承接上文 利用神经网络识别骰子点数
前言小叙
前一段时间通过bpnn反向传播神经网络实现了识别骰子点数的目标,而且效果不错,我们的识别率可以达到80%上下,其实已经可以应用于生产环境了。只不过读了卷积神经网络,第一次感受到原来还可以这样,感受到了新的世界观和人生观。
卷积这个词,第一次接触还是读图形处理的书的时候,中间会有卷积和滤波处理图片的内容,其实当时对于卷积也是懵懵懂懂,不明所以,无非就是一个个求积再求和,能有什么意义。不过这些天我算是有些明白了。
想通俗了解卷积的朋友可以访问这个链接。境外的朋友请看YouTube短视频,下面我会节选一些来说明卷积和滤波的好玩之处,如果你是一个自拍狂,经常使用滤镜功能,你会更容易体会到卷积的有用之处。
线性滤波和卷积的基本概念
线性滤波可以说是图像处理最基本的方法,它可以允许我们对图像进行处理,产生很多不同的效果。做法很简单。首先,我们有一个二维的滤波器矩阵(有个高大上的名字叫卷积核)和一个要处理的二维图像。然后,对于图像的每一个像素点,计算它的邻域像素和滤波器矩阵的对应元素的乘积,然后加起来,作为该像素位置的值。这样就完成了滤波过程。
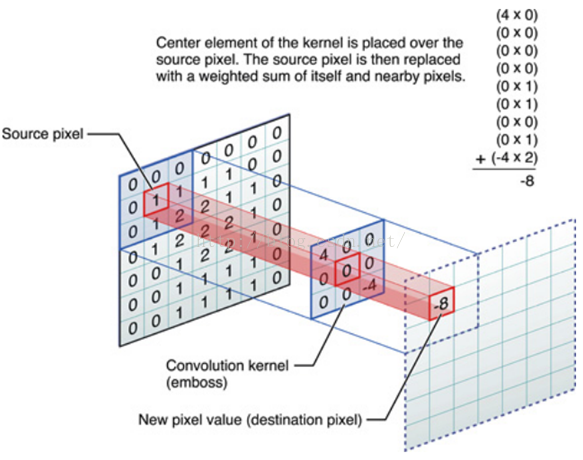
对图像和滤波矩阵进行逐个元素相乘再求和的操作就相当于将一个二维的函数移动到另一个二维函数的所有位置,这个操作就叫卷积或者协相关。卷积和协相关的差别是,卷积需要先对滤波矩阵进行180的翻转,但如果矩阵是对称的,那么两者就没有什么差别了。
上面这张图和这段话如果你还是想象不出怎么在一张图片上做卷积操作的话,我有下面的动态图:
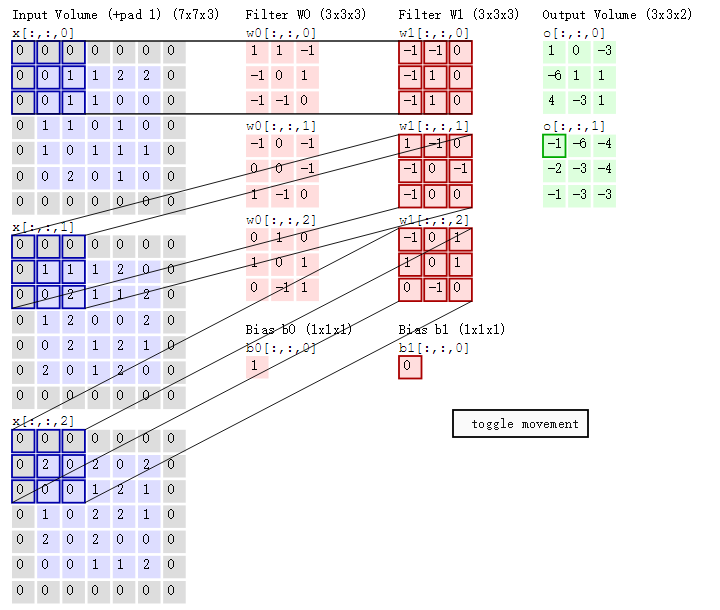
下面是一个3×3的卷积核在5×5的图像上做卷积的过程。每个卷积都是一种特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分筛选出来。所以,由4个通道卷积得到2个通道的过程中,参数的数目为4×2×2×2个,其中4表示4个通道,第一个2表示生成2个通道,最后的2×2表示卷积核大小。

- 左边是输入(7*7*3中,7*7代表图像的像素/长宽,3代表R、G、B 三个颜色通道)
- 中间部分是两个不同的滤波器Filter w0、Filter w1
- 最右边则是两个不同的输出
随着左边数据窗口的平移滑动,滤波器Filter w0 / Filter w1对不同的局部数据进行卷积计算。
值得一提的是:
- 左边数据在变化,每次滤波器都是针对某一局部的数据窗口进行卷积,这就是所谓的CNN中的局部感知机制。
