = [] 42 mmp = [] 43 for word in line: 44 if len(word)==1: 45 mmp.append('S') 46 else: 47 mmp.append('B') 48 for _ in range(1, len(word)): 49 mmp.append('I') 50 for w in word: 51 if w in words: 52 words[w] += 1 53 else: 54 words[w] = 1 55 tmp.append(w) 56 Sentences.append(tmp) # 存下以字单位的sentence 57 Sentences_tag.append(mmp) #存下每个sentence中每个字对应的BIS标签 58 max_seq = max(max_seq, len(tmp)) 59 assert len(mmp)==len(tmp) 60 assert len(tmp)> 0 # 判断是否存在空的sentence 61 # print(tmp) 62 if idx > small: 63 break 64 65 print('len(words):', len(words)) 66 print('max_seq len:', max_seq) 67 68 for idx, sentence in enumerate(Sentences): 69 print('-' * 80) 70 print(sentence) 71 print(Sentences_tag[idx]) 72 if idx > 5: 73 break 74 75 Train_Sentences, Train_Sentences_tag = [], [] 76 Valid_Sentences, Valid_Sentences_tag = [], [] 77 for i in range(len(Sentences)): 78 if i % fold: 79 Train_Sentences.append(Sentences[i]) 80 Train_Sentences_tag.append(Sentences_tag[i]) 81 else: 82 Valid_Sentences.append(Sentences[i]) 83 Valid_Sentences_tag.append(Sentences_tag[i]) 84 85 loss_fn = nn.CrossEntropyLoss(reduction='none') 86 87 def predict_tag(W, feat_pair2idx, sentence, True_sentence_tag=None): 88 n = len(sentence) 89 tags = ['B', 'I', 'S', 'BOS', 'EOS'] 90 dp = [{'B': 0.0, 'I': 0.0, 'S': 0.0, 'BOS': 0.0, 'EOS': 0.0} for _ in range(n + 1)] 91 pre_tag = [{'B': None, 'I': None, 'S': None, 'BOS': None, 'EOS': None} for _ in range(n + 1)] 92 for t in range(n): 93 w = sentence[t] 94 # print('w:', w) 95 for tg in tags: 96 feat_tag2word = -1e9 if (tg, w) not in feat_pair2idx else W[feat_pair2idx[(tg, w)]] 97 if t == 0: 98 feat_tag2tag = -1e9 if ('BOS', tg) not in feat_pair2idx else W[feat_pair2idx[('BOS', tg)]] 99 dp[t][tg] = feat_tag2word + feat_tag2tag 100 pre_tag[t][tg] = 'BOS' 101 else: 102 max_prob = None 103 best_pre_tag = None 104 for pre_tg in tags: 105 feat_tag2tag = -1e9 if (pre_tg, tg) not in feat_pair2idx else W[feat_pair2idx[(pre_tg, tg)]] 106 tmp = dp[t - 1][pre_tg] + feat_tag2tag + feat_tag2word 107 if max_prob == None or max_prob < tmp: 108 max_prob = tmp 109 best_pre_tag = pre_tg 110 dp[t][tg] = max_prob 111 pre_tag[t][tg] = best_pre_tag 112 113 max_prob = None 114 best_pre_tag = None 115 tg = 'EOS' 116 for pre_tg in tags: 117 feat_tag2tag = -1e9 if (pre_tg, tg) not in feat_pair2idx else W[feat_pair2idx[(pre_tg, tg)]] 118 tmp = dp[n - 1][pre_tg] + feat_tag2tag 119 if max_prob == None or max_prob < tmp: 120 max_prob = tmp 121 best_pre_tag = pre_tg 122 dp[n][tg] = max_prob 123 pre_tag[n][tg] = best_pre_tag 124 125 ans_tag = [] 126 t = n 127 128 # print('#' * 80) 129 # print('sentence:', sentence) 130 # print('True sentence tag:', True_sentence_tag) 131 # print('len(sentence):', len(sentence)) 132 # print('n:', n) 133 134 if True_sentence_tag is not None: 135 True_sentence_tag.append('EOS') 136 sss = sentence + ['END'] 137 while pre_tag[t][tg] is not None: 138 if True_sentence_tag is None: 139 # print('t: {}, pre_tag[t][tg]: {} -> tg: {} -- word:{}'.format( 140 # t, pre_tag[t][tg], tg, sss[t])) 141 pass 142 else: 143 assert len(True_sentence_tag) == n + 1, (n, len(True_sentence_tag)) 144 print('t: {}, pre_tag[t][tg]: {} -> tg: {} -- True tag: {}, -- word: {}'.format( 145 t, pre_tag[t][tg], tg, True_sentence_tag[t], sss[t])) 146 147 ans_tag = [pre_tag[t][tg]] + ans_tag 148 tg = pre_tag[t][tg] 149 t = t - 1 150 151 return ans_tag[1:] # 去掉BOS 152 153 154 def cal_grad_w(W, feat_pair2idx, feat_num, xn, yn): 155 """ 156 O(W, xn, yn) = log p(yn|xn) = log exp(W Phi(xn, yn)) / Sigma exp(W Phi(xn, y')) 157 =W Phi(xn, yn) - log Sigma exp(W Phi(xn, y')) 158 = W Phi(xn, yn) - log Z(xn) 159 W_grad = Phi(xn, yn) - 1 / Z(xn) * Sigma exp(W Phi(xn, y')) Phi(xn, y') 160 然后利用viterbi算法进行求解,实际上就是 O( 序列长度 * tag种类数 ** 2)的动态规划算法 161 我们用到两个东西: 162 1. Z_i(t):表示t时刻为止,tag是i的所有路径的概率之和, 163 i.e., Sigma exp(W Phi(xn(1:t), y'(1:t))) 且y(t) = tag i 164 2. P_i(t): 表示t时刻为止,tag是i的所有路径的【加权】(Phi(xn(1:t), y'(1:t)))概率之和, 165 i.e., Sigma exp(W Phi(xn(1:t), y'(1:t))) Phi(xn(1:t), y'(1:t)) 166 具体状态转移方程见代码, 关键是 167 P_i(t + 1) = exp(W Phi(xn(1:t+1), y'(1:t+1))) Phi(xn(1:t+1), y'(1:t+1)) 168 = exp(W Phi_t) exp (W delta_Phi) * (Phi_t +delta_Phi) 169 = Sigma_{y'(t)} (exp(W Phi_t)Phi_t + delta_Phi) * exp (W delta_Phi) 170 Z_i(t + 