Geometry Shader(几何元着色器)是继Vertex Shader和Fragment Shader之后,由Shader Model 4(第四代显卡着色架构)正式引入的第三个着色器。在OpenGL3.x中也成为核心,使图形程序开发者在可编程渲染管道(programable render pipline)下能够更大的发挥自由度。由本文开始的一系列乱弹中,Geometry Shader作为基础并重要的一环,现在权且是“首当其冲”吧。——ZwqXin.com
本文来源于 ZwqXin (http://www.zwqxin.com/), 转载请注明
原文地址:http://www.zwqxin.com/archives/shaderglsl/talk-about-geometry-shader.html
Shader Model 4(SM4)在Nvidia 8Series显卡时代已经出现,标志着可编程渲染管道的真正崛起(Shader不再被当作传统管道的“高级扩展可选项”而是其本身取代了传统管线中对应的处理阶段)。API阵营中,Direct3D10率先应运而生,OpenGL虽然在那个过渡期被一堆倾向守旧CAD类行业软件头头纠缠,也终于以其折衷兼容的方式,进入Shader核心的OpenGL 3.x时代。SM4.0带来的其中一个礼物,就是Geometry Shader,在当时可是被寄予众望(“Geometry Shader”的概念虽然提出得更早一些)。在SM4.0渲染管道中,Geometry Shader位于Vertex Shader与Fragment Shader之间:
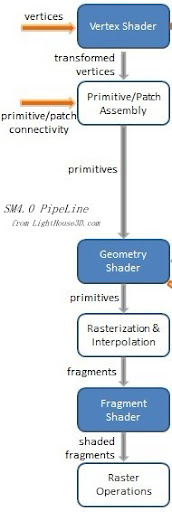
OpenGL中,引起渲染pipline发生的是各种Draw函数,通过它们传入的,除了一些顶点信息,还有就是诸如GL_TRIANGLES、GL_TRIANGLE_STRIP、GL_POINTS之类决定顶点的组织形式的信息(当然OpenGl还会需要结合当前的glPolygonMode决定真正的组织形式)。首先是与之关联的VBO对象中的顶点数据根据各种顶点相关的信息传入管道(见[学一学,VBO] 、[AB是一家?VAO与VBO] 等博客文章),在Vertex Shader处理的就是这些顶点;Fragment Shader处理的是Rasterization栅格化后的像素;而进入栅格化的是图元(Primative),这些图元怎么由Vertex Shader处理后的顶点演化出来?这中间有个Assembly的过程,根据的就是上面提及的GL_TRIANGLES这些信息,把顶点组合成图元(Primative):
- //顶点(典型的Vertex Shader输出结构):
- Vertex
- {
- vec4 gl_Position;
- float gl_PointSize;
- float gl_ClipDistance[];
- };
- //所组成的图元:
- PrimitivePoint (根据GL_PONTS组织)
- {
- Vertex[1];
- ...
- };
- PrimitiveLine (根据GL_LINES或GL_LINE_STRIP或GL_LINE_LOOP组织)
- {
- Vertex[2];
- ...
- };
- PrimitiveTriangle (根据GL_TRIANGLES或GL_TRIANGLE_STRIP或GL_TRIANGLE_FAN组织)
- {
- Vertex[3];
- ...
