目前常用的文字识别网络主要有两种,一种是通过CRNN+CTC的方法(参见CRNN),一种是seq2seq+attention的方法。有说CTC方法优于seq2seq+attention的,但随着attention机制的发展(self-attention, transformer),也许seq2seq+attention更有潜力,这里不做评价, 只是学习下seq2seq用于文字识别的思想。
1. seq2seq+attention模型介绍
seq2seq+attention来源于NLP领域,简要介绍下,详细信息参考下面链接:
https://zhuanlan.zhihu.com/p/36440334
https://zhuanlan.zhihu.com/p/28054589
https://zhuanlan.zhihu.com/p/150294471
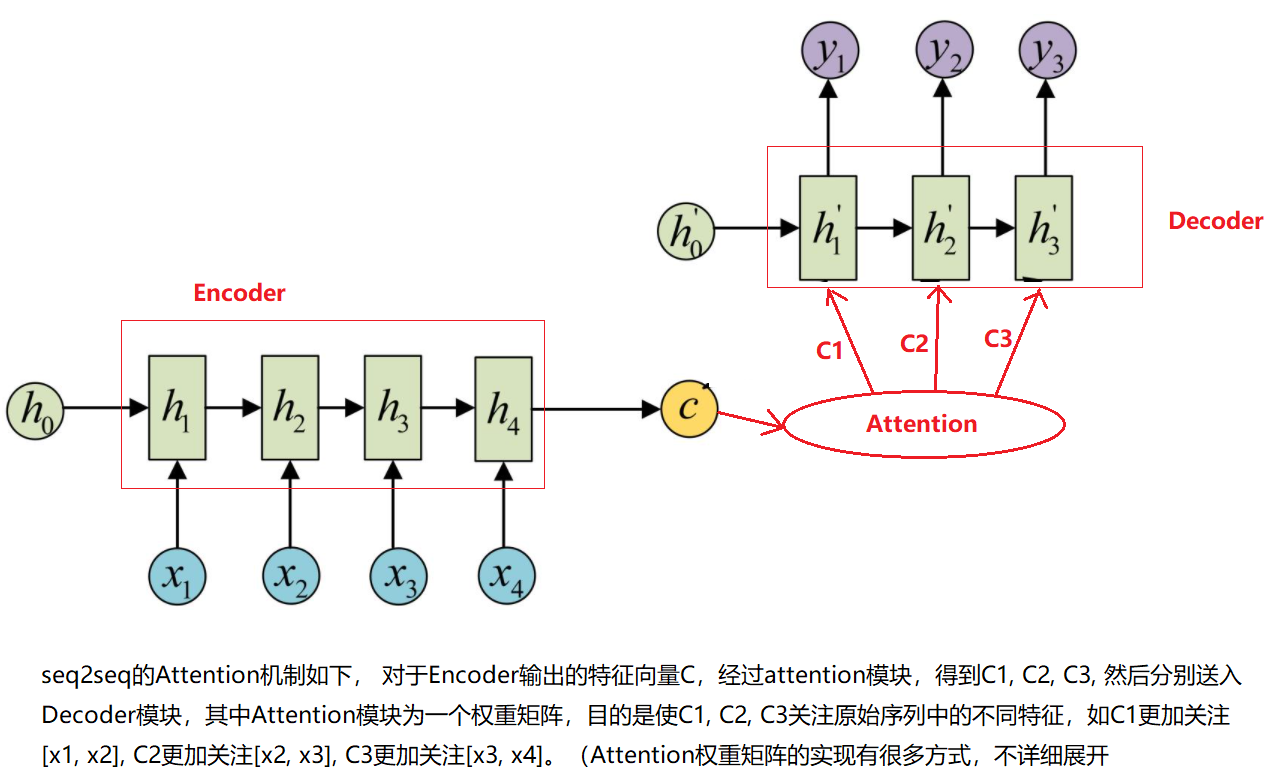
seq2seq模型主要用于机器翻译中,主要包括Encoder和Decoder两部分,两者都由循环神经网络RNN, LSTM或者GRU构成,如下图所示:序列[x1, x2, x3, x4]通过Encoder编码成特征向量C, C再经过Decoder解码成序列[y1, y2, y3], 这样就完成了序列[x1, x2, x3, x4到序列[y1, y2, y3]的映射

seq2seq的Attention机制如下, 对于Encoder输出的特征向量C,经过attention模块,得到C1, C2, C3, 然后分别送入Decoder模块,其中Attention模块为一个权重矩阵,目的是使C1, C2, C3关注原始序列中的不同特征,如C1更加关注[x1, x2], C2更加关注[x2, x3], C3更加关注[x3, x4]。(Attention权重矩阵的实现有很多方式,不详细展开)
2. seq2seq+attention用于文字识别
下面两篇华科的论文阐述了seq2seq用于文字识别的流程和方法,2018年ASTER是2016年RARE的改进版本,github上有两个pytorch实现代码可以参考学习下。