- 打个比方,滤波器就像一双眼睛,人类视角有限,一眼望去,只能看到这世界的局部。如果一眼就看到全世界,你会累死,而且一下子接受全世界所有信息,你大脑接收不过来。当然,即便是看局部,针对局部里的信息人类双眼也是有偏重、偏好的。比如看美女,对脸、胸、腿是重点关注,所以这3个输入的权重相对较大。
- 与此同时,数据窗口滑动,导致输入在变化,但中间滤波器Filter w0的权重(即每个神经元连接数据窗口的权重)是固定不变的,这个权重不变即所谓的CNN中的参数(权重)共享机制。
- 再打个比方,某人环游全世界,所看到的信息在变,但采集信息的双眼不变。btw,不同人的双眼 看同一个局部信息 所感受到的不同,即一千个读者有一千个哈姆雷特,所以不同的滤波器 就像不同的双眼,不同的人有着不同的反馈结果。
我第一次看到上面这个动态图的时候,只觉得很炫,另外就是据说计算过程是“相乘后相加”,但到底具体是个怎么相乘后相加的计算过程 则无法一眼看出,网上也没有一目了然的计算过程。本文来细究下。
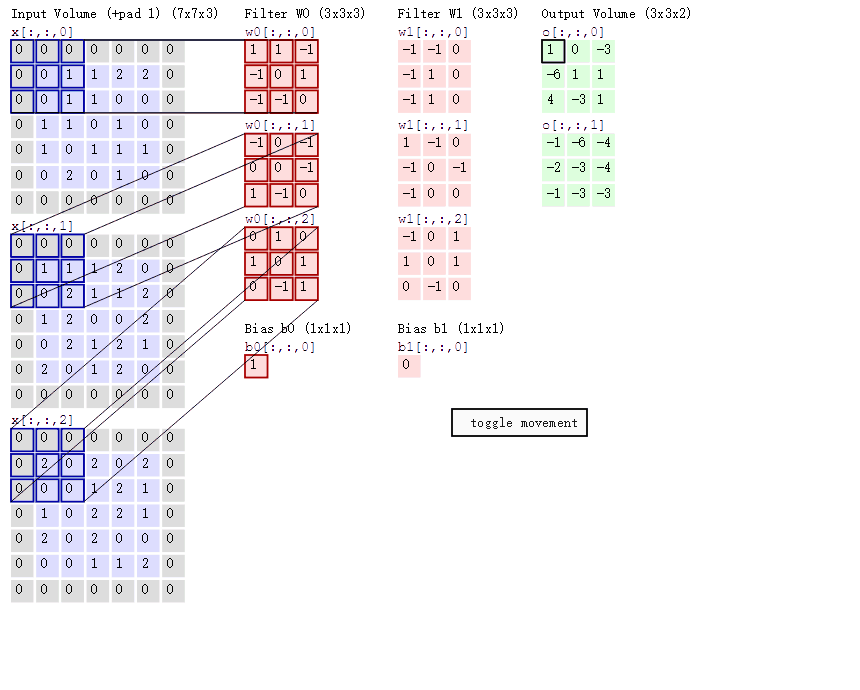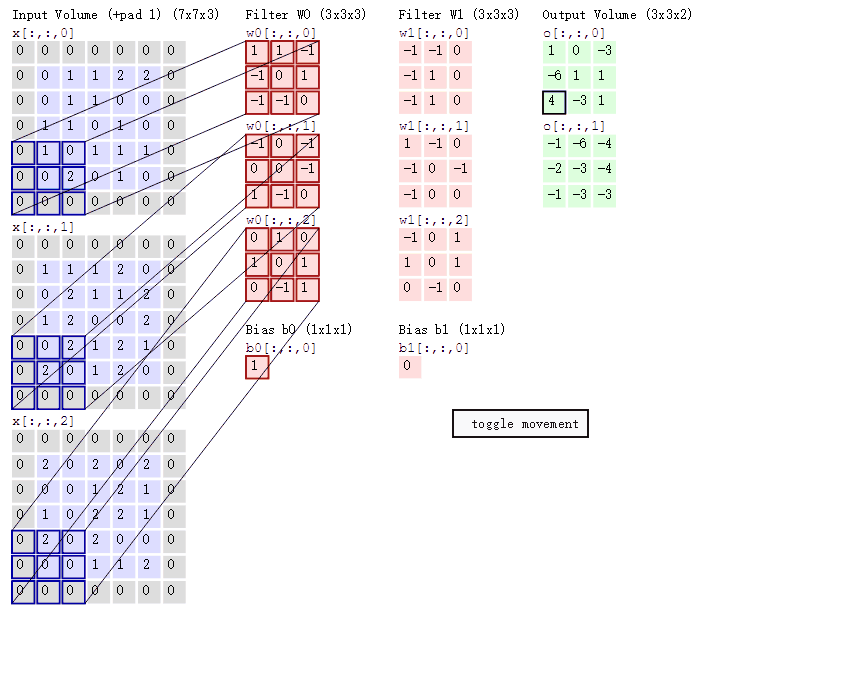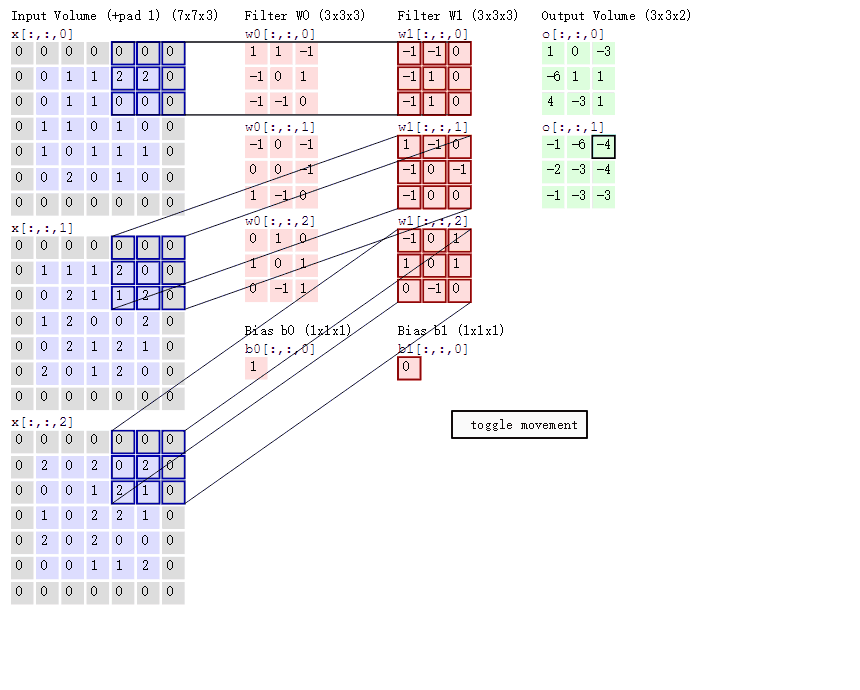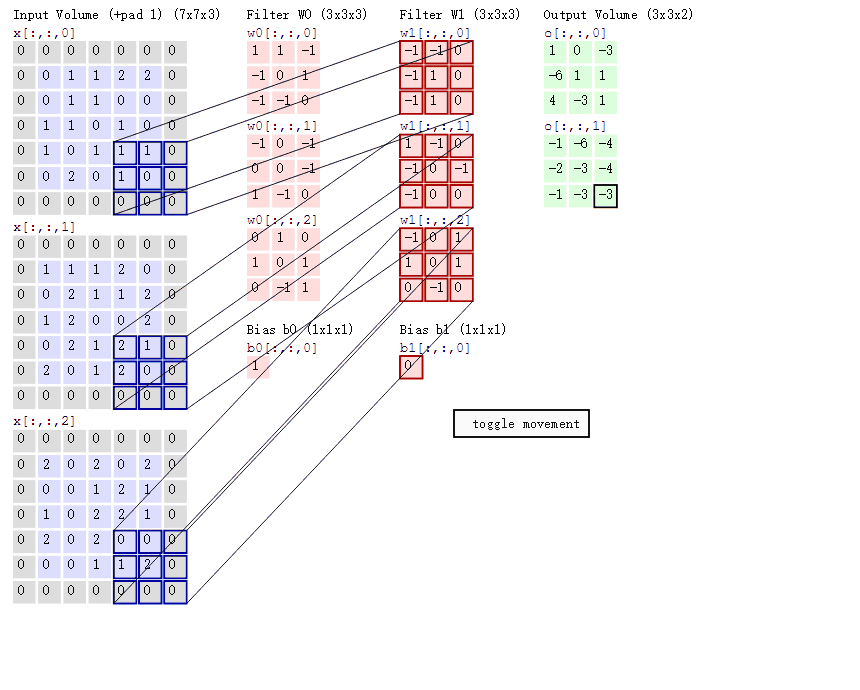
首先,我们来分解下上述动图,如下图
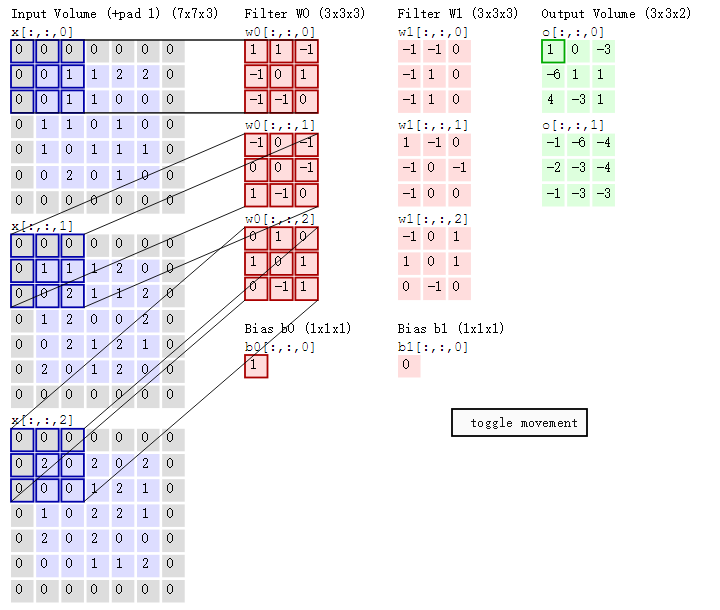
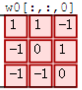
接着,我们细究下上图的具体计算过程。即上图中的输出结果1具体是怎么计算得到的呢?其实,类似wx + b,w对应滤波器Filter w0,x对应不同的数据窗口,b对应Bias b0,相当于滤波器Filter w0与一个个数据窗口相乘再求和后,最后加上Bias b0得到输出结果1,如下过程所示:
1* 0 + 1*0 + -1*0
+
-1*0 + 0*0 + 1*1
+
-1*0 + -1*0 + 0*1
+
-1*0 + 0*0 + -1*0
+
0*0 + 0*1 + -1*1
+
1*0 + -1*0 + 0*2
+
0*0 + 1*0 + 0*0
+
1*0 + 0*2 + 1*0
+
0*0 + -1*0 + 1*0
+
![]()
1
=
1


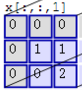
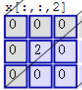
然后滤波器Filter w0固定不变,数据窗口向右移动2步,继续做内积计算,得到0的输出结果