- };
- ... Adjacency line/ Adjacency triangle等等
另外还有一些特殊情况组成的图元,一种就是在视锥体裁剪阶段(栅格化之前),边界处新生成的顶点造成的图元分割,这个不作讨论范畴;点精灵(PointSprite)根据一个顶点和其大小(pointSize)生成一个矩形(其实是两个tiangle),等等。
从简地说,上述的PrimitivePoint 、PrimitiveTriangle这些就是图元(Primative,也有称作片元的),从数据的结构上说,就是一个或数个顶点的集合而已。在Geometry Shader里,我们处理的单元就是这些Primative。虽然根本上都是顶点的处理,但进入vertex shader里的是一次一个的顶点,而进入Geometry Shader的是一次一批的顶点,Geometry Shader掌握着这些顶点所组成的图元的信息。Geometry Shader的处理阶段处于流水线的栅格化之前,也在视锥体裁剪和裁剪空间坐标归一化之前。虽说裁剪过程会剔除部分图元也会分割某些图元, 但就目前来说,不会有其他流水线的可编程阶段会在Geometry Shader之后提供出影响图元的性质(形式和数量)——这是Geometry Shader鉴于其位置的特殊性而拥有的一个重要特点。
好吧。这些啰嗦的背景介绍就到这里,对刚接触Geometry Shader的同学希望有点帮助。在提一点,就是即使是Opengl 3.x的core profile(强制必须使用可编程渲染管道),Geometry Shader也不是必须的,而是可选项。这也是很多很多时候其实我们只需要Vertex Shader和Fragment Shader的原因。(当然了,符合某些条件的话,Vertex Shader或Fragment Shader也不是必须的,譬如transorm feedback下不需要栅格化和输出像素时,就不需要Fragment Shader;通过invocation可以只给个空心的Vertex Shader意思一下而在Geometry Shader直接生成图元等等。)正如上文所述,图元是在Geometry Shader之前已经生成的了,Geometry Shader的功用首先在于它能对进入的图元的组织形式和数量有直接影响。
先看一对简单的Vertex Shader和Fragment Shader,Vertex Shader把进来的顶点Vertex转换到裁剪空间([乱弹OpenGL中的矩阵变换(上)] [乱弹OpenGL中的矩阵变换(下)] ),直接传给流水线下一阶段,经内部Assembly生成图元Primative后,再一直到Rasterization栅格化出像素Fragment,Fragment Shader只是单纯采样一个纹理并把像素输出:
- //Base.vert
- #version 330
- uniform mat4 matModel;
- uniform mat4 matView;
- uniform mat4 matProj;
- layout(location = 0) in vec3 attrib_position;
- layout(location = 1) in vec2 attrib_texcoord;
- out vec2 varying_vf_texcoord;
- void main(void)
- {
- varying_vf_texcoord = attrib_texcoord;
- gl_Position = matProj * matView * matModel * vec4(attrib_position, 1.0);
- }
- //Base.frag
- #version 330
- uniform sampler2D basetex;
- in vec2 varying_vf_texcoord;
- layout(location = 0) out vec4 fragColor;
- void main(void)
- {
- fragColor = texture(basetex, varying_vf_texcoord);
- }
正如上述,一旦OpenGL应用指定ShaderProgram使用Geometry Shader,则上面的叙述变成:在Assembly生成图元Primative后,再一直到栅格化前进行Geometry Shader的处理,再到Rasterization栅格化。我们也用一个简单的Geometry Shader,单纯把进入的图元原原本本地(组织形式和数量也一致)输出:
- //Base.vert
- #version 330
- uniform mat4 matModel;
- uniform mat4 matView;
- uniform mat4 matProj;
- layout(location = 0) in vec3 attrib_position;
- layout(location = 1) in vec2 attrib_texcoord;
- out vec2 varying_vg_texcoord;
- void main(void)
- {
- varying_vg_texcoord = attrib_texcoord;
- gl_Position = matProj * matView * matModel * vec4(attrib_position, 1.0);
- }
- //Base.geom
- #version 330
- layout(triangles) in;
- layout(triangle_strip, max_vertices = 3) out;
- in vec2 varying_vg_texcoord[];
