转自:https://www.cnblogs.com/asis/p/cache-pattern.html
如今缓存是随处可见了,如果你的程序还没有使用到缓存,那可能是你的程序并发量很低,或对实时性要求很低。我们公司的ERP在显示某些报表时,每次打开都需要花上几分钟的时间,假如搜索引擎也是这么慢,我想这家搜索引擎早就被淘汰了。
这些ERP报表是否该引入缓存加速一下呢……
使用缓存,就是在取出数据结果后,暂时将数据存储在某些可以快速存取的位置(例如各种NoSQL如Redis,HBase,又或MemoryCache等等),于是就可以让这些耗时的数据结果多次重复的利用,不必每次重复请求相同的数据,节省CPU和I/O,加速程序的响应。
使用缓存能让加载数据的延迟降低,I/O操作减少,从而性能得到提高。
缓存使用起来很容易,但是保持缓存的一致性却困难得多。有一些前人总结的经验和方法,我们可以借鉴一下。
缓存重点在于写入的时候,相关数据的更新问题,如果数据一直没有更新或删除操作,那缓存就不会存在脏数据一说了。
关于缓存写入,至少有4种写入的策略。
write-through
这个动作发生在Cache层。是指在写数据时,同时写入到缓存和DB中,这个写入操作认为是一个单一的事务,也就是说,在更新Cache时,我们先更新了Cache中的数据,然后接着更新Db中的数据。在DB的数据完成更新前,程序还不会返回,一直等到数据库存储的结果。可想而知,这种做法不会给写入数据带来更高的性能。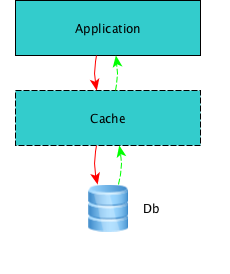
我用向下的箭头表示一个函数的调用,绿色的虚线表示函数的返回,我拙劣的语言能力还难以描述清楚,但如果把这个图写成程序,就像这个样子:
public class UserLogic
{
public void WriteToDb(UserEntity user)
{
CacheManager cache = GetCacheManager();
cache.WriteToDb(user);
}
}
public class CacheManager
{
public void WriteToDb(UserEntity user)
{
cacheStore.Set(user.cacheKey, user.ToJson());
dbManager.UpdateSqlServer(user);
}
}UserLogic类放在Cache层之上,非Cache层,比如应用层、领域层、某某逻辑层之类……,它的WriteToDb函数内部并没有关于Db执行的代码,它不关心Db,它直接调用了Cache层的CacheManager的WriteToDb()。CacheManager.WriteToDb()内部先去更新了Cache,然后并没有立刻返回,接着又将user写入了MSSQL里面。
所以我说,这种做法不会给写入数据带来更高的性能。
write-around
发生在Cache层,直接写入数据到数据库,不必写到缓存中。这个不必过多的解释,缓存的数据应该被立即过期(否则数据就会不一致了)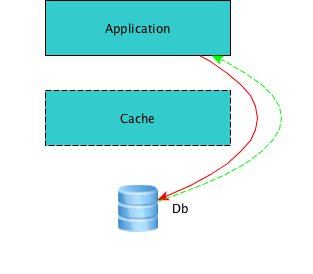
当我写这篇文章的时候,发现确实伪代码比我无力的中文解释更清晰,那么write-around的伪代码呢?
public class UserLogic
{
public void WriteToDb(UserEntity user)
{
cacheStore.Invalidate(user.caheKey);
dbManager.UpdateSqlServer(user);
}
}应用层绕过了Cache层,直接调用Db写入了数据库。
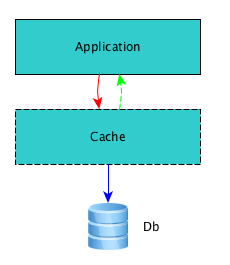
write-behind
还是发生在Cache层,刚开始时,写入到缓存中,当设定的缓存容量达到上限,或等到一定的时间间隔后,再写到数据库中。
换句话说,写入到数据库是有条件的。当我们要存入数据库时,一定是有一批数据甚至是一大批数据都需要从缓存中写到数据库中。我们想象这是一个写入的队列,要写入的数据源源不断的放入到这个队列中。此时,我们可以使用服务器上的另外一个进程独立的处理这个队列。
如果在写入数据库前某些数据又发生了修改,因为该数据还没有被插入到数据库,所以这个队列中对应的那个元素也会发生相应的更改,以保证最后插入到数据库中的是最新的数据。
public class UserLogic
{
public void WriteToDb(UserEntity user)
{
CacheManager cache = GetCacheManager();
cache.WriteToDb(user);
}
}
public class CacheManager
{
public void WriteToDb(UserEntity user)
{
cacheStore.AddToQueue(user.cacheKey, user.ToJson());
}
}
public class DbDaemon
{
public void Watch()
{
while(someConditionIsOK())
{
UserEntity user = cacheStore.UserDequeue();
dbManager.WriteToDb(user);
}
}
}在这种模式里,应用层UserLogic照例调用Cache层进行更新,但是CacheManager内的WriteToDb函数已经发生了变化,它将user的内容存放在一个队列中(当然了,同时也得更新缓存)。然后程序的就返回了。
可是,数据怎么放到Db里面去呢?