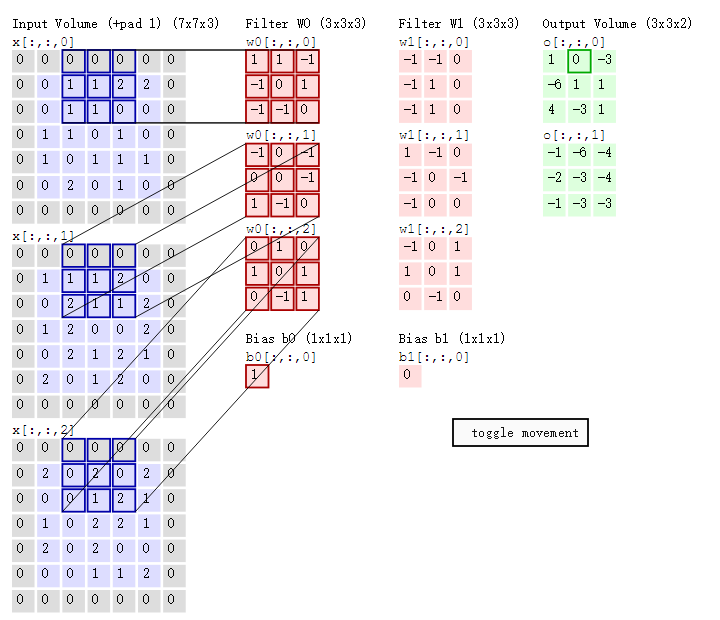
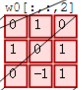
最后,换做另外一个不同的滤波器Filter w1、不同的偏置Bias b1,再跟图中最左边的数据窗口做卷积,可得到另外一个不同的输出。
扯了这么多,来点实际的,卷积对于神经网络究竟有什么好处呢?
如果你看了上面所有的计算过程,我们可以发现至少两个好处,一个是卷积降低了数据数量,可以说是抽提了数据,数据变得少,如果不使用卷积,我们普通的bpnn需要处理的数据将是非常巨大的。stdcoutzyx在博客中有过计算,你可以仔细看一下。卷积神经网络的另一个核心思想是:局部感受野(local field),权值共享以及时间或空间亚采样这三种思想结合起来,获得了某种程度的位移、尺度、形变不变性。说起来很炫吧,但是我也不知道如何解释,你可以参看此处。
Talk is cheap,show me the code. 话不多说,直接上代码。
trainCNN.m
%% CNN close all;clear all; train_dir=dir('train/*.jpg');%训练的文件夹 下面获取训练的文件列表 for i = 1: length(train_dir) imgs_name{i} = train_dir(i).name; end imgs_sample = cell(6);%样本分组 我们六个点数 分成六组 一组多少个样品就有多少数组 按照最多的那一组确定最大维度 imgs_sample_num = zeros(1,6);%6组数据,保存每一组数据最多多少个样本 例如[79,79,79,79,79,79] 表示第一组79样本 第二组79.... max_size = [0 0];% 这些样本中最大的长和宽 %% 将数字分类放置 for i = 1 : length(imgs_name)%每一张图 img_name = imgs_name{i};%取出名字img_name 例如1(2) imgs = im2bw(imread(['train/',img_name]));%读取图片 tmp_num = str2num(img_name(1)) ;%读取点数 imgs_sample_num(tmp_num) = imgs_sample_num(tmp_num) + 1; %在这一组里面 样本的下标加1 imgs_sample{tmp_num, imgs_sample_num(tmp_num)} = imgs;% 将这个样本 保存到imgs_sample 