- out vec2 varying_gf_texcoord;
- void main(void)
- {
- for(int i = 0; i < gl_in.length(); ++i)
- {
- gl_Position = gl_in[i].gl_Position;
- varying_gf_texcoord = varying_vg_texcoord[i];
- EmitVertex();
- }
- EndPrimitive();
- }
- //Base.frag
- #version 330
- uniform sampler2D basetex;
- in vec2 varying_gf_texcoord;
- layout(location = 0) out vec4 fragColor;
- void main(void)
- {
- fragColor = texture(basetex, varying_gf_texcoord);
- }
对于Vertex Shader和Fragment Shader来说,也就加粗黑体字部分有变化——Varying变量的名字。为啥呢?因为Vertex Shader的varying变量作为输出,是要先进入Geometry Shader并通过它作为输出去给到Fragment Shader的。所以在Geometry Shader内同时有一个输入的varying和输出的varying,无法同名。
在这个简单的Geometry Shader中,红色粗体字部分的layout声明了进入的图元的组织形式(triangle,注意这个需要跟Opengl应用上对应的draw函数一致,PolygonMode无用)、数量为1(作为Geometry Shader的处理单元,每次处理的输入当然是一个Primative啦);输出的图元的组织形式(同样是triangle)、数量为1(因为最大的输出顶点数是3,也就是最多只会输出一个triangle了)。作为输出的关键字,只有points、line_strip、triangle_strip三种,下面再述。
作为输入的图元,也就是上述的PrimitivePoint 、PrimitiveTriangle这些,所包括的Vertex结构用gl_in[]来表示:
- in gl_PerVertex {
- vec4 gl_Position;
- float gl_PointSize;
- float gl_ClipDistance[];
- } gl_in[];
- // 注意,除了这个顶点数组外,作为输入的图元结构还包括gl_PrimitiveID等等
没错,这个数组的个数(gl_in.length())就是由输入的图元的组织形式决定的(譬如points的话个数就是1,triangles的话个数就是3)。作为Varying输入的varying_vg_texcoord[]也是同样的道理。接下来的事情就很一目了然了:EmitVertex()这个函数相当于输出一个点到一张画布上,EndPrimitive()这个函数的调用将画布上当前的点组织成一个图元(在这里是triangle_strip)向外输出,并清空画布上当前的点。
看上去是调用EndPrimitive()多少次就将输出多少个图元。这样调用EndPrimitive()的瞬间就有这样几种情况:
- 如果当前画布上的点不足够组成一个图元(譬如当前画布上只有两个点,而组成triangle_strip至少要有3个点)?——这时候将不输出任何图元,但画布还是要清空的;
- 刚好能组成一个三角形图元(画布上刚好有3个点)——这样没问题
- 如果当前画布上的点多于3个呢?——注意,在输出的layout中max_vertices=3,也就是说,整个Geometry Shader执行的期间会统计你当前一共通过EndPrimitive()输出了多少个点,如果超过了max_vertices这个值,接下来的EmitVertex()就不会把点输出到画布上了,如果当前画布上点不足3个,这样后续EndPrimitive()的调用就跟第一种情况一样了;但现在既然多于3个,那就只会取前3个点去输出一个三角形。注意统计的不是你向画布上的输出的点,而是EndPrimitive()成功调用所发出去的点。
那么假如layout中设的是max_vertices=4呢?再次考虑上面三种情况:
- 情况一样;
- 情况也是一样的,因为3<max_vertices,这时候输出的也是一个三角形图元;
- 如果当前画布上的点多于3个呢?——如果是刚好4个,那么按照triangle_strip的特性,将输出两个三角形图元;多于4个的话,那也是一样的,输出两个三角形图元。
所以当你编写Geometry Shader时,一定要时刻惦记自己设定的输出layout。如果无法事先确定该shader最终会输出多少个图元时,max_vertices就要设成所能预想的最大顶点数值。这个我是吃过不少亏的,因为shader写好经常忘记去对应layout的值。
另外,现在你已经知道输出只有points、line_strip、triangle_strip三种的意义了,因为其他形式的图元都可以用这三种输出,只要对应当前画布上点的数量就是了。说了那么久,画布是啥,点又是怎么定义的?
画布当然是GPU寄存器里的一个缓存区域了啊,一个提供临时线性存储Buffer(是吗?各位硬件牛大大 - -)。然后一个作为输出的点有如下构造:
- out gl_PerVertex {
- vec4 gl_Position;
- float gl_PointSize;
- float gl_ClipDistance[];
- };
- out int gl_PrimitiveID;
- out int gl_Layer;
- ....