1) = Sigma_{y'(t)} Z_i(t) * exp (W delta_Phi) 171 为了数值稳定,可以用log_P和log_Z进行更新 172 如果看不懂上面,可以参考下面的链接(可能还是比较模糊),最好自己推导一边 173 链接1:https://blog.csdn.net/qq_42189083/article/details/89350890 174 链接2:https://blog.csdn.net/weixin_30014549/article/details/52850638 175 """ 176 tags = ['B', 'I', 'S', 'BOS', 'EOS'] 177 Phi = np.zeros(feat_num) 178 pre_P = np.zeros(shape=[5, feat_num]) 179 pre_Z = np.zeros(shape=[5,]) 180 n = len(xn) 181 182 pre_tag = 'BOS' 183 for i in range(n): 184 word, tag = xn[i], yn[i] 185 tag2tag_id = feat_pair2idx[(pre_tag, tag)] 186 tag2word_id = feat_pair2idx[(tag, word)] 187 Phi[tag2tag_id] += 1 188 Phi[tag2word_id] += 1 189 pre_tag = tag 190 191 for i in range(n): 192 word = xn[i] 193 194 P = np.zeros(shape=[5, feat_num]) 195 Z = np.zeros(shape=[5, ]) 196 flag = 0 197 for j, tag in enumerate(tags): 198 for k, pre_tag in enumerate(tags): 199 if i==0 and pre_tag != 'BOS': 200 continue 201 deta_phi = np.zeros(feat_num) 202 tag2tag = (pre_tag, tag) 203 tag2word = (tag, word) 204 if tag2tag not in feat_pair2idx: 205 continue 206 if tag2word not in feat_pair2idx: 207 continue 208 flag = 1 209 tag2tag_id = feat_pair2idx[tag2tag] 210 tag2word_id = feat_pair2idx[tag2word] 211 deta_phi[tag2tag_id] += 1 212 deta_phi[tag2word_id] += 1 213 214 # exp_w_delta_phi = np.exp(np.sum(W * deta_phi)) 215 exp_w_delta_phi = np.exp(W[tag2tag_id] + W[tag2word_id]) 216 217 if i == 0 and pre_tag == 'BOS': 218 pre_Z[k] = 1 219 P[j] += (pre_P[k] + pre_Z[k] * deta_phi) * exp_w_delta_phi 220 Z[j] += pre_Z[k] * exp_w_delta_phi 221 222 # print('P[j, tag2tag_id]:{}, P[j, tag2word_id]:{}'.format(P[j, tag2tag_id], P[j, tag2word_id])) 223 pre_P = P.copy() 224 pre_Z = Z.copy() 225 # print('word: {}, flag: {}'.format(word, flag)) 226 227 P = np.zeros(shape=[feat_num, ]) 228 Z = 0.0 229 tag = 'EOS' 230 for k, pre_tag in enumerate(tags): 231 deta_phi = np.zeros(feat_num) 232 tag2tag = (pre_tag, tag) 233 if tag2tag not in feat_pair2idx: 234 continue 235 tag2tag_id = feat_pair2idx[tag2tag] 236 deta_phi[tag2tag_id] += 1 237 # exp_w_delta_phi = np.exp(np.sum(W * deta_phi)) 238 exp_w_delta_phi = np.exp(W[tag2tag_id]) 239 240 P += (pre_P[k] + pre_Z[k] * deta_phi) * exp_w_delta_phi 241 Z += pre_Z[k] * exp_w_delta_phi 242 # print('pre_P: {} pre_Z: {} '.format(pre_P, pre_Z)) 243 # print('sum(Phi): {} P:{} Z:{}'.format(np.sum(Phi), P, Z)) 244 # print('WPhi: {}, exp(WPhi):{}'.format(np.sum(W * Phi), np.exp(np.sum(W * Phi)))) 245 # print('Phi - P / Z:', Phi - P / Z) 246 W_grad = Phi - P / Z 247 return - W_grad + regulization * W 248 249 def cal_grad_w_log_version(W, feat_pair2idx, feat_num, xn, yn): 250 """ 251 O(W, xn, yn) = log p(yn|xn) = log exp(W Phi(xn, yn)) / Sigma exp(W Phi(xn, y')) 252 =W Phi(xn, yn) - log Sigma exp(W Phi(xn, y')) 253 = W Phi(xn, yn) - log Z(xn) 254 W_grad = Phi(xn, yn) - 1 / Z(xn) * Sigma exp(W Phi(xn, y')) Phi(xn, y') 255 然后利用viterbi算法进行求解,实际上就是 O( 序列长度 * tag种类数 ** 2)的动态规划算法 256 我们用到两个东西: 257 1. Z_i(t):表示t时刻为止,tag是i的所有路径的概率之和, 258 i.e., Sigma exp(W Phi(xn(1:t), y'(1:t))) 且y(t) = tag i 259 2. P_i(t): 表示t时刻为止,tag是i的所有路径的【加权】(Phi(xn(1:t), y'(1:t)))概率之和, 260 i.e., Sigma exp(W Phi(xn(1:t), y'(1:t))) Phi(xn(1:t), y'(1:t)) 261 具体状态转移方程见代码, 关键是 262 P_i(t + 1) = exp(W Phi(xn(1:t+1), y'(1:t+1))) Phi(xn(1:t+1), y'(1:t+1)) 263 = exp(W Phi_t) exp (W delta_Phi) * (Phi_t +delta_Phi) 264 = Sigma_{y'(t)} (exp(W Phi_t)Phi_t + delta_Phi) * exp (W delta_Phi) 265 Z_i(t + 1) = Sigma_{y'(t)} Z_i(t) * exp (W delta_Phi) 266 为了数值稳定,可以用log_P和log_Z进行更新 267 如果看不懂上面,可以参考下面的链接(可能还是比较模糊),最好自己推导一边 268 链接1:https://blog.csdn.net/qq_42189083/article/details/89350890 269 链接2:https://blog.csdn.net/weixin_30014549/article/details/52850638 270 """ 271 tags = ['B', 'I', 'S', 'BOS', 'EOS'] 272 Phi = np.zeros(feat_num) 273 log_pre_P = np.zeros(shape=[5, feat_num]) 274 log_pre_Z = np.zeros(shape=[5,]) 275 n = len(xn) 276 277 pre_tag = 'BOS' 278 for i in range(n): 279 word, tag = xn[i], yn[i] 280 tag2tag_id = feat_pair2idx[(pre_tag, tag)] 281 tag2word_id = feat_pair2idx[(tag, word)] 282 Phi[tag2tag_id] += 1 283 Phi[tag2word_id] += 1 284 pre_tag = tag 285 286 for i in range(n): 287 word = xn[i] 288 289 log_P = np.zeros(shape=[5, feat_num]) + 1e-9 290 log_Z = np.zeros(shape=[5, ]) + 1e-9 291 flag = 0 292 for j, tag in