上篇笔记记录了Local模式的一些内容,但是实际的应用中很少有使用Local模式的,只是为了我们方便学习和测试。真实的生产环境中,Standalone模式更加合适一点。
1、基础概述
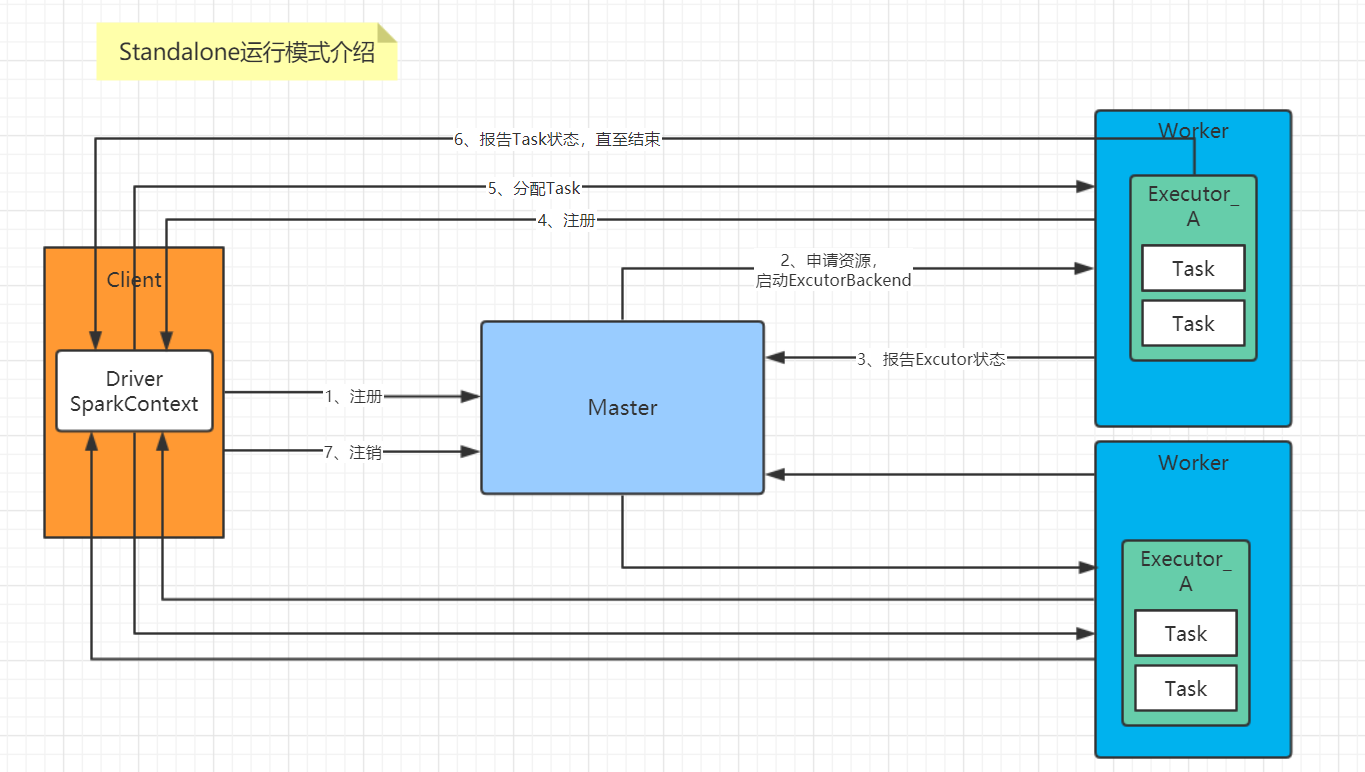
Standalone不是单机模式,它是集群,但是是基于Spark独立调度器的集群,也就是说它是Spark特有的运行模式。有Client和Cluster两种模式,主要区别在于:Driver程序的运行节点。怎么理解呢?哪里提交任务哪里启动Driver,这个叫做Client模式;随便找台机器启动Driver,这个叫做Cluster模式。
说白了就是只有Spark自己负责调度自己的集群,不用什么Yarn、Mesos。那么这样就没有Yarn的ResourceManager 、 NodeManager和Container了,它俩对应到Spark的概念是Master、Worker和Executor。
画了张图,解释Standalone运行模式:
2、安装使用
1)修改slave文件,添加work节点:
[simon@hadoop102 conf]$ vim slaves
hadoop102
hadoop103
hadoop104
2)修改spark-env.sh文件,添加如下配置:
[simon@hadoop102 conf]$ vim spark-env.sh
SPARK_MASTER_HOST=hadoop102
SPARK_MASTER_PORT=7077
3)分发spark包
[simon@hadoop102 module]$ xsync spark/
4)启动集群
[simon@hadoop102 spark]$ sbin/start-all.sh
#查看启动信息
hadoop103: JAVA_HOME is not set
hadoop103: full log in /opt/module/spark/logs/spark-simon-org.apache.spark.deploy.worker.Worker-1-hadoop103.out
报了异常信息:JAVA_HOME is not set,可以在sbin目录下的spark-config.sh 文件中加入如下配置:
export JAVA_HOME=/opt/module/jdk1.8.0_144
然后重新启动集群:
[simon@hadoop102 spark]$ sbin/start-all.sh
#查看启动信息
[simon@hadoop102 spark]$ jpsall
--------------------- hadoop102 -------------------------------
4755 NameNode
4900 DataNode
5704 NodeManager
6333 Master
6623 Worker
--------------------- hadoop103 -------------------------------
8342 DataNode
9079 NodeManager
10008 Worker
8893 ResourceManager
--------------------- hadoop104 -------------------------------
8882 NodeManager
8423 SecondaryNameNode
9560 Worker
8347 DataNode
可以看到Spark集群已经启动成功了,Hadoop102是Master节点,两外两个是Worker节点