ASTER:An Attentional Scene Text Recognizer with Flexible Rectification(2018, ASTER) (参考实现代码:https://github.com/bgshih/aster,https://github.com/ayumiymk/aster.pytorch)
Robust Scene Text Recognition with Automatic Rectification(2016, RARE) (参考实现代码:https://github.com/bai-shang/crnn_seq2seq_ocr_pytorch)
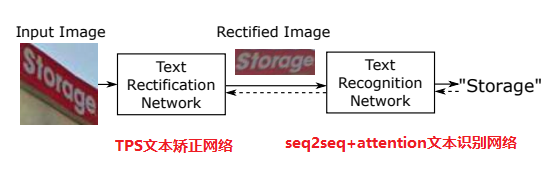
这里主要介绍下ASTER文章中的网络结构,网络主要包括两部分:TPS文本矫正网络,seq2seq+attention文本识别网络。一张图片先通过TPS对文本形变进行矫正,然后将矫正后的图片送入seq2seq+attention进行文字识别,如下入所示:
2.1 TPS文本矫正
由于自然界中的文本并不一定是水平排列的,存在各种各样的形变,如弯曲,旋转,透视等变化,如下图所示,所以需要一种变换来将其转换为接近水平的文本,方便后续的识别。2015年的论文Spatial Transformer Network(STN)提出了一种空间变换网络,可以通过模型学习到这种变换。这种变换中可以分为三大类:Aff仿射变换(affine transformation), Proj投影变换(project transformation), TPS薄板样条变换(thin plate spline transormation), 这里论文中采用了TPS变换

关于STN网络参考:
https://www.bilibili.com/video/BV1Ct411T7Ur?from=search&seid=9657204082977415895 (这个视频讲的很清楚)
https://zhuanlan.zhihu.com/p/37110107
https://www.cnblogs.com/liaohuiqiang/p/9226335.html
Spatial Transformer Networks Tutorial (https://pytorch.org/tutorials/intermediate/spatial_transformer_tutorial.html)
