Embedded-Programming-with-the-GNU-Toolchain
Vijay Kumar B.
翻译整理:thammer
github:https://github.com/tanghammer/Embedded-Programming-with-the-GNU-Toolchain.git
目录
1.介绍
GNU工具链越来越多地用于深度嵌入式软件开发。这种类型的软件开发也称为独立C语言编程和裸机C语言编程。独立的C语言编程带来了新的问题,处理这些问题需要对GNU工具链有更深入的理解。GNU工具链的手册提供了关于工具链的优秀信息,但是是从工具链的角度,而不是从问题的角度。不管怎样,手册就是这样写的。其结果是对常见问题的答案分散在各地,GNU工具链的新用户感到困惑。
本教程试图通过从问题的角度解释这些工具来弥补这一差距。希望这能使更多的人在他们的嵌入式项目中使用GNU工具链。
本教程使用Qemu模拟了一个基于ARM的嵌入式系统。有了它,您可以从舒适的桌面环境中学习GNU工具链,而无需在硬件上进行投资。本教程本身并不教授ARM指令集。它应该与其他书籍和在线教程一起使用,比如:
但是为了方便读者,附录中列出了常用的ARM指令。
2.建立ARM实验室
本节展示如何使用Qemu和GNU工具链在您的PC中设置一个简单的ARM开发和测试环境。Qemu是一个机器模拟器,能够模拟各种机器,包括基于ARM的机器。您可以编写ARM汇编程序,使用GNU工具链编译它们,并在Qemu中执行和测试它们。
2.1.Qemu ARM
Qemu将用于模拟Gumstix基于PXA255的connex板。您应该至少拥有0.9.1版本的Qemu来使用本教程。
PXA255有一个ARMv5TE指令集的ARM内核。PXA255也有几个片上外设。本教程将介绍一些外围设备。
2.2.在Debian中安装Qemu
本教程要求qemu版本0.9.1或更高。Debian Squeeze/Wheezy中提供的qemu包满足这一要求。使用apt-get安装qemu。
$ apt-get install qemu
2.3.安装ARM GNU工具链
-
CodeSourcery (Mentor Graphics的一部分)提供了可用于各种体系架构的GNU工具链。下载用于ARM的GNU工具链,可从:
http://www.mentor.com/embedded-software/sourcery-tools/sourcery-codebench/editions/lite-edition/ -
解压至
~/toolchains。$ mkdir ~/toolchains $ cd ~/toolchains $ tar -jxf ~/downloads/arm-2008q1-126-arm-none-eabi-i686-pc-linux-gnu.tar.bz2 -
工具链路径添加至环境变量
PATH$ PATH=$HOME/toolchains/arm-2008q1/bin:$PATH -
在
.bashrc中添加并导出PATH。
3.Hello ARM
在本节中,您将学习如何汇编一个简单的ARM程序,并用Qemu模拟connex裸机板进行测试。
汇编程序源文件由一系列语句组成,每行一个。每个语句都具有以下格式。
label: instruction @ comment
每个部分都是可选的。
label:
- 标签是一种方便的方法来引用指令在内存中的位置。标签可以用于任何地址出现的地方,例如作为分支指令的操作数(
b label)。标签由字母,数字,_和$组成。
comment:
- 注释以@开头,在@号之后出现的字符会被编译器忽略。
instruction:
- 指令可以是ARM指令集里面的指令或者汇编器的指令。汇编器的指令是给汇编器的命令。汇编器指令由
.号打头。
下面是一个非常简单的ARM汇编程序,实现2个数相加。
Listing 1. Adding Two Numbers
.text
start: @ Label, not really required
mov r0, #5 @ Load register r0 with the value 5
mov r1, #4 @ Load register r1 with the value 4
add r2, r1, r0 @ Add r0 and r1 and store in r2
stop: b stop @ Infinite loop to stop execution
.text是一个汇编器指令,是说接下来的指令必须汇编到代码段(code section),而不是数据段(data section)。段(sections)这个概念会在后面的教程中详细介绍。
3.1.构建二进制文件
将程序保存至文件add.s中。要汇编此文件,需要调用GNU工具链的汇编器as,命令如下。
$ arm-none-eabi-as -o add.o add.s
-o选项指定了输出文件的名字。
注意:交叉工具链总是以构建它们的目标体系结构为前缀,以避免与主机工具链的名称冲突。为了可读性,我们将在文本中引用不带前缀的工具。

