不知不觉中,我已经接触OO五周了,顺利地完成了第一章节的学习,回顾三次编程作业,惊喜于自身在设计思路和编程习惯已有了一定的改变,下面我将从度量分析、自身Bug、互测和设计模式四个方向对自己第一章的学习做一个总结。本人OO萌新,且这篇文章更多面向我自己,无法面面俱到,因此若对文章内容有疑惑和建议,欢迎各位大佬在评论区批评指正~
程序度量分析
本章求导作业共有三次,通过从不同度量指标纵向对比三次作业,我发现自己的代码结构已经逐渐有了变化,下面我将从类结构图、代码复杂度和类依赖三个指标对三次作业进行分析。


刚接触面向对象的编程题时,我首先尝试的便是将对象的概念加入到编程中,不要“Main到底”,划清表达式中的类,从而识别出了Poly和PolyUnit两个类,PolyUnit完全由Poly创建并用相关容器进行保存,从属结构非常简单。然而,通过结构图和复杂度矩阵,存在着三个问题:
-
类的方法过于繁多 -> 创建检查输入数据的输入类,完成格式检查的工作。
-
Poly和PolyUnit的可扩展性不强,仅能简单多项式。 -> 类的继承,尝试增加层次和改善架构。 -
可变和不变部分界限划分不清,如多项式化简的内容属于可变部分,不应处在不变的核心部分。-> 将化简方式转化成能够拆卸的部分。
第二次作业的类结构
-
类结构图