- out XXX;....//其他varying输出变量,譬如上面的varying_gf_texcoord
我们要往“画布”上画一个点,其实就是在单个EmitVertex()之前填充上面的构造就是了(如果你之前不清楚,那么告诉你凡以gl_开头的都是内置的变量,作为自己定义的变量名不要带有这个前缀)。在上面的Base.geom中,填充就是代表顶点坐标的gl_Position(这个是必须的你懂的)和自定义的输出varying:varying_gf_texcoord。其他值都会有其默认值,其中gl_PrimitiveID是当前图元的ID,这东西在输入的内置变量中也有一个,在某些地方还是很有用的,譬如基于颜色的GPU执行拾取时,就可以把它直接赋予原来输入变量中的值,输出给Fragment Shader以用它去确认当前像素属于哪个图元;gl_Layer主要用于Layered-Rendering,针对此下文会再述。注意,这里每个变量被填充后会一直保持该值到再被赋值或者“画布”的清除。gl_PrimitiveID、gl_Layer是针对图元的,所以一个图元对于它们最终采样怎样的值,取决于图元上其中一个顶点(provoking vertex)。
对Geometry Shader的应用,一个很经典很常用的,就是Billboard。以前渲染Billboard(譬如一张alpha纹理标识的树),为了不产生视觉怪像,往往要(至少水平方向上)计算视线向量跟该Billboard-Quad平面向量的夹角,并实时地使用该夹角去反旋转billboard至与视线向量垂直。这都是在CPU上执行的。现在有了Geometry Shader,这种计算很方便了:
- #version 330
- layout(points) in; //输入的只是一个点
- layout(triangle_strip, max_vertices = 4) out; //输出的是一个Quad(两个triangle)
- uniform float grassScale; //Billboard的大小,也可以分别输入宽度高度
- uniform vec3 eyePosition; //世界坐标系下的视点坐标
- uniform mat4 matModel;
- uniform mat4 matView;
- uniform mat4 matProj;
- out vec2 varying_texcoord;
- void main(void)
- {
- float fScale = grassScale / 2.0;
- mat4 matPV = matProj * matView;
- vec4 position[4];
- //因为输入的是一个点(gl_in.length() = 1),这里的for循环其实只执行一遍
- for(int i = 0; i < gl_in.length(); ++i)
- {
- vec3 inPos = gl_in[i].gl_Position.xyz;
- //该输入点在世界坐标系下的坐标
- vec4 posInWorld = matModel * gl_in[i].gl_Position;
- vec3 vDistFromCam = eyePosition - posInWorld.xyz;
- //获得视线向量
- vec3 cameraVec = normalize(vDistFromCam);
- //Billboard平面的水平向量
- vec3 vRight = cross(vec3(0.0, 1.0, 0.0), cameraVec);
- //Billboard平面的数值向量
- vec3 vUp = cross(cameraVec, vViewRight);
- //计算billboard四个角点的坐标
- position[0] = matPV * vec4(inPos - fScale * vRight, 1.0);
- position[1] = matPV * vec4(inPos + fScale * vRight, 1.0);
- position[2] = matPV * vec4(inPos - fScale * vRight + fScale * 2 * vUp, 1.0);
- position[3] = matPV * vec4(inPos + fScale * vRight + fScale * 2 * vUp, 1.0);
- for(int j = 0; j < 4; ++j)
- {
- gl_Position = position[j];
- varying_texcoord = vec2(j % 2, j / 2);
- EmitVertex();
- }
- EndPrimitive();
- }
- }
这就是通过一个点去生成一个广告牌矩形,用ponts去populate出billboards——在OpenGL中只需要glDrawArray(GL_POINTS,...),指定每个billboard底边中点的位置作为顶点传入即可(当然也可以是矩形中心,上面计算角点坐标时自己改一下就是了,注意无论哪种都好,这个点本身是不需要也一起输出的)。注意的是populated的角点坐标要与传入的视点坐标在同一个坐标系下,这样计算出来的Billboard向量次啊会正确。这里考虑到进入的点本来就统一定义在世界坐标系下所以就直接在世界坐标系下计算了。为了控制计算的坐标系,矩阵运算直接从Vertex Shader移到这里计算了(Vertex Shader只要直接输出所输入的顶点就可以了)。