要生成可执行文件,需要调用GNU工具链的连接器ld,命令如下。
$ arm-none-eabi-ld -Ttext=0x0 -o add.elf add.o
这里,-o选项再次指定了输出文件名。-Ttext=0x0,指定了分配给标签的地址,以便指令从地址0x0开始。可以通过nm命令查看各标签的地址分配情况。
$ arm-none-eabi-nm add.elf
00008010 T __bss_end__
00008010 T _bss_end__
00008010 T __bss_start
00008010 T __bss_start__
00008010 T _edata
00008010 T _end
00008010 T __end__
00000000 t start
U _start
0000000c t stop
现在只关注标签start和stop。注意标签start和stop的地址分配。分配给start的地址是0x0。因为它是第一条指令的标签。标签stop在3条指令之后。每条指令占4个字节。因此stop分配的地址是12(0xC)。
为指令链接不同的基址将导致为标签分配一组不同的地址。
$ arm-none-linux-gnueabi-ld -Ttext=0x20000000 add.o -o add.elf
$ arm-none-linux-gnueabi-nm add.elf
20008010 T __bss_end__
20008010 T _bss_end__
20008010 T __bss_start
20008010 T __bss_start__
20008010 T _edata
20008010 T _end
20008010 T __end__
20000000 t start
U _start
2000000c t stop
ld生成的输出文件格式是ELF。有多种文件格式可用于存储可执行代码。ELF格式在有操作系统的情况下工作得很好,但是由于我们要在裸机上运行程序,所以必须将其转换为更简单的文件格式,称为二进制格式。
二进制格式的文件包含特定内存地址的连续字节。该文件中不存储其他附加信息。这对于Flash编程工具来说很方便,因为编程时所要做的就是将文件中的每个字节复制到从内存中指定的基址开始的连续地址。
GNU工具链的objcopy命令能用于转换不同的目标文件格式。常见的用法如下。
objcopy -O <output-format> <in-file> <out-file>
下面的命令用于将add.elf转换为二进制格式。
$ arm-none-eabi-objcopy -O binary add.elf add.bin
检查文件的大小。该文件将恰好是16个字节。因为有4条指令,每条指令占用4个字节。
$ ls -la add.bin
-rwxrwxr-x 1 thomas thomas 16 3月 23 17:56 add.bin
3.2.在Qemu里面执行
当ARM处理器复位时,它就从0x0地址开始执行。在connex板上有一个16MB的Flash位于地址0x0。在Flash开始处的指令将被执行。
当用qemu仿真connex板时,必须指定将哪个文件当作Flash使用。Flash文件给谁非常简单。为了从Flash中的地址X获取字节,qemu从文件中的偏移量X读取字节。事实上,这与二进制文件格式相同。
为了测试这个程序,我们首先在模拟的Gumstix connex板上创建一个16MB的文件来表示Flash。我们使用dd命令将16MB的0从/dev/zero复制到文件flash.bin。数据以4K块的形式复制。
$ dd if=/dev/zero of=flash.bin bs=4096 count=4096
然后使用以下命令将add.bin文件复制到Flash的开头。
$ dd if=add.bin of=flash.bin bs=4096 conv=notrunc
这相当于将bin文件烧录到Flash上。
复位之后,处理器将从地址0x0开始执行,程序中的指令将被执行。下面给出了调用qemu的命令。
$ qemu-system-arm -M connex -pflash flash.bin -nographic -serial /dev/null
-M connex选项指定要模拟的机器是connex。-pflash选项指定Flash .bin文件表示闪存。-nographic指定不需要模拟图形显示。-serial /dev/null指定将connex板的串口连接到/dev/null,以便丢弃串口数据。
系统执行指令,完成后,在stop: b stop指令中无限循环。要查看寄存器的内容,可以使用qemu的监视器接口。监控接口是一个命令行接口,通过它可以控制仿真系统并查看系统状态。当qemu使用上述命令启动时,监视器接口在qemu的标准I/O中提供(就是指可以以敲命令的方式交互)。
要查看寄存器的内容,可以使用info register命令。
(qemu) info registers