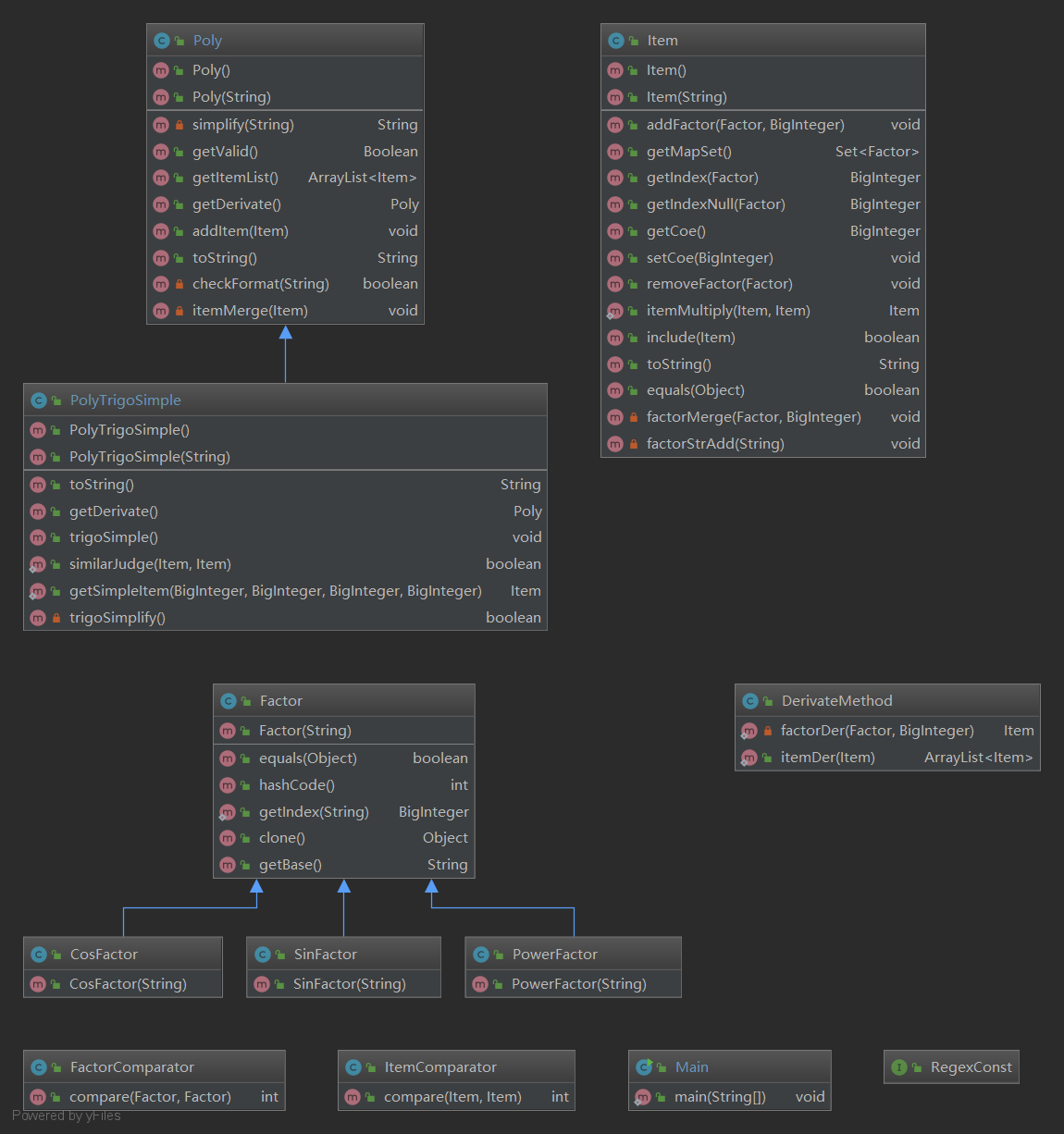

在第二次作业中,由于因子从幂函数和常数拓展到更多的三角函数(以及嵌套的可能性),因此我开始尝试使用类继承的方式来定义多种因子类,并定义了单独的方法类DerivateMethod和Comparator实现复用度高的方法,有了接口编程的雏形。同时,在三角函数化简部分,我采用了继承的PolyTrigoSimple独立出对表达式化简的部分,使得化简功能可装可拆,有了一些修饰者模式的样子了(虽然从细节上看来并不是)。
但是,回首看来,这次作业虽在细节和方法上弥补了第一次作业中出现的问题,但是在算法和架构上埋下了第三次作业的祸根,通过类图可以明显看出在核心数据的存储上还是典型的表达式-项-因子三层从属包含关系,纵然采用了继承对因子进行分类,但是因子仅支持一层的有限类型的简单多项式求导,这样就限制了表达式的深度,进而需要重构以满足多层嵌套的要求。
第三次作业的类结构
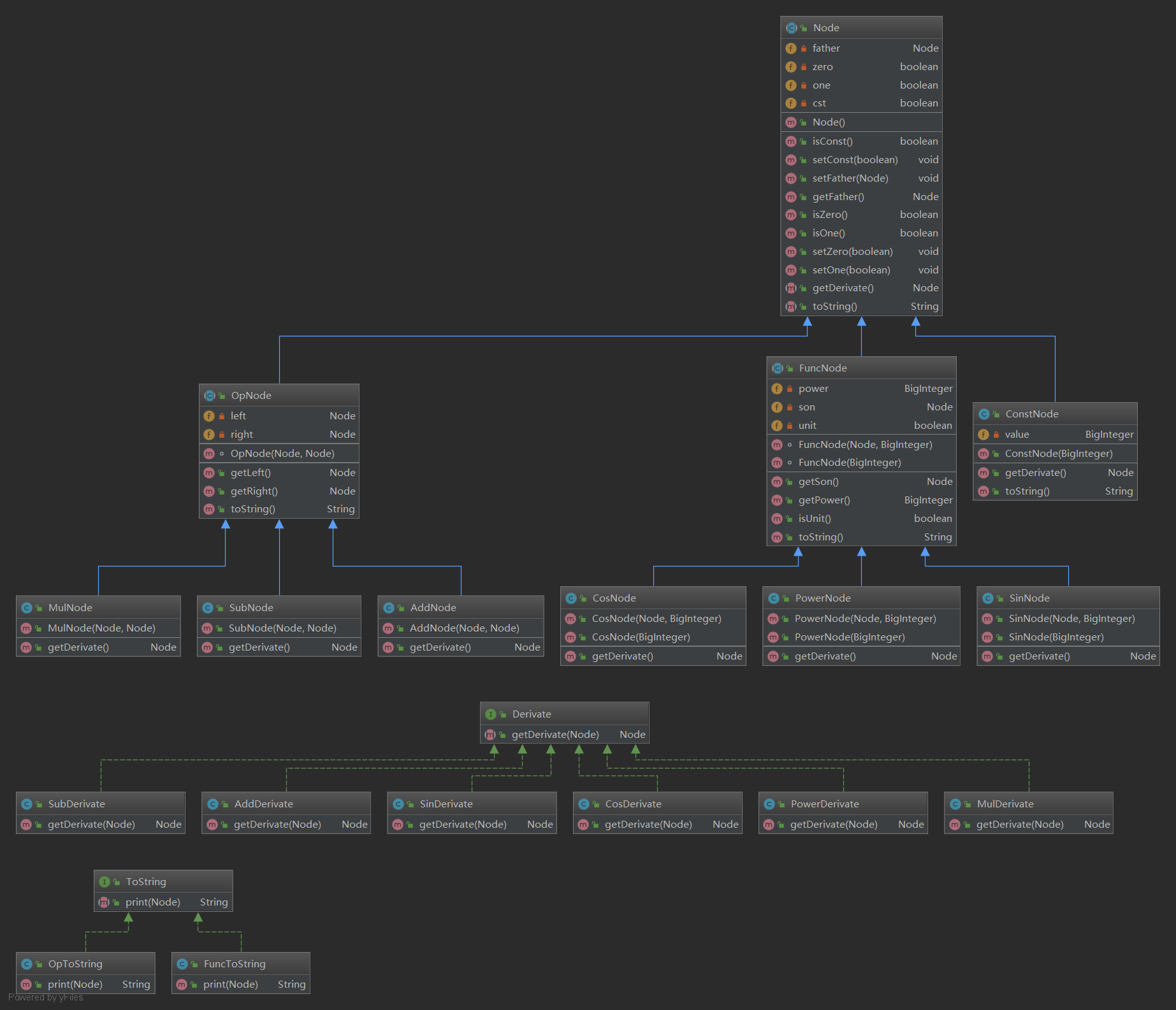

第三次作业中,表达式核心数据的存储结构已从表达式-项-因子变化了表达式树了,由Node基类继承出操作符、函数和常数三种类型的结点,而后基于三类继续继承到具体的算术符、三角函数、幂函数等具体节点,同时使用了Derivate ToString接口实现多态的方法。