利用Geometry Shader去populate矩形,在很多时候都会用到。再提一个熟悉的,就是粒子系统的粒子渲染。首先,我8知道过了那么久到了现在OpenGL也早已迈入4.0时代,PointSprite点精灵的方式去渲染小粒子的方式,比起直接用Quad来渲染还会优到何地步(上面也提过,它是到Assembly时生成两个triangle图元的),但我觉得还是让我们有更好的控制感比较好。粒子通过跟上述shader类似的方式,即可以由points生成矩形(鉴于粒子的特性,也不必再计算什么视觉向量来精确求出角点了,直接随便根据点的坐标向任意方向拓展一个矩形即可)。生成的时机在流水线上后延了,流水带宽也会降低点。当然了,如果纯性能上考虑,点精灵那种依赖PointSize的方式,跟需要另外起一个Geometry Shader带来的性能损耗,也8知道孰高孰低了。是的,Geometry Shader的插入会一定程度影响性能,容后再说。
再来说一下基于Geometry Shader的一个很独特的应用点:Layered-Rendering。
在以前玩Cascaded Shadow Map[联结FBO与Texture Array] 时,想把几个层级的深度图渲染到一个纹理数组[学一学,
Texture Array纹理数组]上,需要使用glFramebufferTextureLayer给每一层都关联一次FBO和TextureArray的layer,然后渲染一次场景。也就是说,要想分几层,就要预先给渲染几个Pass了(虽然说颜色输出禁用和FBO纹理格式的控制可以减低很多消耗,那也很耗了)。当时也想有没方法一个Pass解决呢?当时也许还没真正现形,但Geometry Shader提供了这么一个可能,也就是Layered-Rendering。简洁的说,它一个重要功能就是可以在Geometry
Shader阶段把图元固定导向一个固定的渲染目标的某一特定层。再简洁点,就是可以在Geometry Shader中选择把图元输出到哪一个layer——只要当前是渲染到FBO的一个具有层属性的渲染目标。符合的渲染目标,典型的就是TextureArray,还有CubeMap([Shader快速复习:Cube
Mapping(立方环境贴图)] ,它本身就是6层的纹理结构)。
以把场景渲染到CubeMap为例。譬如场景中间有个球,需要把除了球本身外的整个场景实时地渲染到这个球体上,使它像一个镜面球一样反射出360度的整个场景。传统做法是把摄像机Camera放置在球体中心,分别使之朝向上下左右前后6个正交的方向,分别渲染一次场景进FBO里(渲染对象是二维纹理),得到的6张纹理再组合成一张CubeMap,以法线采样的方式贴到球面上(至于为什么采用CubeMap方式进行球面贴图,见此博客文章:[球体贴图小谈] )。Layered-Rendering的方式,则直接以一张CubeMap为FBO的渲染目标:
- glBindFramebuffer(GL_FRAMEBUFFER, m_nHandle);
- glBindTexture(GL_TEXTURE_CUBE_MAP, renderTarget.nHandle);
- glTexParameteri(nTargetType, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
- glTexParameteri(nTargetType, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
- glTexParameteri(nTargetType, GL_TEXTURE_WRAP_R, GL_CLAMP_TO_EDGE);
- for(int i = 0; i < CUBE_FACE_COUNT; ++i)
- {
- glTexImage2D(GL_TEXTURE_CUBE_MAP_POSITIVE_X + i, 0, nInternalFormat, m_nWidth, m_nHeight, 0, nPixelDataFormat, nPixelDataType, NULL);
- }
- glFramebufferTexture(GL_FRAMEBUFFER, nAttachBuffer, renderTarget.nHandle, 0);
这里有一点是特特别别需要注意的,就是这里指定的m_nWidth和m_nHeight必须相等。也就是说,CubeMap每个面的纹理必须严格是正方形(其实很直观的:不是正方形能正常拼出盒子么……不过我刚开始就是被这细节弄郁闷了不少时间)。glFramebufferTexture是一个普适各种渲染目标的函数(没有后缀的版本),要支持Layered-Rendering也就靠它了。我们在正式渲染场景前,先把场景渲染进这个FBO([学一学,FBO]),控制所有场景渲染的Shader跟正常渲染时想比:
- if(nRenderToCube > 0)
- {
- // 紧记此Shader输出layout的max_vertices需要是原来的6倍
- for(int k = 0; k < 6; ++k)
- {
- matPVM = matProj * matCubeViewArray[k] * matModel;
- gl_Layer = k;
- position[0] = matPVM * vec4(inPos + vec3(-fScale, 0.0, 0.0), 1.0);
- position[1] = matPVM * vec4(inPos + vec3( fScale, 0.0, 0.0), 1.0);
- position[2] = matPVM * vec4(inPos + vec3(-fScale, fScale * 2.0, 0.0) + vDeform, 1.0);
- position[3] = matPVM * vec4(inPos + vec3( fScale, fScale * 2.0, 0.0) + vDeform, 1.0);
- for(int j = 0; j < 4; ++j)
- {
- gl_Position = position[j];