R00=00000005 R01=00000004 R02=00000009 R03=00000000
R04=00000000 R05=00000000 R06=00000000 R07=00000000
R08=00000000 R09=00000000 R10=00000000 R11=00000000
R12=00000000 R13=00000000 R14=00000000 R15=0000000c
PSR=400001d3 -Z-- A svc32
注意寄存器R02中的值。寄存器包含加法的结果,并且应该与期望值9匹配。
3.3.更多的监视器命令
表列出了一些有用的qemu监视器命令。
| 命令 | 用途 |
|---|---|
| help | 列出可用的命令 |
| quit | 退出模拟器 |
| xp /fmt addr | 从addr转储物理内存 |
| system_reset | 复位系统 |
详细解释下xp命令。fmt参数指定如何显示内存内容。fmt的语法是<count><format><size>。
count
- 指定count个要转储的数据项。
size
- 指定每个数据项的大小。
b代表8位,h代表16位,w代表32位,g代表64位。
format
- 指定显示格式。
x表示十六进制,d表示有符号十进制数,u表示无符号十进制数,o表示八进制,c表示char,i表示asm指令。
使用带有i格式的xp命令,可以用来反汇编内存中的指令。要反汇编位于0x0的指令,可以使用xp命令,将fmt指定为4iw。4指定要显示4项,i指定要打印的项作为指令(相当于一个内置的反汇编器!),w指定这些项的大小为32位。命令的输出如下所示。
(qemu) xp /4iw 0x0
0x00000000: mov r0, #5 ; 0x5
0x00000004: mov r1, #4 ; 0x4
0x00000008: add r2, r1, r0
0x0000000c: b 0xc
4.更多的汇编器指令
在此章节,我们通过2个示例程序介绍常用的汇编器指令。
- 对数组求和的程序
- 计算字符串长度的程序
4.1.数组求和
下面的代码对一个数组求和,并将结果存储在r3中。
Listing 2. Sum an Array
.text
entry: b start @ Skip over the data
arr: .byte 10, 20, 25 @ Read-only array of bytes
eoa: @ Address of end of array + 1
.align
start:
ldr r0, =eoa @ r0 = &eoa
ldr r1, =arr @ r1 = &arr
mov r3, #0 @ r3 = 0
loop: ldrb r2, [r1], #1 @ r2 = *r1++
add r3, r2, r3 @ r3 += r2
cmp r1, r0 @ if (r1 != r2)
bne loop @ goto loop
stop: b stop
该代码引入了两个新的汇编器指令--.byte和.align。下面将描述这些汇编器指令。
4.1.1. .byte指令
.byte的字节大小参数被汇编成内存中的连续字节。对于存储16位值和32位值,有类似的.2byte和.4byte指令。一般语法如下所示。
.byte exp1, exp2, ...
.2byte exp1, exp2, ...
.4byte exp1, exp2, ...
参数可以是简单的整数,表示为二进制(前缀为0b或0B)、八进制(前缀为0)、十进制(无前缀,不要以0开头,避免被当做八进制处理)或十六进制(前缀为0x或0X)。整数也可以表示为字符常量(由单引号包围的字符),在这种情况下将使用字符的ASCII值。
参数也可以是由文字和其他符号构造的C表达式。示例如下所示。
pattern: .byte 0b01010101, 0b00110011, 0b00001111
npattern: .byte npattern - pattern
halpha: .byte 'A', 'B', 'C', 'D', 'E', 'F'
dummy: .4byte 0xDEADBEEF
nalpha: .byte 'Z' - 'A' + 1
4.1.2. .align指令
ARM要求指令出现在32位对齐的内存位置。指令中4个字节中的第一个字节的地址应该是4的倍数。要做到这一点,可以使用.align指令插入填充字节,直到下一个字节地址是4的倍数。只有当在代码中插入数据字节或半字时才需要这样做。
4.2.字符串长度
下面的代码计算字符串的长度,并将长度存储在寄存器r1中。
Listing 3. String Length
.text
b start
str: .asciz "Hello World"
.equ nul, 0
.align
start: ldr r0, =str @ r0 = &str
mov r1, #0
loop: ldrb r2, [r0], #1 @ r2 = *(r0++)
add r1, r1, #1 @ r1 += 1