因此,这次作业在核心数据的存储和处理相较上次作业支持任意层次的嵌套,并且当新增表达式中的因子时,也可以继承Factor子类并实现对应的求导和输出方法即可,具有一定的扩展性,但同时,表达式树(尤其是二叉表达式树)对化简非常不友好,会输出很多重的括号,因此在最后一次作业中,我既没有考虑三角函数的化简,也没有进行系数合并,仅简单地利用isOne,isZero标签在求导时及时剪枝、输出时省略简化。
当然,经过度量分析,本次作业还是存在一些问题:
-
Parser解析器严重C语言编程化->可参考课上所讲的基于FSM的递归下降法。 -
ToString接口方法实现得不好->同Derivate接口一样细分函数和操作符结点的打印方法,并加入基类处的isOne、isZero等共性部件的打印。
代码复杂度


从总体来看,每次作业类的平均复杂度是呈下降趋势的,这主要是由于编程思维已从简单的对象封装到类功能单一、多用多态便于维护的转变。当然,在二三次作业中仍然暴露了一些类结构存在问题:
-
OCavg指标:代表类中方法的循环复杂度的平均值。从分析矩阵中可看出主函数、求导、打印等类存在此类问题,具体来说是由于条件分支和嵌套过于复杂,是(偷懒)
构造时考虑不充分而造成的;当然,对比看来,因子继承和求导方法类的架构就比较好。对于这样的问题,关键就是要意识到问题后要早重构,别偷懒,因为后期潜移默化付出的时间成本和风险都远高于重构的成本。 -