enumerate(tags): 293 for k, pre_tag in enumerate(tags): 294 if i==0 and pre_tag != 'BOS': 295 continue 296 deta_phi = np.zeros(feat_num) 297 tag2tag = (pre_tag, tag) 298 tag2word = (tag, word) 299 if tag2tag not in feat_pair2idx: 300 continue 301 if tag2word not in feat_pair2idx: 302 continue 303 flag = 1 304 tag2tag_id = feat_pair2idx[tag2tag] 305 tag2word_id = feat_pair2idx[tag2word] 306 deta_phi[tag2tag_id] += 1 307 deta_phi[tag2word_id] += 1 308 309 # exp_w_delta_phi = np.exp(np.sum(W * deta_phi)) 310 exp_w_delta_phi = np.exp(W[tag2tag_id] + W[tag2word_id]) 311 312 if i == 0 and pre_tag == 'BOS': 313 log_pre_Z[k] = 0 314 log_P[j] += (np.exp(log_pre_P[k]) + np.exp(log_pre_Z[k]) * deta_phi) * exp_w_delta_phi 315 log_Z[j] += np.exp(log_pre_Z[k]) * exp_w_delta_phi 316 317 # print('P[j, tag2tag_id]:{}, P[j, tag2word_id]:{}'.format(log_P[j, tag2tag_id], log_P[j, tag2word_id])) 318 log_P = np.log(log_P) 319 log_Z = np.log(log_Z) 320 log_pre_P = log_P.copy() 321 log_pre_Z = log_Z.copy() 322 # print('word: {}, flag: {}'.format(word, flag)) 323 324 log_P = np.zeros(shape=[feat_num, ]) 325 log_Z = 0.0 326 tag = 'EOS' 327 for k, pre_tag in enumerate(tags): 328 deta_phi = np.zeros(feat_num) 329 tag2tag = (pre_tag, tag) 330 if tag2tag not in feat_pair2idx: 331 continue 332 tag2tag_id = feat_pair2idx[tag2tag] 333 deta_phi[tag2tag_id] += 1 334 # exp_w_delta_phi = np.exp(np.sum(W * deta_phi)) 335 exp_w_delta_phi = np.exp(W[tag2tag_id]) 336 337 log_P += (np.exp(log_pre_P[k]) + np.exp(log_pre_Z[k]) * deta_phi) * exp_w_delta_phi 338 log_Z += np.exp(log_pre_Z[k]) * exp_w_delta_phi 339 # print('pre_P: {} pre_Z: {} '.format(pre_P, pre_Z)) 340 # print('sum(Phi): {} P:{} Z:{}'.format(np.sum(Phi), P, Z)) 341 # print('WPhi: {}, exp(WPhi):{}'.format(np.sum(W * Phi), np.exp(np.sum(W * Phi)))) 342 # print('Phi - P / Z:', Phi - P / Z) 343 W_grad = Phi - log_P / log_Z 344 return - W_grad + regulization * W 345 346 def evaluate(W, feat_pair2idx, Sentences_, Sentences_tag_): 347 cnt_correct_tag, cnt_total_tag = 0.0, 0.0 348 for i, sentence in enumerate(Sentences_): 349 sentence_tag = Sentences_tag_[i] 350 sentence_tag_pred = predict_tag(W, feat_pair2idx, sentence) 351 assert len(sentence_tag) == len(sentence_tag_pred) 352 # predict_tag(sentence=Sentences[0], True_sentence_tag=None) 353 # print('sentence_tag == sentence_tag_pred:', [sentence_tag[_] == sentence_tag_pred[_] for _ in range(len(sentence))]) 354 cnt_correct_tag += np.sum([sentence_tag[_] == sentence_tag_pred[_] for _ in range(len(sentence))]) 355 cnt_total_tag += len(sentence) 356 # for j, w in enumerate(sentence): 357 # print('w:{} -> true_tag:{} -> pred_tag:{}'.format(w, sentence_tag[j], sentence_tag_pred[j])) 358 # break 359 acc = cnt_correct_tag / cnt_total_tag 360 # print('cnt_correct_tag, cnt_total_tag:', cnt_correct_tag, cnt_total_tag) 361 # print('acc:', acc) 362 return acc 363 364 def train(Train_Sentences, Train_Sentences_tag): 365 ''' 366 :param Train_Sentences: 367 :param Train_Sentences_tag: 368 p(Sentences_tag, Sentences) ~ exp(w^T f(Sentences_tag, Sentences)), w是待train的权重,f是特征函数 369 :return: 370 ''' 371 N = len(Train_Sentences) 372 def get_feature_dict(): 373 feat_pair2idx = {} 374 feat_idx2pair = {} 375 feat_num = 0 376 for i in range(N): 377 sentence = Train_Sentences[i] 378 sentence_tag = Train_Sentences_tag[i] 379 n = len(sentence) 380 pre_tg = 'BOS' 381 for i in range(n): 382 tg, w = sentence_tag[i], sentence[i] 383 if (tg, w) not in feat_pair2idx: 384 feat_pair2idx[(tg, w)] = feat_num 385 feat_idx2pair[feat_num] = (tg, w) 386 feat_num += 1 387 if (pre_tg, tg) not in feat_pair2idx: 388 feat_pair2idx[(pre_tg, tg)] = feat_num 389 feat_idx2pair[feat_num] = (pre_tg, tg) 390 feat_num += 1 391 pre_tg = tg 392 tg = 'EOS' 393 if (pre_tg, tg) not in feat_pair2idx: 394 feat_pair2idx[(pre_tg, tg)] = feat_num 395 feat_idx2pair[feat_num] = (pre_tg, tg) 396 feat_num += 1 397 return feat_pair2idx, feat_idx2pair, feat_num 398 399 feat_pair2idx, feat_idx2pair, feat_num = get_feature_dict() 400 print('{} {} {} '.format(feat_pair2idx, feat_idx2pair, feat_num)) 401 402 if reused_W: 403 W = np.load(filepath) 404 else: 405 W = np.random.normal(0, scale=1.0 / np.sqrt(feat_num), size=[feat_num, ]) 406 # tag, tag2word, tag2tag = {}, {}, {} 