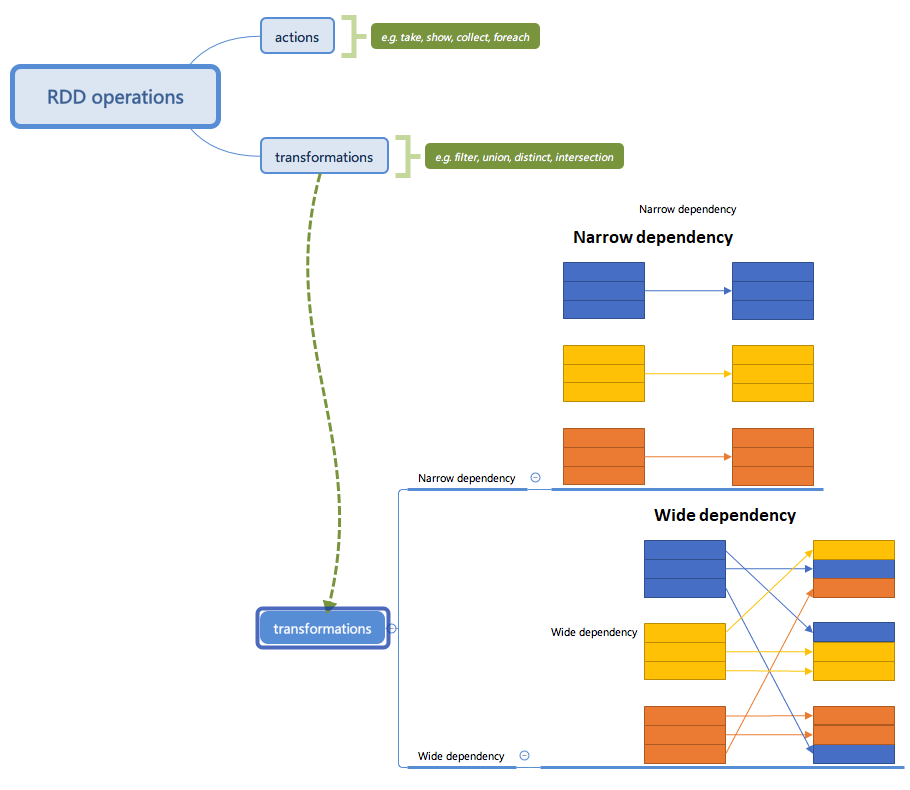
RDD operations:
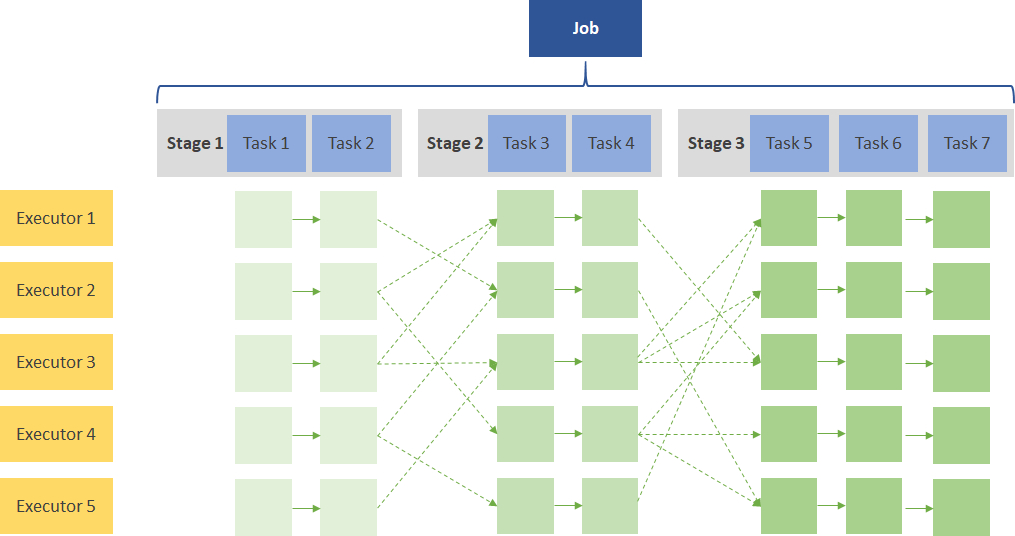
当RDD上有操作时,就会创建作业。在工作中,可能会有多个stages,这取决于我们是否需要进行wide dependency的转换(i.e. shuffles)。在每个阶段中,可以有一个或多个转换,映射到每个执行器中的tasks。
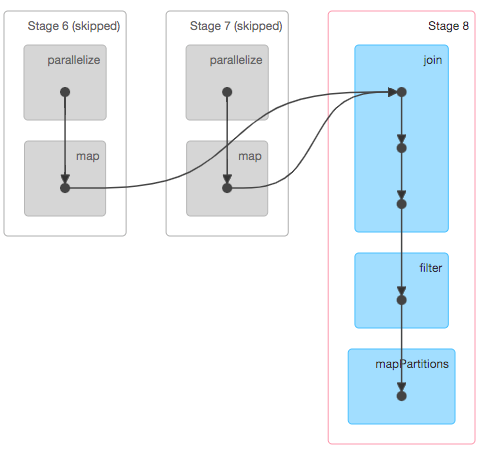
coding:
scala> val RDD1 = sc.parallelize(Array('1', '2', '3', '4', '5')).map{ x => val xi = x.toInt; (xi, xi+1) }
RDD1: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[1] at map at <console>:24
scala> val RDD2 = sc.parallelize(Array('1', '2', '3', '4', '5')).map{ x => val xi = x.toInt; (xi, xi*10) }
RDD2: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[3] at map at <console>:24
scala> val joinedData = RDD2.join(RDD1)
joinedData: org.apache.spark.rdd.RDD[(Int, (Int, Int))] = MapPartitionsRDD[6] at join at <console>:27
scala> val filteredRDD = joinedData.filter{case (k, v) => k % 2 == 0}
filteredRDD: org.apache.spark.rdd.RDD[(Int, (Int, Int))] = MapPartitionsRDD[7] at filter at <console>:25
scala> val resultRDD = filteredRDD.mapPartitions{ iter => iter.map{ case (k, (v1, v2) ) => (k, v1+v2) } }
resultRDD: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[8] at mapPartitions at <console>:25
scala> resultRDD.take(2)
res0: Array[(Int, Int)] = Array((50,551), (52,573))