WMC指标:代表类的总循环复杂度。在第二次作业的`Item`
类和第三次作业的RecurParse类都有很高的WMC值,具体来说是方法之间互相调用过于复杂(如递归下降等)。对于这样的问题,应该是保持专人专事的原则,将大类拆成功能专一的小类,降低一个类中方法调用的复杂性。
依赖性分析
由于第一次和第二次作业基本是建立在固定的层级关系上的,类之间的关系比较简单,不存在相互依赖的现象,在此不做分析,现主要分析第三次作业。
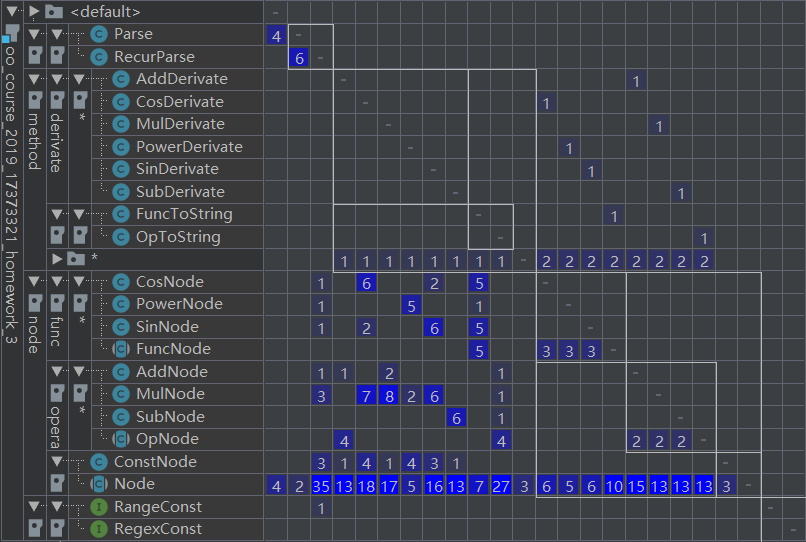
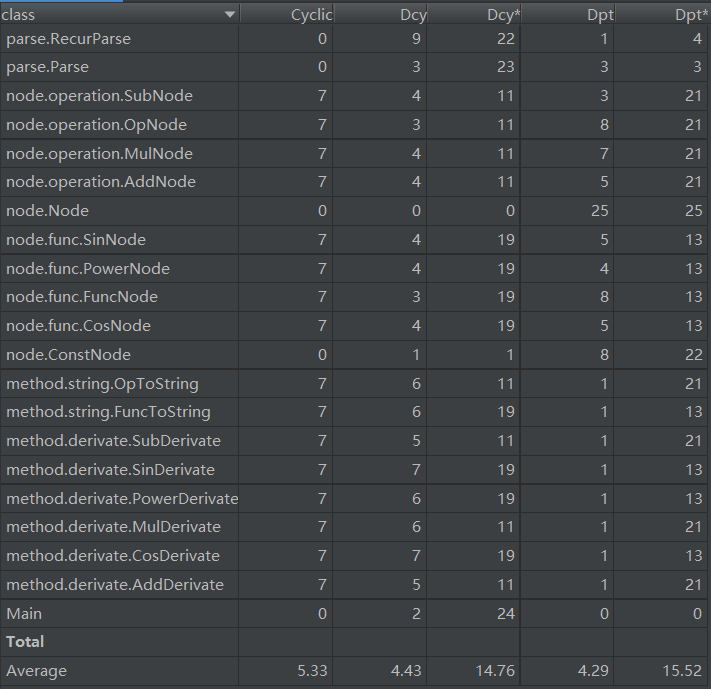


通过矩阵和表格可以看出,第三次作业中输入数据的解析器和表达式树之间的耦合度还是比较低的,Parser和Node之间的依赖都是通过Node引用指向的根结点完成的,其衍生的子类并没有直接参与信息的交换,因此利用继承构建的表达式树对象还是比较成功的。而表格中的循环依赖现象的具体原因是节点实现求导方法和求导方法中创建各类节点造成的相互依赖,属于表达式树中各类之间的耦合。
对于如何解决表达式树中节点类之间的相互依赖性,我还没有思路,同时,有关这个问题我也在博文最下方提出了一个疑问,望知者相助!