407 # tag['BOS'] = N 408 # tag['EOS'] = N 409 Train_Acc, Valid_Acc = [], [] 410 time_global = time.time() 411 for epoch in range(N_epoch): 412 time_epoch = time.time() 413 s = '###' 414 415 for i in range(N): 416 if i % (N // 10)==0: 417 s_out = s * (i // (N // 10)) + '{}/{} running this epoch time used: {:.2f}'.format(i, N, time.time() - time_epoch) 418 if i // (N // 10) == 10: 419 print(s_out, end="", flush=False) 420 else: 421 print(s_out, end=" ", flush=True) 422 sentence = Train_Sentences[i] 423 sentence_tag = Train_Sentences_tag[i] 424 n = len(sentence) 425 assert len(sentence) == len(sentence_tag) 426 assert n > 0 427 W_grad = cal_grad_w(W, feat_pair2idx, feat_num, xn=sentence, yn=sentence_tag) 428 # W_grad = cal_grad_w_log_version(W, feat_pair2idx, feat_num, xn=sentence, yn=sentence_tag) 429 430 W -= lr * W_grad 431 train_acc = evaluate(W, feat_pair2idx, Sentences_=Train_Sentences, Sentences_tag_=Train_Sentences_tag) 432 valid_acc = evaluate(W, feat_pair2idx, Sentences_=Valid_Sentences, Sentences_tag_=Valid_Sentences_tag) 433 Train_Acc.append(train_acc) 434 Valid_Acc.append(valid_acc) 435 print(' epoch: {}, epoch time: {}, global time: {}, train acc: {}, valid acc: {}'.format( 436 epoch, time.time() - time_epoch, time.time() - time_global, train_acc, valid_acc)) 437 438 if show_acc: 439 plt.figure() 440 plt.title('regulization: {}'.format(regulization)) 441 plt.plot(Train_Acc, label='Train Acc') 442 plt.plot(Valid_Acc, label='Valid Acc') 443 444 445 446 return W, feat_pair2idx 447 448 REG = [0, 0.1, 0.3, 1, 3, 10, 30] 449 for reg in REG: 450 regulization = reg 451 W, feat_pair2idx = train(Train_Sentences, Train_Sentences_tag) 452 break 453 plt.show() 454 if not os.path.exists(check_path): 455 os.makedirs(check_path) 456 np.save(filepath, W) 457 458 # predict_tag(W, feat_pair2idx, sentence=Sentences[0], True_sentence_tag=None) 459 460 predict_tag(W, feat_pair2idx, sentence=Sentences[0], True_sentence_tag=Sentences_tag[0]) 461 # predict_tag(sentence=Sentences[0], True_sentence_tag=None) 462 463 464 def fenci_example(W, feat_pair2idx): 465 466 test_sentences = [ 467 '我是中国人,我爱祖国', 468 '独行侠队的球员们承诺每天为达拉斯地区奋战在抗疫一线的工作人员们提供餐食', 469 '汤普森太爱打球,不能出场让他很煎熬', 470 '这个赛季对克莱来说非常艰难,他太热爱打篮球了,无法上场让他很受打击。', 471 '克莱和斯蒂芬会处在极佳的状态,准备好比赛。', 472 '勇士已经证明了他们也是一支历史级别的球队,维金斯在稍强于巴恩斯的前提下,仍然算得上是三号位上一位合格的替代者' 473 ] 474 475 np.set_printoptions(precision=3, suppress=True) 476 477 for sentence in test_sentences: 478 print('-' * 80) 479 print('test word : {}'.format(sentence)) 480 sentence = [w for w in sentence] 481 sentence_tag = predict_tag(W, feat_pair2idx, sentence) 482 # predict_tag(sentence=Sentences[0], True_sentence_tag=None) 483 for i, w in enumerate(sentence): 484 print('{} -> {}'.format(w, sentence_tag[i])) 485 486 fenci_example(W, feat_pair2idx) 487 488 print('end!!!') 489 ''' 490 test word : 独行侠队的球员们承诺每天为达拉斯地区奋战在抗疫一线的工作人员们提供餐食 491 独 -> B 492 行 -> I 493 侠 -> B 494 队 -> I 495 的 -> S 496 球 -> B 497 员 -> I 498 们 -> I 499 承 -> B 500 诺 -> I 501 每 -> B 502 天 -> I 503 为 -> B 504 达 -> I 505 拉 -> B 506 斯 -> I 507 地 -> B 508 区 -> I 509 奋 -> B 510 战 -> I 511 在 -> S 512 抗 -> B 513 疫 -> I 514 一 -> B 515 线 -> I 516 的 -> S 517 工 -> B 518 作 -> I 519 人 -> S 520 员 -> B 521 们 -> I 522 提 -> B 523 供 -> I 524 餐 -> B 525 食 -> I 526 '''
BILSTM+CRF, PS:为了实现方便,没有加start和end的转移分数权重
1 import numpy as np 2 import torch 3 import torch.nn as nn 4 import torch.nn.functional as F 5 from torch.utils.data import DataLoader, Dataset 6 import os 7 import time 8 import matplotlib.pyplot as plt 9 from p03_CRF_layer import CRF_zqx 10 # from CRF_official import CRF as CRF_zqx 11 12 np.random.seed(1) 13 torch.manual_seed(1) 14 np.set_printoptions(precision=5, suppress=3) 15 device = 'cuda' if torch.cuda.is_available() else 'cpu' 16 # device = 'cpu' 17 print('device:', device) 18 device = torch.device(device) 19 20 small = 50 21 training = True 22 show_loss = True 23 N_epoch = 5 24 Batch_size = 64 25 show_epoch = 1 26 H = 128 27 em_dim = 100 28 lr = 1e-2 29 fold=0 30 net = 'BiLSTM_CRF' 31 tag_num = 3 32 33 words = {} 34 max_seq = 0 35 36 label2idx = {'B': 0, 'I': 1, 'S': 2} 37 idx2label = {0: 'B', 1: 'I', 2: 'S'} 38 39 Sentences = [] 40 Sentences_label = [] 41 Sentences_origin = [] 42 43 with open('zhihu.txt', mode='r', encoding='utf8') as