一、编译器前端模型
|---------->符号表------------------------------------------------>|
源程序----(词法分析器)--->词法单元----(语法分析器)---->语法分析树----(中间代码生成器)--->三地址代码
二、语法定义——“上下文无关文法”(context-free grammar)
1.由数位和+、-符号组成
此文法产生式为
expr -> expr + digit expr -> expr - digit expr -> digit
digit -> 0|1|2|3|4|5|6|7|8|9
组合起来为:expr -> expr + digit | expr - digit | digit,终结符号为 + - 0 1 2 3 4 5 6 7 8 9,开始符号为expr。
不可以将expr和digit合并为一个非终结符号,这会导致二义性,比如合并为string,此时文法改写为
string -> string + string | string - string |0|1|2|3|4|5|6|7|8|9
假设现在字符流为9 - 5 + 2,则9 - 5匹配第二个产生式,5 + 2 匹配第一个产生式,具有二义,应当避免这样的设计
2. 右结合运算符
某些运算符是右结合,如 =(赋值), **(指数),赋值串比如a = b = c 的文法表示
right -> letter = right | letter
letter -> a|b|c ... | z
指数运算串比如 a**b**c 的文法表示
right -> letter ** right | letter
letter -> a|b|c...|z
假设a**b先运算,得到一个rihgt,那(a**b)**c要么是rihgt**letter,要么是right**right,无法匹配上面任何一个产生式。
3. 运算符号*、/
设定运算符号*、/比 +、- 具有更高的优先级。根据n个优先级需要n+1个非终结符号,创建两个非终结符号term和expr分别对应这两个优先级层次,终结符digit表示数位,如果不考虑使用括号(parentheses),则这些符号足够表示文法了,如果考虑使用括号,即对expr使用括号,变为 (expr) ,则这个expr无法被高优先级符号*、/分开,前面说到digit数位也是一个整体,故合并起来为一个非终结符号,记为factor,其中 factor -> digit|(expr) ,现在给出文法如下
expr -> expr + term | expr - term | term term -> term * factor | term / factor | factor factor -> digit | (expr)
4. 例子
大多数语句由一个关键字或一个特殊字符开始,然而例外情况也有,比如赋值语句(不带声明)或过程调用(函数调用)。这里不考虑这些例外情况。
stmt -> id = expression; | if (expression) stmt | if (expression) stmt else stmt | while (expression) stmt | do stmt while (expression); | { stmts } stmts -> stmts stmt | ε // 为空语句
注意分号的位置,只出现在非stmt结尾的产生式,否则会导致多余的分号出现
三、语法制导翻译
这是一个通过向一个文法产生式附加一些规则或程序片段实现翻译的过程。
1. 属性
属性表示与某个程序构造相关的任意的量,如表达式的数据类型,生成代码的指令数目或为某个构造生成的代码中第一条指令的位置。
将属性与文法的非终结符号和终结符号相关联。比如文法符号X,用X.a表示X上的属性a的值。如果语法分析树各结点标记了相应的属性,则这个语法分析树为注释语法分析树。对于9 - 5 + 2,其注释分析树为

其定义如下, "||"表示连接运算符
产生式 语义规则 expr -> expr1 + term expr.t = expr1.t || term.t || '+' expr -> expr1 - term expr.t = expr1.t|| term.t || '-' expr -> term expr.t = term.t term -> 0 term.t = '0' term -> 0 term.t = '1' ... ... term -> 9 term.t = '9'
2. 树的遍历
树的遍历用于描述属性的求值过程,以及描述一个翻译方案中各个代码片段的执行过程。一个树的遍历从根结点开始,按照某个顺序访问树的各个结点。
3. 语法制导翻译方案
在文法产生式中附加一些程序片段描述翻译结果,被嵌入的程序片段称为语义动作。
expr -> expr1 + term {print('+')}
expr -> expr1 - term {print('-')}
expr -> term
term -> 0 {print('0')}
term -> 1 {print('1')}
...
term -> 9 {print('9')}
四、语法分析
1. 自顶向下分析
考虑如下文法
stmt -> expr | if(expr) stmt | for(optexpr; optexpr; optexpr) stmt | other optexpr -> ε | expr
这里为了简化,我们将expr看作终结符的一个表达式,类似地,other是一个代表其他语句的终结符号。对于如下输入串
for(; expr; expr) other
我们从非终结符号stmt根结点开始,目标是构造出语法分析树的其余部分,使得这棵树与输入符号匹配。
输入中当前被扫描的称作向前看(lookahead)符号,此时为for,根据前面的文法,只有一个产生式可以推导这样的串,所以我们选择这个产生式,产生式中的符号作为根结点stmt的子结点,如图

此时,根结点stmt这个结点的子结点全部构造完毕,于是我们开始考虑这个结点的最左子结点,即for结点,而这个标号for是一个终结符号,与上文提到的向前看符号for匹配,那输入串中的下一个终结符成为新的当前看符号,这里是“(”,同时考虑语法分析树的下一个子结点,也是"(",匹配,那再下一步输入中的向前看符号为";",而语法分析树的下一个子结点为optexpr,这是一个非终结符号,我们需要为它选择一个产生式,即optexpr的 ε 产生式,如此,最后构造的语法分析树为

2. 预测分析法
采用一种递归下降分析法,各个非终结符号对应的过程的控制流可以由向前看符号无二义地确定,故而不需要回溯。
对上一部分中的文法,给出预测分析器的伪代码如下
void stmt() { switch (lookahead) { case expr: match(expr); match(';'); break; case if: match(if); match('('); match(expr); match(')'); stmt(); break; case for: match(for); match('('); optexpr(); match(';'); optexpr(); match(';'); optexpr(); match(')'); stmt(); break; case other: match(other); break; default: report("syntax error"); } } void optexpr() { if (lookahead == expr) match(expr); } void match(terminal t) { if (lookahead == t) lookahead = nextTerminal; else report("syntax error"); }
预测分析需要知道哪些符号可能成为一个产生式体所生成串的第一个符号。令α是一个文法符号(终结符号或非终结符号)串,定义FIRST(α)为可以由α生成的一个或多个终结符号串的第一个符号的集合.如果α就是ε或者可以生成ε,那么ε也在FIRST(ε)中。
对上面的情况,FIRST的计算方式如下:
FIRST(stmt) = { expr, if, for, other}
FIRST(expr;) = {expr}
如果有两个产生式A->α和A->β,考虑相应的FIRST集合。如果不考虑ε产生式,预测分析法要求FIRST(ε)和FIRST(β)不相交,这样才能用向前看符号确定使用哪个产生式,即使用预测分析法时,要求任何非终结符号的各个产生式的FIRST集合互不相交。
3. 递归
左递归产生式:
expr -> expr + term
显然这会导致无限循环。一种消除方法是
A -> Aα|β
非终结符号A的产生式,其中α和β是不以A开头的终结符号或者非终结符号。一个具体的例子是
expr -> expr + term | term
注意这里α是 +term
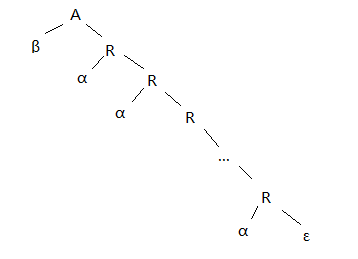
一种消除左递归的方式如下(改成右递归产生式)
A -> βR
R -> αR | ε
右递归的产生式会使得树向右下方向生长,如下图
声明:本篇文章完全参考编译原理龙书