分析程序的bug
Bug概览
在三次求导作业中,经过同质样例筛查后,我的Bug统计情况如下表所示:
| 公测 | 互测 | 后期自测 | |
|---|---|---|---|
| Homework1 | 0 | 1 | 0 |
| Homework2 | 0 | 0 | 0 |
| Homework3 | 0 | 0 | 1 |
而这两个Bug均为Wrong Format认假的问题,第一个为fv等非法空白字符的处理,而第二个为sin(-9) sin(- 9)两者因空格而带来的性质改变。
问题定位:WF认假类Bug-输入解析型类-形式检查方法
Bug位置与设计结构之间的相关性
三次作业中,虽然每次作业都有较大的重构,编程也逐渐趋向于面向对象的形式,但从主控函数的角度,核心思路依旧是:输入数据检查-表达式解析与核心结构构造-优化与输出,由此可知其具有很强的过程化和依赖性,在缺乏对象之间异常容错的情况下,任何一个部分出错都会造成错误的结果。因此,本章节作业中的Bug正是由于在输入数据检查环节出现纰漏而造成错误的输出结果。
不过,对于表达式一类的数据处理问题,根据目前所学知识,我认为输入数据检查部分并不能被更好的方式替代,因此只能在此部分做到完全正确,做到完全正确很难,但掌握一些框架性的思路能够少走弯路,经过三次作业的借鉴和尝试,我总结以下两个观点:
-
数据格式检查的思路类型
-
白名单检查:本章作业中集中体现于正则表达式和递归下降法,具体到需求描述中,对应的是正面定义的内容如表达式、项、因子等。在正则表达式中,表达式的整体匹配、逐项匹配、检查字符处在合法范围等便是白名单式的检查;而在递归下降法中,通过定义文法,当文法中有选择性出现的单元时,即可用
单独if+默认值来处理,必然性出现的单元,则用if-else if-else的条件语句处理,而else恰好对应的便是不在白名单中的结果。 -
黑名单检查:本章作业中集中体现于非法空格的处理,具体到需求描述中,常以反例、"除……以外均合法"等反面形式论述。
-
白黑名单检查的关系:白名单划定范围,黑名单剔除杂质,最终再由白名单收尾(千万别黑名单逐个举反例形成最后的集合,这将大大增大出现错误的可能性~


-
1 private boolean checkFormat(String str) { 2 // WhiteList: character use check 3 if (Pattern.compile(RegexConst.forbidRegex).matcher(str).find()) { 4 return false; 5 } 6 // BlackList: illegal space check 7 if (Pattern.compile(RegexConst.illegalSpaceRegex).matcher(str).find()) { 8 return false; 9 } 10 11 // clear space and format expression for further check 12 String temp = str.replaceAll("\s", ""); 13 if (temp.isEmpty()) { 14 return false; 15 } 16 if (!(temp.charAt(0) == '+' | temp.charAt(0) == '-')) { 17 temp = "+" + temp; 18 } 19 // WhiteList: sequence check 20 String regex = "[+-]" + RegexConst.itemRegex; 21 Matcher match = Pattern.compile(regex).matcher(temp); 22 int head = 0; 23 while (match.find(head) && match.start() == head) { 24 head = match.end(); 25 } 26 return (head == temp.length()); 27 }
2.单元测试:虽然数据格式的检查做到100%的准确性不是易事,但是其输入和输出特征却十分适用于单元测试,因此要善于使用JUnit等单元测试工具进行覆盖性测试。
互测
虽说OO使用了CheckStyle对代码进行了基本的白盒测试,但是许多同学提交的还是无ReadMe、无注释、无包的三无代码,加之互测采取了互测屋的模式,令我很难通过阅读全文代码架构分析bug,因此最终我采用了自动化对拍为主,人工检查高频问题为辅的互测方法。
自动测试
研讨课上一位同学对写自动化测试的观点和思想对我感触很大,自动对拍器是一个需要投入很多时间做的工程,没做时感觉非常困难,需要学习使用各种语言和工具,但是一旦开始后便愈加感兴趣,并逐渐地优化和扩展功能,本章作业的最后一周,我也首次完整实现了一个数据生成+自动评测的对拍器,并成功地hack x 2. 在此对一些关键环节进行小结:
-
命令行运行Java程序:在第一次作业论坛中有各式各样的方法批量运行互测屋内同学的程序,在此我选择的方法是利用IDEA自动生成jar包+调用java -jar x.jar的方式,IDEA内置许多结构分析工具,也能自动识别程序入口,无需手写记事本标注入口类。
-
顶层语言的选择:
Python的一个别称是胶水语言,那当然就选择Python了呀(其实吧,这次的对拍器基本都是Python)。1 # 如何在python中调用命令行语句执行其他语言的程序(修改自Mistariano代码),包依赖:subprocess 2 def get_java_output(jar_path: str, jar_name: str, input: str) -> str: 3 popen = subprocess.Popen(['java','-jar',jar_path+'/'+jar_name+'.jar'], stdin=subprocess.PIPE, stdout=subprocess.PIPE) 4 out, err = popen.communicate(input=bytes(input.encode('utf-8'))) 5 return str(out.decode())