f: 44 lines = f.readlines() 45 print('len(lines):', len(lines)) 46 for idx, line in enumerate(lines): 47 # print(line) 48 line = line.split() 49 tmp = [] 50 mmp = [] 51 for word in line: 52 if len(word)==1: 53 mmp.append(label2idx['S']) 54 else: 55 mmp.append(label2idx['B']) 56 for _ in range(1, len(word)): 57 mmp.append(label2idx['I']) 58 59 for w in word: 60 if w in words: 61 words[w] += 1 62 else: 63 words[w] = 1 64 tmp.append(w) 65 Sentences.append(tmp) 66 Sentences_label.append(mmp) 67 max_seq = max(max_seq, len(tmp)) 68 assert len(mmp)==len(tmp) 69 # print(tmp) 70 if idx > small: 71 break 72 73 74 Sentences.sort(key=lambda x: len(x), reverse=True) 75 Sentences_label.sort(key=lambda x: len(x), reverse=True) 76 # for sentence in Sentences: 77 # print(sentence) 78 print('len(words):', len(words)) 79 # print(words) 80 print('max_seq len:', max_seq) 81 82 # print(words) 83 word2index = {word: idx + 1 for idx, word in enumerate(words.keys())} 84 indx2word = {idx + 1: word for idx, word in enumerate(words.keys())} 85 86 87 voc_size = len(words) + 1 88 word2index['<pad>'] = 0 89 indx2word[0] = '<pad>' 90 91 Sentences_idx, Sentences_len = [], [] 92 for sentence in Sentences: 93 tmp=[] 94 for w in sentence: 95 tmp.append(word2index[w]) 96 Sentences_idx.append(torch.LongTensor(tmp)) 97 Sentences_len.append(len(tmp)) 98 # print(tmp) 99 Sentences_idx = torch.nn.utils.rnn.pad_sequence(Sentences_idx,batch_first=True) 100 # print('-' * 80) 101 # print(Sentences_idx.size()) 102 # print(Sentences_idx) 103 104 105 # print('-' * 80) 106 Sentences_label_idx = [] 107 for i, sentences_label in enumerate(Sentences_label): 108 tmp = torch.LongTensor(sentences_label) 109 Sentences_label_idx.append(tmp) 110 # print(Sentences[i]) 111 # # print(lines[i]) 112 # print(tmp) 113 assert len(tmp) == len(Sentences[i]) 114 Sentences_label_idx = torch.nn.utils.rnn.pad_sequence(Sentences_label_idx,batch_first=True,padding_value=0) 115 # print('Sentences_label_idx:') 116 # print(Sentences_label_idx) 117 118 # a = torch.tensor(1.0) 119 # print(a) 120 # print(a.size()) 121 class MyDataSet(Dataset): 122 def __init__(self, data, lens, labels): 123 self.data = data 124 self.lens = lens 125 self.labels = labels 126 def __getitem__(self, idx): 127 now_data = self.data[idx] 128 now_len = self.lens[idx] 129 now_mask = [] 130 now_label = self.labels[idx] 131 for i in range(len(now_data)): 132 t = 1.0 if i < now_len else 0.0 133 now_mask.append(t) 134 now_mask = torch.Tensor(now_mask) 135 # now_mask = torch.BoolTensor(now_mask) #用官方CRF的格式要求 136 return now_data, now_len, now_mask, now_label 137 def __len__(self): 138 return len(self.data) 139 140 class FenCi_Zqx(nn.Module): 141 def __init__(self, voc_size, em_dim, H): 142 super(FenCi_Zqx, self).__init__() 143 self.emd = nn.Embedding(num_embeddings=voc_size,embedding_dim=em_dim) 144 if net == 'LSTM': 145 self.rnn = nn.LSTM(input_size=em_dim,hidden_size=H,num_layers=1,batch_first=True) 146 self.linear = nn.Linear(in_features=H,out_features=3) 147 if 'BiLSTM' in net: 148 self.rnn = nn.LSTM(input_size=em_dim, hidden_size=H, num_layers=1, batch_first=True,bidirectional=True) 149 self.linear = nn.Linear(in_features=2*H, out_features=3) 150 self.loss_fn = CRF_zqx(tag_num=tag_num) 151 def forward(self, sentence, sentence_len=None, mask=None): 152 emd = self.emd(sentence) # (batch, seq_len, em_dim) 153 all_h, (h, c) = self.rnn(emd) # LSTM: (batch, seq_len, H) BiLSTM: (batch, seq_len, 2*H) 154 # print('emd size:', emd.size()) 155 # print('all_h.size():', all_h.size()) 156 # out = all_h.view(-1, all_h.size(2)) # (batch * seq_len, H) 157 out = self.linear(all_h).view(emd.size(0), emd.size(1), 3) # (batch, seq_len, 3) 158 # print('out size:', out.size()) 159 return out 160 161 Sentences_len = torch.Tensor(Sentences_len) 162 train_idx = [i for i in range(len(Sentences_len)) if i % 5 == fold] 163 test_idx = [i for i in range(len(Sentences_len)) if i % 5 != fold] 164 print(train_idx, ' ', test_idx) 165 Train_Sentences_idx, Train_Sentences_len, Train_Sentences_label_idx = 166 Sentences_idx[train_idx], Sentences_len[train_idx], Sentences_label_idx[train_idx] 167 Test_Sentences_idx, Test_Sentences_len, Test_Sentences_label_idx = 168 