第一维是点数 第二维是样本的下标 tmp_size = size(imgs); % 样本图片的大小 下面两行分别获取图片的最大长和宽 if max_size(1,1) < tmp_size(1,1); max_size(1,1) = tmp_size(1,1); end%找最大的 宽度 if max_size(1,2) < tmp_size(1,2); max_size(1,2) = tmp_size(1,2); end%找最大的 长度 end max_size = [24 40];% 这些样本中最大的长和宽 %% 归一化所有样本,使其等大小 for i = 1 : 6% 对于这6类图像对象 例如数字0 for j = 1 : imgs_sample_num(i) %取其中一类 然后 遍历这一类里面多有的对象 temp = zeros(max_size);%[0 0] 例如max_size 是[32,30] imgs_size = size(imgs_sample{i, j});% 0 这一类的一张图 temp(1:imgs_size(1,1), 1:imgs_size(1,2)) = imgs_sample{i, j};%映射到最大的 imgs_sample{i, j} = temp; % imshow(temp); end end %cnn网络 runcnn(imgs_sample, imgs_sample_num, max_size);
runcnn.m
%%CNN 训练的主要步骤 function y = runcnn(imgs_sample, imgs_sample_num, max_size) path(path, 'DeepLearnToolbox-master/CNN/') path(path, 'DeepLearnToolbox-master/util/') % 网络训练集构造 [a, b] = buildtrainset_cnn(imgs_sample, imgs_sample_num); % 24×40的原图片 cnn.layers = { struct('type', 'i') %input layer struct('type', 'c', 'outputmaps', 6, 'kernelsize', 5) %convolution layer outputmaps 6个特征图输出 卷积大小是5*5 struct('type', 's', 'scale', 2) %sub sampling layer max pooling 层 2*2 struct('type', 'c', 'outputmaps', 