一、 过拟合
首先我们需要明白什么是过拟合,由下图可知,对于(2)图则是出现了非常明显的过拟合。
从图中我们可以发现过拟合的特征,具有非常强的非线性特征,几乎让训练误差接近于0。

二、 正则化的思路
对于正则化,我们则是想要降低这种非线性的特征。这是我们的目的,我们来观察一下我们的非线性特征产生的原因——激活函数。
我们选取tanh的函数进行分析,从图中可以看出,非线性特征需要在于当x远大于0的时候,y的结果趋向于正负一而与x的产生非线性关系。
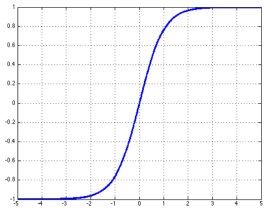
而从图中可以看出,当z(横轴)接近0时,非线性特征并没有特别明显,换句话说,函数更具有线性特征。
因此我们这里采取的方案就是想要z更加接近0,以此削弱非线性特征。
而以上讨论的z则是神经网络中每一层网络通过Z[l]=W[l]A[l]+b[l]计算得来的。
若是想要Z更加接近于0,由于A是通过计算出来的,我们只可以通过优化W和b让Z更加接近于0。
至此,我们已经发现了我们的目的,即让W和b更加接近于0。
三、 正则化的实施
我们来看正则化的究竟做了什么?
$J=frac{1}{mathrm{m}} sum_{mathrm{i}}^{m} Lleft(widehat{y}^{(i)}, y^{(i)} ight)+frac{lambda}{2 m}|w|^{2}$
从这个式子里,我们看到,为了让J,也就是我们的cost下降,一方面我们可以通过损失函数L来拟合预测值和真实值,另一方面,我们也需要减小w。
事实上,有些正则化的方法中,也用了b,但是w的正则化对于模型的影响更大。
让我们从梯度下降的过程中再看一下这个过程。
$frac{d J^{[l]}}{d w}=left(frac{mathrm{d} J}{d Z} * frac{d Z}{d w}
ight)+frac{lambda}{m} w^{[l]}$
$w^{[l]}=w^{[l]}-partial d w^{[l]}=left(1-frac{partial lambda}{m}
ight) w^{[l]}-partialleft(frac{mathrm{d} J}{d Z} * frac{d Z}{d w}
ight)$
其中对Z的偏导并无差别,这里就不写出结果了。可见在梯度下降的过程中w首先就以更接近0的姿态,进入下一次迭代的过程。
在深度学习框架中,大家比起L1范数,更钟爱L2范数,因为它更加平滑和稳定。
以上,便是对正则化防止过拟合的理解。