Sentences_idx[test_idx], Sentences_len[test_idx], Sentences_label_idx[test_idx] 169 Train_data = MyDataSet(Train_Sentences_idx, Train_Sentences_len, Train_Sentences_label_idx) 170 Train_data_loader = DataLoader(dataset=Train_data, batch_size=Batch_size, shuffle=True) 171 Test_data = MyDataSet(Test_Sentences_idx, Test_Sentences_len, Test_Sentences_label_idx) 172 Test_data_loader = DataLoader(dataset=Test_data, batch_size=Batch_size, shuffle=False) 173 174 model = FenCi_Zqx(voc_size=voc_size, em_dim=em_dim, H=H) 175 # loss_fn = nn.CrossEntropyLoss(reduction='none') 176 # loss_fn = CRF_zqx(tag_num=tag_num) 177 opt = torch.optim.Adam(model.parameters(), lr=lr) 178 179 print('Sentences_idx, Sentences_len, Sentences_label_idx shape') 180 print(len(Sentences_idx), len(Sentences_len), len(Sentences_label_idx)) 181 print(Sentences_idx.size(), Sentences_len.size(), Sentences_label_idx.size()) 182 print(Sentences_idx.shape, Sentences_len.shape, Sentences_label_idx.shape) 183 print('#' * 60) 184 print(model) 185 186 def valid(model): 187 # model.to(device) 188 # model.eval() 189 with torch.no_grad(): 190 avg_loss = 0 191 cnt=0 192 for batch_step, (now_data, now_len, now_mask, now_label) in enumerate(Test_data_loader): 193 cnt += 1 194 now_data, now_len, now_mask, now_label = 195 now_data.to(device), now_len.to(device), now_mask.to(device), now_label.to(device) 196 out = model(now_data, now_len, now_mask) 197 # out = out.view(-1, 3) 198 # now_mask = now_mask.view(-1) 199 # now_label = now_label.view(-1) 200 201 loss = model.loss_fn(out, now_label, now_mask) 202 # print('loss size:', loss.size()) 203 # print(out.size(), now_label.size(), now_mask.size()) 204 # loss = torch.mean(loss * now_mask) 205 avg_loss += loss.item() 206 # print('loss size:', loss.size()) 207 # print('loss:', loss.item()) 208 209 avg_loss /= cnt 210 return avg_loss 211 212 213 def train(model): 214 print('start training:') 215 model.to(device) 216 time_st_global = time.time() 217 Train_loss,Valid_loss = [], [] 218 print(model.loss_fn.A) 219 # print(model.loss_fn.transitions) 220 for epoch in range(N_epoch): 221 time_st_epoch = time.time() 222 avg_loss = 0 223 cnt = 0 224 for batch_step, (now_data, now_len, now_mask, now_label) in enumerate(Train_data_loader): 225 cnt += 1 226 now_data, now_len, now_mask, now_label = 227 now_data.to(device), now_len.to(device), now_mask.to(device), now_label.to(device) 228 out = model(now_data, now_len, now_mask) 229 # out = out.view(-1, 3) 230 # now_mask = now_mask.view(-1) 231 # now_label = now_label.view(-1) 232 loss = model.loss_fn(out, now_label, now_mask) 233 # print('loss size:', loss.size()) 234 # print(out.size(), now_label.size(), now_mask.size()) 235 # loss = torch.mean(loss * now_mask) 236 avg_loss += loss.item() 237 # print('loss size:', loss.size()) 238 # print('loss:', loss.item()) 239 240 opt.zero_grad() 241 loss.backward() 242 opt.step() 243 avg_loss /= cnt 244 valid_avg_loss = valid(model) 245 print('#' * 80) 246 print('epoch:{}, steps: {}, train avg loss: {} -- valid avg loss : {} '.format(epoch, cnt, avg_loss, valid_avg_loss)) 247 print('epoch time {:.2f} s, total time {:.2f} s'.format(time.time() - time_st_epoch, 248 time.time() - time_st_global)) 249 if len(Valid_loss)==0 or valid_avg_loss < min(Valid_loss): 250 if not os.path.exists(check_path): 251 os.makedirs(check_path) 252 torch.save(model.state_dict(), filepath) 253 254 Train_loss.append(avg_loss) 255 Valid_loss.append(valid_avg_loss) 256 257 print(model.loss_fn.A) 258 # print(model.loss_fn.transitions) 259 if show_loss: 260 plt.figure() 261 plt.plot(Train_loss,label='Train loss') 262 plt.plot(Valid_loss, label='Valid loss') 263 plt.legend() 264 plt.savefig('Train_Valid_loss' + net + '.png') 265 # plt.show() 266 267 return model 268 269 # break 270 271 check_path = './Checkpoints/' 272 filepath = check_path + 'p03_Fenci_state_dict_' + net + ' .pkl' 273 274 if training: 275 model = train(model) 276 277 278 # 模型恢复 279 model.load_state_dict(torch.load(filepath)) 280 281 282 test_words = [ 283 '我是中国人,我爱祖国', 284 '独行侠队的球员们承诺每天为达拉斯地区奋战在抗疫一线的工作人员们提供餐食', 285 '汤普森太爱打球,不能出场让他很煎熬', 286 '这个赛季对克莱来说非常艰难,他太热爱打篮球了,无法上场让他很受打击。', 287 '克莱和斯蒂芬会处在极佳的状态,准备好比赛。', 288 '勇士已经证明了他们也是一支历史级别的球队,维金斯在稍强于巴恩斯的前提下,仍然算得上是三号位上一位合格的替代者' 289 ] 290 291 