12, 'kernelsize', 5) %convolution layer struct('type', 's', 'scale', 2) %sub sampling layer }; cnn = cnnsetup(cnn, a, b); % 学习率 opts.alpha = 2; % 每次挑出一个batchsize的batch来训练,也就是每用batchsize个样本就调整一次权值,而不是 % 把所有样本都输入了,计算所有样本的误差了才调整一次权值 opts.batchsize = size(a, 3); % 训练次数,用同样的样本集。我训练的时候: %100 200 500 2000 都没有效果 错误率 83 4000 的时候效果明显 错误率7 opts.numepochs = 4000; %训练模型 cnn = cnntrain(cnn, a, b, opts); %保存模型,为以后识别程序 save cnn; % 测试 image_dir=dir('test/*.jpg'); for i = 1: length(image_dir) str_name = image_dir(i).name; imgs_test{i} = str_name; end rightnum = 0;%正确个数 sumnum = 0;%总共样本 for i = 1 : length(imgs_test) sumnum=sumnum+1; img_name = imgs_test{i}; imgs = im2bw(imread(['test/',img_name]));%读取图片 tmp_num = str2num(img_name(1)); %% 等大小化 temp = zeros(max_size); imgs_size = size(imgs); temp(1:imgs_size(1,1), 1:imgs_size(1,2)) = imgs; imgs = temp; input_size = size(temp); testInput(:, :, 1) = reshape(temp', input_size(1,1), input_size(1,2)); testInput(:, :, 2) = reshape(temp', input_size(1,1), input_size(1,2)); % 然后就用测试样本来测试 cnn = cnnff(cnn, testInput); cnn.o [~, mans] = max(cnn.o); if mans(1,1)==tmp_num rightnum=rightnum+1; end % img_name % mans = mans end rightdata = [rightnum, sumnum-rightnum] rightnum/sumnum figure(88) pie(rightdata, {'right', 'wrong'}); %plot mean squared error figure(89) plot(cnn.rL); end
buildtrainset_cnn.m
% 创建数据集 function [inputs outputs] = buildtrainset_cnn(imgs, number) i = 1; for k = 1 : 6 for j = 1 : number(k) input = imgs{k, j}; input_size = size(input); inputs(:, :, i) = reshape(input', input_size(1,1), input_size(1,2));%这里的操作 转置矩阵 作为输入 outputs(:, i) = zeros(6, 1); outputs(k, i) = 1; i = i + 1; end end end
值得指出的是,cnn训练的时间比较久,而且最开始被他欺骗了,请看我上面代码的注释,如果只是训练100次或者500次,甚至2000次都不能够让我的模型有作用,我也是一直怀疑是不是我哪里的数据处理错了,或者哪个矩阵弄反了,又回过头仔细琢磨验证码识别的那个代码,以及DeepLearnToolbox的范例代码,还是觉得没有问题啊,果断决定将训练次数提升到4000次,这时候奇迹出现了,误差曲线在3500的时候下降到差不多3的样子,应该是我的数据比较大的问题吧。4000次训练在我机器上需要1个多小时,还是比较耗时的。
验证
RecognizeDiceCnn.m
load('cnn.mat'); max_size = [24 40];% 这些样本中最大的长和宽 filepath=input('请输入要识别的文件','s'); i=imread(filepath); figure(9) imshow(i); I=rgb2gray(i); BW=im2bw(I); I2 = imcrop(BW,[400 210 300 1000]);%大部分图像布局固定 I2 = bwareaopen(I2,200,8);%删除二值图像BW中面积小于P的对象,默认情况下使用8邻域。 