5)执行一一个官方案例:
[simon@hadoop102 spark]$ bin/spark-submit
--class org.apache.spark.examples.SparkPi
--master spark://hadoop102:7077
--executor-memory 1G
--total-executor-cores 2
./examples/jars/spark-examples_2.11-2.1.1.jar
100
和local模式的区别就在于指定了master节点
执行结果:

3、JobHistoryServer配置
如果我们想看任务执行的日志信息,我们还需要配置历史服务器
1)修改spark-default.conf文件,开启Log:
[simon@hadoop102 conf]$ vi spark-defaults.conf
spark.eventLog.enabled true
#directory要事先创建好
spark.eventLog.dir hdfs://hadoop102:9000/directory
2)在HDFS上创建文件夹
[simon@hadoop102 hadoop]$ hadoop fs –mkdir /directory
3)修改spark-env.sh文件,添加如下配置:
[simon@hadoop102 conf]$ vi spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080
-Dspark.history.retainedApplications=30
-Dspark.history.fs.logDirectory=hdfs://hadoop102:9000/directory"
#参数描述:
spark.eventLog.dir:Application在运行过程中所有的信息均记录在该属性指定的路径下;
spark.history.ui.port=18080 WEBUI访问的端口号为18080
spark.history.fs.logDirectory=hdfs://hadoop102:9000/directory 配置了该属性后,在start-history-server.sh时就无需再显式的指定路径,Spark History Server页面只展示该指定路径下的信息
spark.history.retainedApplications=30指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
4)分发配置文件
[simon@hadoop102 conf]$ xsync spark-defaults.conf
[simon@hadoop102 conf]$ xsync spark-env.sh
5)启动历史服务器
[simon@hadoop102 spark]$ sbin/start-history-server.sh
6)再次执行任务
[simon@hadoop102 spark]$ bin/spark-submit
--class org.apache.spark.examples.SparkPi
--master spark://hadoop102:7077
--executor-memory 1G
--total-executor-cores 2
./examples/jars/spark-examples_2.11-2.1.1.jar
100
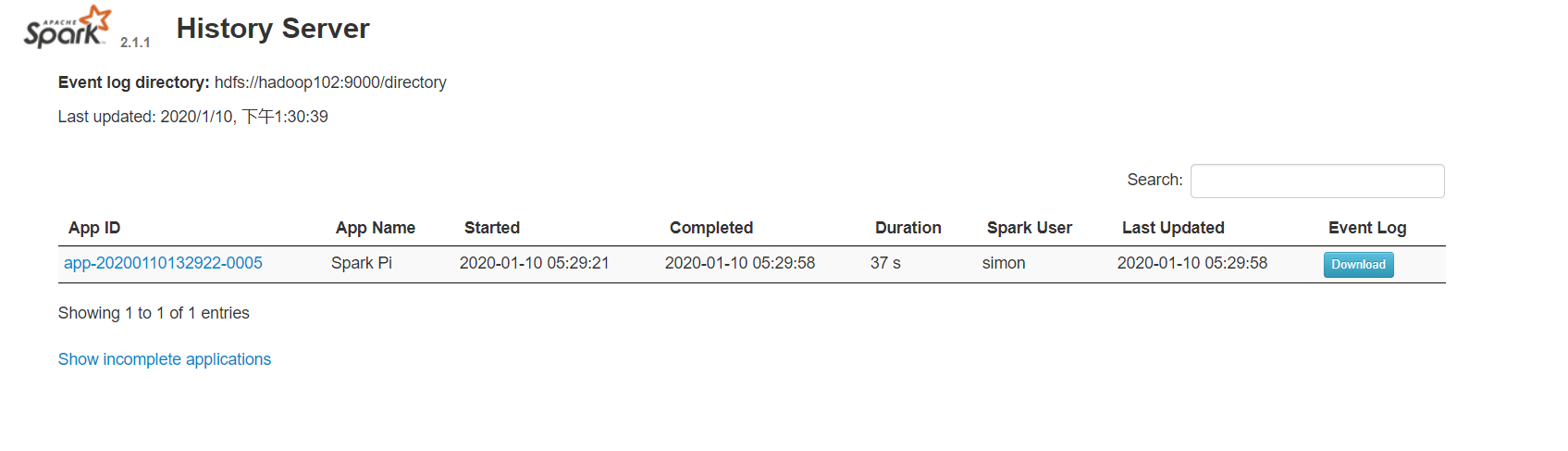