np.set_printoptions(precision=3, suppress=True) 292 model.cpu() 293 model.eval() 294 for word in test_words: 295 print('-' * 80) 296 print('test word : {}'.format(word)) 297 word_idx = [word2index[w] for w in word] 298 word_idx = torch.LongTensor([word_idx]) 299 # print('word_idx.size():', word_idx.size()) 300 # word_idx.to(device) 301 out = model(word_idx) 302 303 # out = model.loss_fn.decode(emissions=out, mask=None) 304 out = model.loss_fn.decode(y_pred=out, mask=None) 305 out_label = out[0] 306 307 308 # # print('out.size():', out.size()) 309 # out = out.squeeze(0).cpu().detach().numpy() 310 # # print('out.shape():', out.shape) 311 # 312 # out_label = np.argmax(out, axis=1) 313 # # print(out_label) 314 315 for i, w in enumerate(word): 316 print('{} -> {} -> {}'.format(w, idx2label[out_label[i]], out_label[i])) 317 318 print('end!!!') 319 ''' 320 test word : 勇士已经证明了他们也是一支历史级别的球队,维金斯在稍强于巴恩斯的前提下,仍然算得上是三号位上一位合格的替代者 321 勇 -> B -> 0 322 士 -> I -> 1 323 已 -> B -> 0 324 经 -> I -> 1 325 证 -> B -> 0 326 明 -> I -> 1 327 了 -> S -> 2 328 他 -> B -> 0 329 们 -> I -> 1 330 也 -> S -> 2 331 是 -> S -> 2 332 一 -> S -> 2 333 支 -> S -> 2 334 历 -> B -> 0 335 史 -> I -> 1 336 级 -> B -> 0 337 别 -> I -> 1 338 的 -> S -> 2 339 球 -> B -> 0 340 队 -> I -> 1 341 , -> S -> 2 342 维 -> B -> 0 343 金 -> I -> 1 344 斯 -> I -> 1 345 在 -> S -> 2 346 稍 -> B -> 0 347 强 -> I -> 1 348 于 -> S -> 2 349 巴 -> B -> 0 350 恩 -> I -> 1 351 斯 -> I -> 1 352 的 -> S -> 2 353 前 -> B -> 0 354 提 -> I -> 1 355 下 -> S -> 2 356 , -> S -> 2 357 仍 -> B -> 0 358 然 -> I -> 1 359 算 -> S -> 2 360 得 -> S -> 2 361 上 -> S -> 2 362 是 -> S -> 2 363 三 -> S -> 2 364 号 -> S -> 2 365 位 -> S -> 2 366 上 -> S -> 2 367 一 -> S -> 2 368 位 -> S -> 2 369 合 -> B -> 0 370 格 -> I -> 1 371 的 -> S -> 2 372 替 -> B -> 0 373 代 -> I -> 1 374 者 -> I -> 1 375 376 377 '''
附上自己写的CRF模块以及公式注解

1 import torch 2 import torch.nn as nn 3 import numpy as np 4 np.random.seed(1) 5 torch.manual_seed(1) 6 7 class CRF_zqx(nn.Module): 8 def __init__(self, tag_num): 9 super(CRF_zqx, self).__init__() 10 # A为转移矩阵, A_ij, 表示tag i 到 tag j 的得分 11 # self.A = torch.rand(size=(tag_num, tag_num), requires_grad=True) 12 # self.A = nn.Parameter(torch.rand(size=(tag_num, tag_num))) 13 self.A = nn.Parameter(torch.empty(tag_num, tag_num)) 14 self.tag_num = tag_num 15 self.reset_parameters() 16 def reset_parameters(self) -> None: 17 """Initialize the transition parameters. 18 19 The parameters will be initialized randomly from a uniform distribution 20 between -0.1 and 0.1. 21 """ 22 nn.init.uniform_(self.A, -0.1, 0.1) 23 24 def forward(self, y_pred, y_true, mask): 25 if len(y_true.size()) < 3: 26 # print(y_true.dtype) 27 y_true = torch.nn.functional.one_hot(y_true, num_classes=self.tag_num) 28 y_true = y_true.type(torch.float32) 29 # y_pred, y_true: [batch_size, seq_len, tag_num], ps:y_true是one-hot向量 30 # log p(y_true | x_true) = log {exp(score(y_true, x_true) / Sigma_y exp(score(y, x_true))} 31 # = score(y_true, x_true) - log sum_y exp(score(y, x_true)) 32 # print('forward: ') 33 # print('y_pred:{} y_true:{} mask:{} '.format(y_pred, y_true, mask)) 34 # print('y_pred:{} y_true:{} mask:{} '.format(y_pred.size(), y_true.size(), mask.size())) 35 # print('A:', self.A) 36 loss = self.score(y_pred, y_true, mask) - self.log_sum_exp(y_pred, mask) 37 return torch.mean(-loss) 38 39 def score(self, y_pred, y_true, mask): 40 # y_pred, y_true: [batch_size, seq_len, tag_num] mask: [batch_size, seq_len] 41 mask = torch.unsqueeze(mask, dim=2) # mask: [batch_size, seq_len, 1] 42 # print('y_pred, y_true, mask size:', y_pred.size(), y_true.size(), mask.size()) 43 score_word2tag = torch.sum(y_pred * y_true * mask, dim=[1, 2]) # 计算word2tag的分数,得到[batch_size, ]向量 44 # [batch_size, seq_len-1, tag_num, 1] * [batch_size, seq_len-1, 1, tag_num] 45 # 从而获得[batch_size, seq_len-1, tag_num, tag_num], 后两个维度都是one-hot向量,分别表示tag2tag的转移矩阵A的index 46 score_tag2tag = torch.unsqueeze(y_true[:, :-1, :] * mask[:, :-1, :], dim=3) 47 * torch.unsqueeze(y_true[:, 1:, :] * mask[:, 1:, :], dim=2) 48 49 # [batch_size, seq_len-1, tag_num, tag_num] * [1, 1, tag_num, tag_num] 50 A = torch.unsqueeze(torch.unsqueeze(self.A, 0), 0) 51 score_tag2tag = score_tag2tag * A 52 score_tag2tag = torch.sum(score_tag2tag, dim=[1, 2, 3]) # [batch_size,] 