回到这篇论文里面,下图是其整体的STN结构示意图,包括Localisation net, Grid generator和Sampler三块。

Localisation net
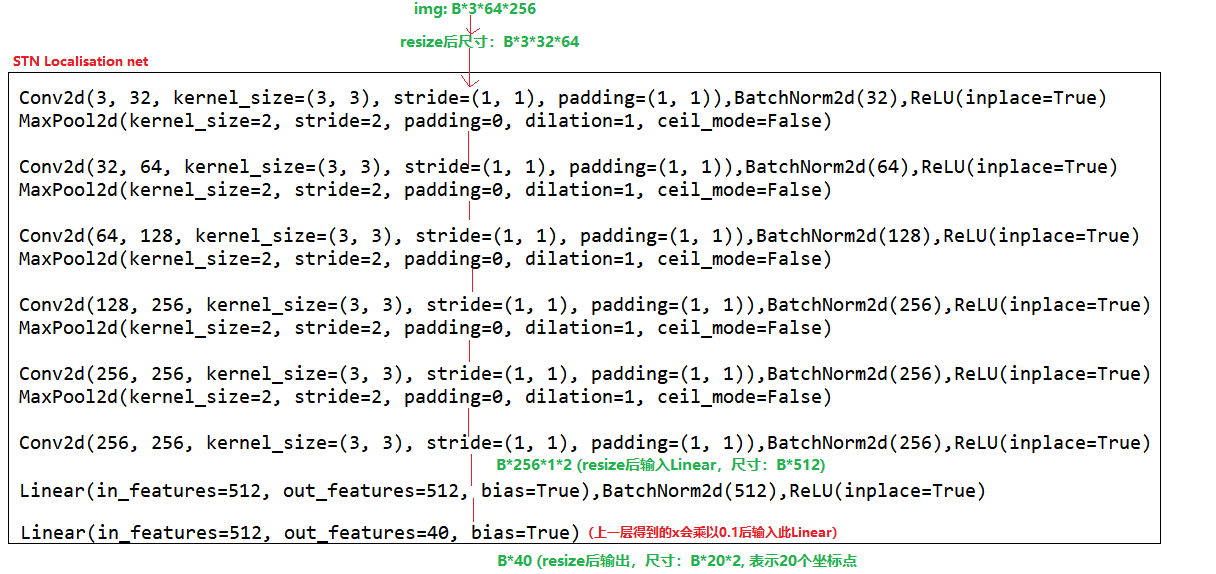
下面是论文中localisation net的卷积结构,可以发现其对输入图片先进行resize,然后进行卷积,最后得到20*2的矩阵,这20个坐标就是我们希望网络能学习到的20个定位点(control points)。
Grid generator
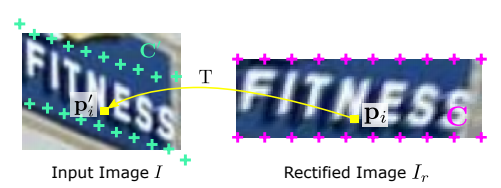
如下图左边是输入STN网络的图片,图片上绿色十字点就表示我们希望localisation net网络能学习到的20个定位点,得到这个20个定位点后,就该Grid generator发挥作用了。如图右边所示,Grid generator新建一个32*100的空白图片,然后设置20个坐标点,和localisation net学出来的20个坐标点相对应,假设Input Image上学到的20个坐标点矩阵为A(20*2), Rectified Image上设置的20个坐标点为矩阵B(20*2),Rectified Image上所有点的坐标点为矩阵C(3200*2),由B和A之间的映射关系可以计算一种由B到A的变换函数F,通过变换函数F,可以计算出矩阵C中所有坐标点在Input Image上对应的坐标点,假设变换后的矩阵为D(3200*2),将其resize成32*100*2, 其中每一个值,表示该点对应的Input Image中的坐标点
Sampler
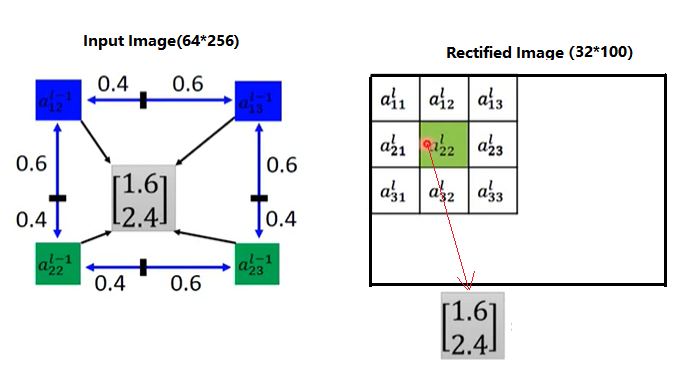
通过Grid generator可以得到一个32*100*2的矩阵坐标,如下图所示,假设Recified Image为32*100*2的矩阵,a22的值为(1.6, 2.4),表示Recified Image上(2, 2)像素点对应着Input Image上(1.6, 2.4),由于是小数,因此在Input Image上取(1.6,2.4)最近的四个像素点(1,2), (1,3),(2,2),(2,3),采用双线性插值法计算出(1.6, 2.4)的像素值,将Recified Image上(2, 2)处填充该像素值,依次处理整个Rectified Image,得到最终的图片(32*100*3)