-
部件模块的划分:主控单元、测试样例生成器、结果比较器。
-
其他小Trick:带颜色的比对结果输出(命令窗口不可用),外层包裹try-exception并输出原因以防自动对拍中途炸掉。
人工测试
本章作业的人工测试部分是对自动测试的补充,构造某些自动测试不易生成的数据,我着重检查程序的一头一尾——格式检查和表达式化简。首先对于格式检查部分,我重点分析了正则表达式的逻辑完备性,从中找出的bug极大多数都是由于空格符s书写的遗漏和.(通配符)的滥用;其次对于表达式化简,我从求导前可化简和求导后可化简两个方向构造测试数据,交由结果比较模块进行处理。
Applying Creational Pattern
经过对前三次作业代码的可维护性分析和度量性分析,我发现我的程序大致存在以下两个架构问题:
-
结点类耦合较严重:前两次作业由于每一项中因子种类是固定的,因而可以采用向量或三元组等形式进行表示,而在第三次作业中,涉及到多层嵌套,因此需要使用递归,由于定义了众多
Factor的子类,当使用递归下降解析器解析公式和调用每个子类的求导方法时,相互调用创建了诸多实例,随处可见new的使用,很不符合OO编程高内聚、低耦合的思想。 -
嵌入式优化:在追求性能分的路途上,有着各种层次和原理的优化算法,但也引入了更多潜在的风险,我的前两次优化算法就类似于现在的超极本电脑一样,内存、硬盘全都嵌入在主板中,既不方便后续的改装,也提升在出现错误时修复的难度。
在此我提出使用<工厂模式>和<装饰者模式>优化代码的架构。
工厂模式
工厂模式实指工厂方法,在设计模式中共有简单工厂、工厂模式、抽象工厂三种各有优势的工厂方法。在优化第三次作业时,我认为可选择简单工厂的方法,通过向工厂的createNode方法传入字符串和子节点,工厂按照字符串分类创建相应的结点,这样所有Node子类均由工厂进行生产,而对非法结点定义(未知类型的结点,指数不和要求的结点等问题)也可以交由工厂统一抛出异常。
此外,采用这种方式时,在主控函数main中即可将Factory对象实例化,并Factory对象的引用交给解析器以供其使用,这样也符合单另模式。整体的代码框架如下:
1 public class Factory { 2 // create constant type node 3 public Node createNode(BigInteger num) { 4 return new ConstNode(num); 5 } 6 7 // create operation type node which has two sons 8 public Node createNode(String type, Node a, Node b) throws Exception { 9 if (type.equals("plus")) { 10 return new AddNode(a, b); 11 } else if (type.equals("sub")) { 12 return new SubNode(a, b); 13 } else if (type.equals("multi")) { 14 return new MulNode(a, b); 15 } else { 16 throw new Exception("Unknown Operation Type In Factory"); 17 } 18 } 19 20 // create function node which has one son 21 public Node createNode(String type, Node a, BigInteger power) throws Exception { 22 if (type.equals("sin")) { 23 return new SinNode(a, power); 24 } else if (type.equals("cos")) { 25 return new CosNode(a, power); 26 } else if (type.equals("power")) { 27 return new PowerNode(power); 28 } else { 29 throw new Exception("Unknown Function Type In Factory."); 30 } 31 } 32 }
装饰者模式
在本章作业中,可使用装饰者模式进行公式的化简(对于使用List和HashMap存储整个表达式的一二次作业,化简对象是表达式实例,对于使用树结构维护表达式的第三次作业,化简的对象是根结点,从根结点开始进行树的剪枝。)
在具体实现装饰者模式时,装饰者类需要继承自被装饰者类,构造方法中引入被装饰者的引用作为参数,然后定义相应的简化方法即可。
1 public class TrigoSimplify extends Node { 2 Node ori; 3 TrigoSimplify(Node ori){ 4 this.ori = ori; 5 simplify(); 6 } 7 8 private void simplify(){ 9 // ... 10 } 11 }
问题疑问
“高内聚,低耦合”的描述对象?
百科上使用了模块一词作为该原则讨论的单位,我不清楚模块在OO中具体指的是什么?一个类或者多个类构成的功能体?如果是模块可以理解为多个类构成的功能体(如homework 3中表达式树由许多Node子类和求导方法类组成),那么功能体中各类之间的相互依赖较多是否就属于正常现象?