cc = bwconncomp(I2,8);%bwconnecomp()是找出二值图像中连通的区域, CC返回结果,比如这样一幅图(简化便于理解): n=cc.NumObjects;%有多少个对象 Area =zeros(n,1);%我们有n个对象 的区域 Perimeter = zeros(n,1); MajorAxis = zeros(n,1); MinorAxis = zeros(n,1); k = regionprops(cc,'Area','Perimeter','MajorAxisLength','MinorAxisLength','Image');%用途是get the properties of region,即用来度量图像区域属性的函数。 mean =zeros(6:3); imgs = {}; for i =1:n Image = k(i).Image; figure(i) imshow(Image); end if n==3 load('cnn.mat'); % 测试 image_dir=dir('test/*.jpg'); for i = 1: length(image_dir) str_name = image_dir(i).name; imgs_test{i} = str_name; end for i = 1 : 3 imgs = k(i).Image ;%读取图片 %% 等大小化 temp = zeros(max_size); imgs_size = size(imgs); temp(1:imgs_size(1,1), 1:imgs_size(1,2)) = imgs; imgs = temp; input_size = size(temp); testInputs(:, :, i) = reshape(temp', input_size(1,1), input_size(1,2)); % 然后就用测试样本来测试 % [~, a] = max(y); % bad = find(mans ~= a); end cnn = cnnff(cnn, testInputs); cnn.o [~, mans] = max(cnn.o); fprintf('----------The Dice Point is -------------------') mans else fprintf('----------The Image Can not Split into 3 -------------------') return end
具体贴图我就不发了,和上一篇差不多。
总结
cnn貌似比bpnn正确率高那么一点点,也许是我调整了数据样本的缘故,总之可以通过此种方式实现识别这种功能,更新了我的世界观。
charles @ Phnom Penh 2016/12/28