7)查看历史任务日志
hadoop102:18080
4、HA配置
Spark集群部署完了,但是有一个很大的问题,那就是 Master 节点存在单点故障,要解决此问题,就要借助 zookeeper,并且启动至少两个 Master 节点来实现高可靠,配置方式也比较简单。
HA模式的整体架构图:
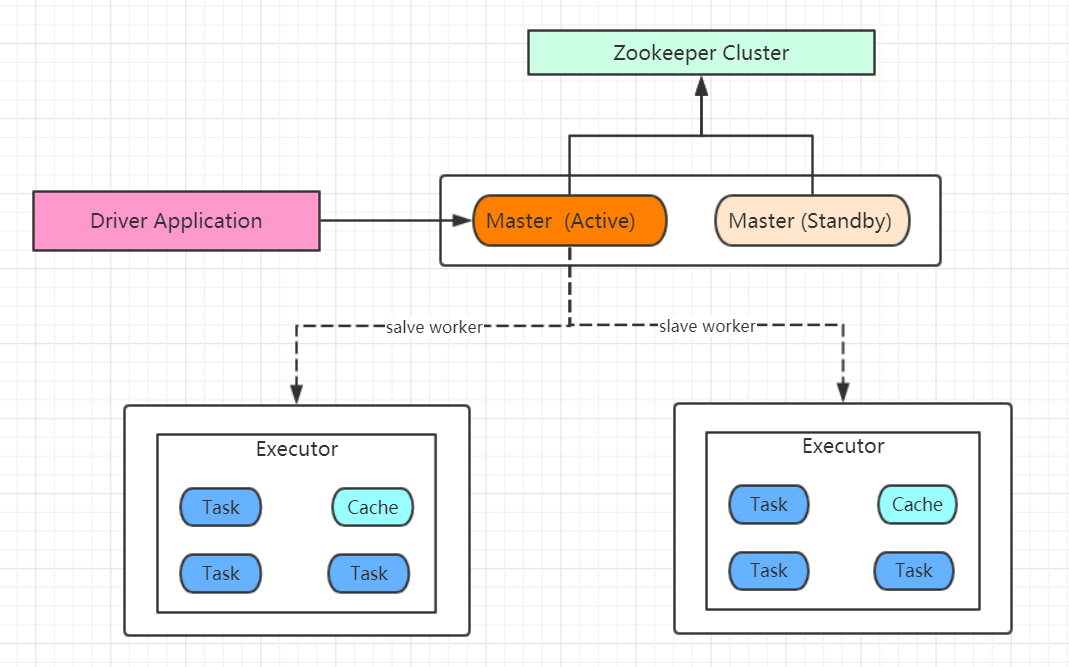
可以看到依赖了Zookeeper,其实和HDFS的HA运行模式差不多,那么开始着手配置。
1)zookeeper正常安装并启动
[simon@hadoop102 spark]$ zk-start.sh
[simon@hadoop102 spark]$ jpsall
--------------------- hadoop102 -------------------------------
8498 HistoryServer
4755 NameNode
4900 DataNode
5704 NodeManager
6333 Master
9231 QuorumPeerMain
6623 Worker
--------------------- hadoop103 -------------------------------
8342 DataNode
9079 NodeManager
10008 Worker
10940 QuorumPeerMain
8893 ResourceManager
--------------------- hadoop104 -------------------------------
11073 QuorumPeerMain
8882 NodeManager
8423 SecondaryNameNode
9560 Worker
8347 DataNode
QuorumPeerMain就是zookeeper的进程,可以看到已经正常启动了。
2)修改spark-env.sh文件添加如下配置:
[simon@hadoop102 conf]$ vi spark-env.sh
注释掉如下内容:
#SPARK_MASTER_HOST=hadoop102
#SPARK_MASTER_PORT=7077
添加上如下内容:
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop102,hadoop103,hadoop104
-Dspark.deploy.zookeeper.dir=/spark"
3)分发配置文件
[simon@hadoop102 conf]$ xsync spark-env.sh
4)在hadoop102上启动全部节点
[simon@hadoop102 spark]$ sbin/start-all.sh
5)在hadoop103上单独启动master节点
[simon@hadoop103 spark]$ sbin/start-master.sh
6)spark HA集群访问
/opt/module/spark/bin/spark-shell
--master spark://hadoop102:7077,hadoop103:7077
--executor-memory 2g
--total-executor-cores 2
在学习测试过程中并不常用,配起来测试一下就行了。Hadoop102、Hadoop103都是master,关闭Active的master,看到Master自动切换即可。
参考资料:
[1] 李海波. 大数据技术之Spark