- varying_texcoord = vec2(j % 2, j / 2);
- EmitVertex();
- }
- EndPrimitive();
- }
- }
- else
- {
- matPVM = matProj * matView * matModel;
- position[0] = matPVM * vec4(inPos + vec3(-fScale, 0.0, 0.0), 1.0);
- position[1] = matPVM * vec4(inPos + vec3( fScale, 0.0, 0.0), 1.0);
- position[2] = matPVM * vec4(inPos + vec3(-fScale, fScale * 2.0, 0.0) + vDeform, 1.0);
- position[3] = matPVM * vec4(inPos + vec3( fScale, fScale * 2.0, 0.0) + vDeform, 1.0);
- for(int j = 0; j < 4; ++j)
- {
- gl_Position = position[j];
- varying_texcoord = vec2(j % 2, j / 2);
- EmitVertex();
- }
- EndPrimitive();
- }
正如你想,两者的不同之处,是Layered-Rendering需要把图元输出6遍,每一遍选择不同的ViewMatrix(也就是Camera位于球心并朝向6个正交方向时所生成的视图变换矩阵,由OpenGL应用传入),还有就是使当前需要输出的图元所有顶点的gl_Layer设成当前渲染目标的层(0~5)。在CubeMap中,第0层就是GL_TEXTURE_CUBE_MAP_POSITIVE_X所代表的纹理层,第1层是GL_TEXTURE_CUBE_MAP_NEGATIVE_X,如此类推。包括视图变换矩阵,都需要按此顺序。
在渲染到FBO后,再按正常方式渲染场景和那个球体。渲染球体的时候使用CubeMap贴图,用FBO输出的那张CubeMap就OK了。动态CubeMap在譬如汽车倒后镜、水面Cube反射([水效果Ⅱ - 涟漪])之类的场合还是很常用的。

结果看起来很好。但是,它却使得帧率一下子下降了许多。根据大牛的详细测试(《不争气的GS》),这甚至比6-pass的做法还要低效。为什么呢?是因为Geometry Shader!?这样,最后的议题终于要被提上论程了:使用Geometry Shader的性能代价。
Geometry Shader从概念的提出到进入SM4.0,是被赋予厚望的:希望它能产生更丰富的图元更丰富的视觉效果。或许应该这么说,是希望它实现出像如今SM5.0中Tessellation(细分曲面)技术的效果。但是实际上它的发展速度跟不上人们的期望。加上SM5.0的提出,如今感觉GPU架构的发展已经不再在Geometry Shader上下工夫了。也就是说如今它几乎被定型,也就是主要作为粒子系统、billboard、culling等的实现场所。说到底,为什么输出layout中需要有max_vertices这个指定值呢?因为如果不显式指定的话,就没法针对输出的Buffer作出优化。这隐含这么一个意思:图元被扩展得越厉害,性能下降得也越厉害。
为什么Geometry Shader变成了性能杀手呢?一个很显然的理由,也大概是我们了解它后的第一感觉:它是不是损害了流水线的并行性了?我们知道,无论是Vertex Shader处理顶点,还是Fragment Shader处理像素,都是由GPU的并行执行单元保障其高度并行性的,各顶点间的处理没有干扰和交集,像素几乎也是。那么图元呢?在这里,图元只是顶点的集合,甚至可以说Geometry Shader本身也是处理顶点的,但图元处理的并行性变相使得这些图元内的顶点丧失并行性(尤其是非points的输入组织形式)——它们在Geometry Shader内都是同时可见的。另一方面,为了保障Geometry Shader执行的并行性,必然需要启用不少的存储单元(还有就是之前提及的“画布”),这对性能肯定也会造成一定压力(或者说,图元这种有序生成的东西本身就不太适用并行处理)。当然了,应该还有不少非臆想的硬件实现方面的障碍,共同导致了Geometry Shader如今这种尴尬地位。所以或者可以这样总结:能够不用Geometry Shader的场合就不要用,要用的时候就让输出顶点数尽量少、执行的内容尽量简单。
我们看它的主要应用:对于粒子和billboard,由于作为输入的是point,这样并行性能更好的保证,输出的通常也就4到8个顶点左右,对显卡的性能优化比较适合,所以在这方面Geometry Shader是比较适合的;对于instance-culling(以后文章会提及),由于它是“减少”而不是“增加”,所以性能负担也不会太重;对于Layered-Rendering,尽管看上去很棒,但就目前显卡水平来说,这个的效率很有缺陷;而对于其他比较有名的应用场合,诸如Fur-Rendering,就不太熟悉了,还有以前做Shadow Volume([Shadow Volume 阴影锥技术之探Ⅵ] )时或许都提及过的,用Geometry Shader代替degenerated guad(退化矩形)创建并拉伸出Volume这些,由于也没试过,就不大好说了。
最后结束本文并自我提醒一句:请合理使用Geometry Shader。
本文来源于 ZwqXin (http://www.zwqxin.com/), 转载请注明.原文地址:http://www.zwqxin.com/archives/shaderglsl/talk-about-geometry-shader.html
再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://blog.csdn.net/jiangjunshow