53 score_ = score_word2tag + score_tag2tag 54 # print('score_ size:', score_.size()) 55 # print('score:', score_) 56 return score_ 57 58 def log_sum_exp(self, y_pred, mask): 59 # mask: [batch_size, seq_len] 60 seq_len = y_pred.size(1) 61 pre_log_Z = y_pred[:, 0, :] # [batch_size, tag_num], initial: log Z = log exp(y_pred[time_step=0]) = y_pred[:, 0 , :] 62 63 # print('pre_log_Z:{}, with size:{}'.format(pre_log_Z, pre_log_Z.size())) 64 for i in range(1, seq_len): 65 # print('i:', i) 66 # [1, tag_num, tag_num] + [batch_size, tag_num, 1] = [batch_size, tag_num, tag_num] 67 # 然后对列(dim=1)求logsumexp, 得到[batch_size, tag_num] 68 tmp = pre_log_Z.unsqueeze(2) 69 # log_Z = torch.logsumexp(tmp + self.A + y_pred[:, i:i+1, :], dim=1) 70 log_Z = torch.logsumexp(torch.unsqueeze(self.A, 0) + torch.unsqueeze(pre_log_Z, 2), dim=1) + y_pred[:, i, :] 71 log_Z = mask[:, i:i+1] * log_Z + (1 - mask[:, i:i+1]) * pre_log_Z # 现在mask位置上是1,则更新, 如果是0,则取用pre_log_Z的值 72 pre_log_Z = log_Z.clone() 73 # print('log_Z size:', pre_log_Z.size()) 74 75 # print('res:', pre_log_Z) 76 res = torch.logsumexp(pre_log_Z,dim=1) # 是logsumexp 不是 sum, debug了大半天!!!! 77 # print('logsumexp:', res) 78 return res 79 80 def decode(self,y_pred, mask=None): 81 batch, seq_len = y_pred.size(0), y_pred.size(1) 82 if mask is None: 83 mask = torch.ones(size=[batch, seq_len]) 84 85 pre_dp = y_pred[:, 0, :] #[batch, tag_num] 86 dp_best_idx = torch.LongTensor(torch.zeros(size=[batch, seq_len + 1, self.tag_num], dtype=torch.long) - 1) 87 for i in range(1, seq_len): # from to 88 now_pred = y_pred[:, i:i+1, :] # [batch, 1, tag_num] 89 pre_dp = torch.unsqueeze(pre_dp, 2) # [batch, tag_num, 1 ] 90 A = torch.unsqueeze(self.A, 0) # [1, tag_num, tag_num] 91 dp, idx = torch.max(pre_dp + A + now_pred, dim=1) # dp: [batch, tag_num] 92 # print('dp:{}, idx:{}'.format(dp.size(), idx.size())) 93 dp_best_idx[:, i, :] = idx 94 pre_dp = dp.clone() 95 96 best_value, last_tag = torch.max(pre_dp, dim=1) 97 print('pre_dp:{}, pre_dp size:{} pointer:{}, last_tag size:{}'.format(pre_dp, pre_dp.size(), last_tag, last_tag.size())) 98 last_tag = list(last_tag.cpu().detach().numpy()) 99 dp_best_idx = dp_best_idx.cpu().detach().numpy() 100 print('last tag:', last_tag) 101 ans = [last_tag] # [batch] 102 i = seq_len - 1 103 while i: 104 tmp = dp_best_idx[:, i, :] 105 pre_tag = [] 106 for j in range(batch): 107 pre_tag.append(tmp[j, last_tag[j]]) 108 last_tag = pre_tag.copy() 109 ans = [pre_tag] + ans 110 i -= 1 111 ans = np.array(ans) #[seq_len, batch] 112 ans = ans.transpose() 113 print('ans:', ans) 114 # while i: 115 # print('dp_best_idx[:, i, :] size:{}, pointer.unsqueeze(1) size:{}'.format( 116 # dp_best_idx[:, i, :].size(), pointer.unsqueeze(1).size())) 117 # print('dp_best_idx[:, i, :]:{}, pointer.unsqueeze(1):{}'.format( 118 # dp_best_idx[:, i, :], pointer.unsqueeze(1))) 119 # pointer = dp_best_idx[:, i, :][pointer.unsqueeze(1)] # pointer.unsqueeze(1): [batch, 1] 120 # ans = [list(pointer)] + ans 121 # i = i - 1 122 123 return ans 124 125 if __name__=='__main__': 126 batch = 1 127 seq_len = 3 128 tag_num = 2 129 y_pred = torch.rand(size=[batch, seq_len, tag_num]) 130 y_true = torch.randint(0, tag_num, size=[batch, seq_len]) 131 # print(y_true) 132 y_true = torch.nn.functional.one_hot(y_true, num_classes=tag_num) 133 y_true = y_true.type(torch.float32) 134 # print(y_true) 135 # print(y_true.size()) 136 mask = [] 137 for _ in range(batch): 138 tmp = np.random.randint(2, seq_len) 139 mask.append([1] * tmp + [0] * (seq_len - tmp)) 140 mask = torch.Tensor(mask) 141 # print(mask) 142 model =CRF_zqx(tag_num=tag_num) 143 144 145 146 # print('y_pred:{} y_true:{} mask:{} '.format(y_pred, y_true, mask)) 147 # print(type(y_pred)) 148 # print(type(y_true)) 149 # print(type(mask)) 150 # print(y_pred.dtype) 151 # print(y_true.dtype) 152 # print(mask.dtype) 153 154 print('y_pred=y_pred, y_true=y_true, mask=mask:', y_pred.size(), y_true.size(), mask.size()) 155 loss = model(y_pred=y_pred, y_true=y_true, mask=mask) 156 print('loss: {}'.format(loss)) 157 158 159 ''' 160 y_pred:tensor([[[0.7576, 0.2793], 161 [0.4031, 0.7347]]]) 162 y_true:tensor([[[0., 1.], 163 [0., 1.]]]) 164 mask:tensor([[1., 0.]]) 165 166 '''
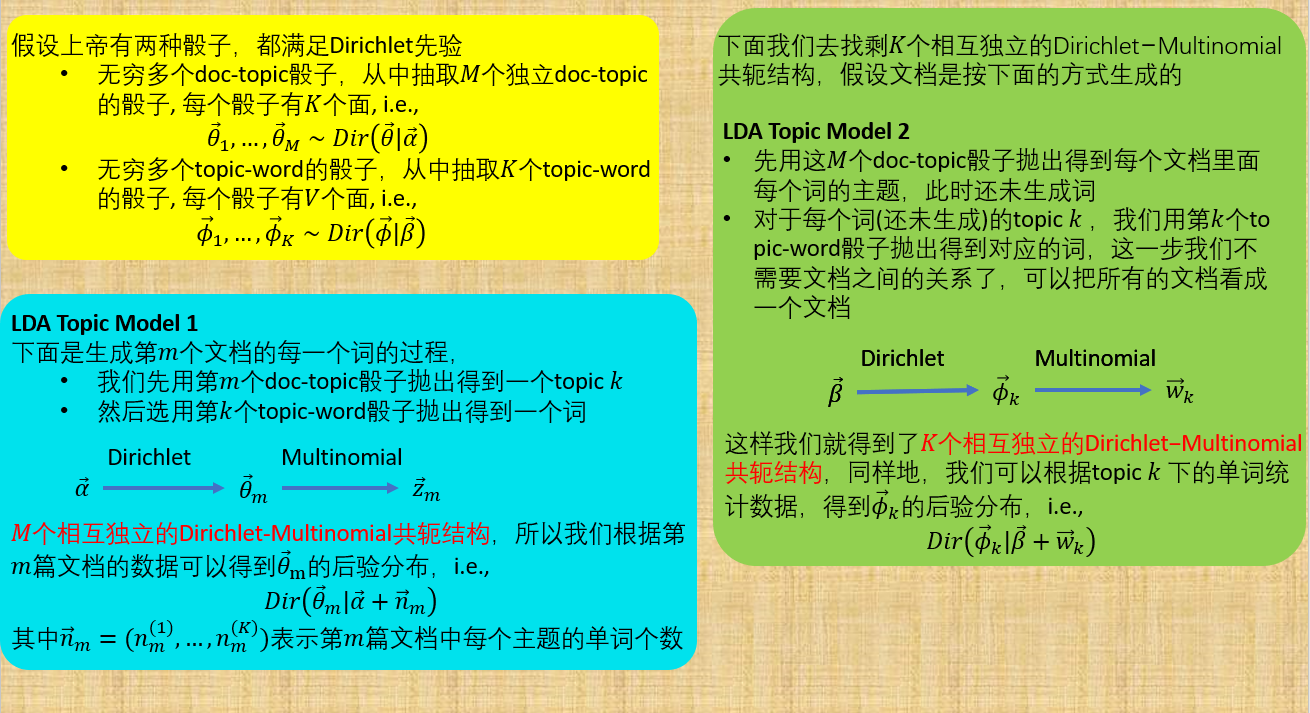
LDA 模型(具体请看LDA数学八卦)