2.2 seq2seq + attention文字识别网络
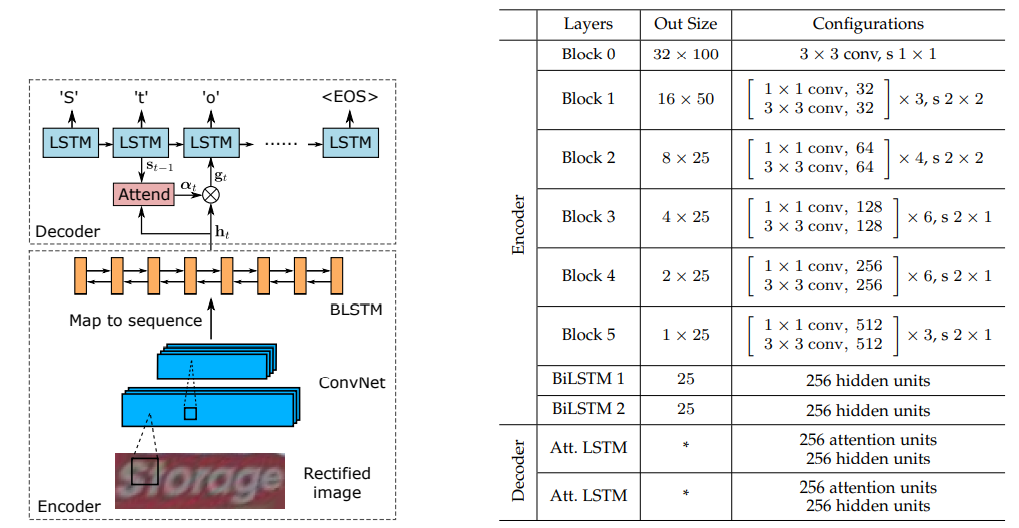
seq2seq+attention的网络包括:encoder编码网络和decoder解码网络,其整体结构如下图所示(左边是流程示意图,右边是具体的网络结构)。通过左边流程图,可以看到encoder网络通过cnn提取图片特征,BLSTM得到横向序列, decoder利用LSTM和attention机制对序列进行解码。右边网络结构可以看到encoder包括resnet+两层BiLSTM,类似于CRNN的特征提取模块,其中resnet模块包括5个block(对Resnet50进行了修改)。
seq2seq+attention的网络的整体细节如下图所示。在训练阶段,输入图片吗3*32*100经过encoder得到编码后的特征序列x (25*512),序列进入decoder会进行循环解码。每一次循环中,序列x和上一次的隐藏层输出state_prev进入attention模块得到注意力权重alpha,alpha和序列x相乘得到context,context和上一次的output_prev进行concatenate后送入GRU得到新的state和output。在测试阶段循环解码是会有些不同,一般会用到beam search。
关于seq2seq的beam search,参考:
https://zhuanlan.zhihu.com/p/82829880
https://zhuanlan.zhihu.com/p/36029811?group_id=972420376412762112

参考文章:
https://www.cnblogs.com/Allen-rg/p/10072162.html (ASTER)
https://zhuanlan.zhihu.com/p/183182208 (公式识别)
https://zhuanlan.zhihu.com/p/65707543