这技巧放在DbDaemon里,DbDaemon位于另外一个exe中,是独立的应用程序(比如这是个Windows Service),当条件满足时,这个程序到队列里面去取值,取出来再放更新到数据库。
于是乎,UserLogic层只是更新了缓存而已,这会最大限度的保证写入的效率。
write-behind至少带来这几点好处:
- 性能的提升,因为程序不再需要等待数据库的写入操作,当数据写入缓存成功后,程序立刻返回了。
- 降低了数据库的负载,因为每次都是批量的插入到数据库中。如果在正式插入数据库前,数据还有更改,这会让它的优势更明显。例如,插入数据库是数据是{id:1, name:”张三”},这条数据先被放入队列但还没有被处理。后来这条数据又被更改成了李四王五赵六,无论被改了多少次,最终都是以最后的”赵六”为最终结果,数据库实际上只有一次插入操作。
- 程序还提高了可靠性。想象如果数据库服务器发生了宕机,程序并不会立即出现问题,缓存的写入队列还在起作用。
- 并发性能的提高,如果程序需要处理更多的并发,可以提高写入数据库的间隔,减少数据库的压力。
但是,使用write-behind也是有挑战的,如果要使用write-behind,至少有这几点要考虑: - 由于数据库的更新是滞后于cache的,这意味着数据库的事务只能成功不能失败。我们想象一下客户已经提交了购买订单,cache更新成功,订单放入缓存的队列,但是20分钟后,尝试写入到SQL数据库时,出现了数据库插入失败的尴尬局面。
- 如果第三方的应用,或者是人为原因去更新了数据库,这可能导致写入队列中的数据与数据库中数据出现冲突,从而导致数据回写失败。比如缓存中的一个主键是97033,正待写入到数据库。结果另外的某程序抢先一步插入了97033,那么就悲剧了。
cache-aside
发生在应用层,应用层保证缓存结果同DB的数据一致性,应用层来负责写入到数据库和整理缓存,缓存层则不必插手此事。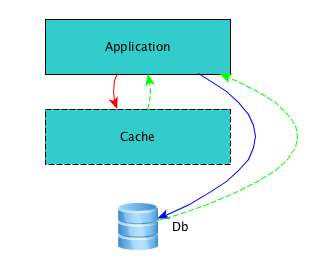
public class UserLogic
{
public void WriteToDb(UserEntity user)
{
cacheStore.Set(user.cacheKey, user);
dbManager.WriteToDb(user);
}
}在这种模式里,所有动作就在应用层里发生,它自己更新Cache,自己写到Db,爱怎么干怎么干。
4种写入数据的方式各有各的特点,可以根据项目自身的特点加以选择。
数据的读取就简单得多了,有这样两种方式。
read-through
读取数据时,先尝试从缓存中取得,如果缓存中没有,那么再从数据库中读取,而后也将数据放入缓存中,以便下次读取。
refresh-ahead
简单的说就是在缓存数据过期前,能自动的刷新缓存数据。举个例子来说,某条数据在缓存中,过期时间是60秒。我们给他设置一个参数,比如是0.8,60x0.8=48秒,那么在前48秒访问该数据,就照正常的取法,直接返回缓存中的数据。当在48-60秒这个区间取数据时,缓存先将之前缓存的结果返回给外部应用程序,然后异步的再从数据库去更新缓存中的值,以尽可能的保证缓存的值是最新的。如果取数据的的时候超过了60秒,就安装read-through的方式。
Refresh-ahead是对未来数据的访问情形的估算,我们猜测这个数据在过期后,仍然可能被频繁的访问,那么这种设计的策略获得的优势会更明显。
但是,如果有大量的数据是用refresh-ahead策略,但是这个数据被重新缓存后,又一次都没有被访问过,那这个策略就是很失算的了。
那么,有人可能会问,既然如此,我把过期的时间延长不就好了,之前60秒过期,改成6000秒过期,这样就不会用Refresh-ahead策略来刷新数据了。
然而,事实是缓存的数据越久,出现脏数据的可能性也就越大,更重要的是,如果你的估算也是失误的,大量的超期缓存数据没有被实际访问,那么你就浪费了很多的内存,做了无用的事情,这也是应该避免的。
缓存策略介绍完毕。再加上伪代码,相信我还是说得比较清楚了。