cmp r2, #nul @ if (r1 != nul)
bne loop @ goto loop
sub r1, r1, #1 @ r1 -= 1
stop: b stop
该代码引入了两个新的汇编器指令- .asciz和.equ。下面描述汇编器指令。
4.2.1. .asciz指令
.asciz指令接受字符串文本作为参数。字符串文字是双引号中的字符序列。字符串文字被汇编成连续的内存位置。汇编器在每个字符串后面自动插入一个nul字符(�字符)。
'ascii指令与.asciz相同,但是汇编器不会在每个字符串后面插入nul字符。
4.2.2. .equ指令
汇编器维护称为符号表的东西。符号表将标签名称映射到地址。每当汇编器遇到标签定义时,汇编器在符号表中做一个入口点。每当汇编器遇到标签引用时,它就用符号表中对应地址替换标签。
使用汇编器的指令.equ,还可以手动插入符号表中的条目,将名称映射到不一定是地址的值。每当汇编器遇到这些名称时,它就用它们对应的值替换它们。这些名称和标签名称一起称为符号名。
该指令的一般语法如下所示。
.equ name, expression
name是一个符号名称,并且具有与标签名称相同的限制。expression可以是简单的字符,也可以是.byte指令解释的表达式。
注意:
与.byte指令不同,.equ指令本身不分配任何内存。它们只是在符号表中创建条目。
5.使用RAM
存储前面示例程序的闪存是一种EEPROM。它是一个有用的辅助存储,就像硬盘一样,但是不方便在Flash中存储变量。变量应该存储在RAM中,这样就可以很容易地修改它们。
connex板有一个64 MB的RAM,从地址0xA0000000开始,其中可以存储变量。connex板的内存映射如下图所示。
Figure 1. Memory Map
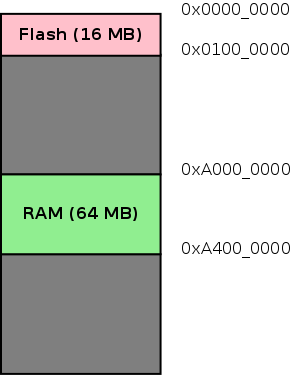
必须进行必要的设置才能将变量放在这个地址。要理解必须做什么设置,必须理解汇编器和链接器的角色。
6.链接器
当编写一个多源文件的程序时,每个文件被单独汇编为目标文件。链接器将这些目标文件组合起来形成最终的可执行文件。
Figure 2. Role of the Linker
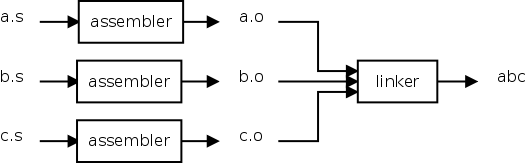
当组合目标文件在一起时,链接器执行了如下操作。
- 符号解析
- 重定位
在本节中,我们将详细研究这些操作。
6.1.符号解析
在单文件程序中,在生成目标文件时,所有对标签的引用都由汇编器用它们的对应地址替换。但在多文件程序中,如果有对另一个文件中定义的标签的任何引用,则汇编器将这些引用标记为“未解析(unresolved)”。当这些目标文件传递给链接器时,链接器将从其他目标文件确定这些引用的值,并使用正确的值对代码进行调整(patch)。
sum of array示例被分成两个文件,以演示链接器执行符号解析。这两个文件将被汇编起来,并检查它们的符号表,以显示未解析引用的存在。
文件sum-sub.s包含sum子程序,文件main.s传入所需的参数调用子程序。这些文件的源代码如下所示。
Listing 4. main.s - Subroutine Invocation
.text
b start @ Skip over the data
arr: .byte 10, 20, 25 @ Read-only array of bytes
eoa: @ Address of end of array + 1
.align
start:
ldr r0, =arr @ r0 = &arr
ldr r1, =eoa @ r1 = &eoa
bl sum @ Invoke the sum subroutine
stop: b stop
Listing 5. sum-sub.s - Subroutine Definition
@ Args
@ r0: Start address of array
@ r1: End address of array
@
@ Result
@ r3: Sum of Array
.global sum
sum: mov r3, #0 @ r3 = 0
loop: ldrb r2, [r0], #1 @ r2 = *r0++ ; Get array element
add r3, r2, r3 @ r3 += r2 ; Calculate sum
cmp r0, r1 @ if (r0 != r1) ; Check if hit end-of-array
bne loop @ goto loop ; Loop
mov pc, lr @ pc = lr ; Return when done
关于.global指令的解释是由必要的。在C中,在函数外部声明的所有变量对其他文件都是可见的,直到明确说明为static。在汇编中,所有标签都是static的,也称本地(对文件而言),直到明确声明它们应该对其他文件可见,这时就需要使用.global指令来修饰。
文件被汇编后,并使用nm命令转储符号表。
$ arm-none-eabi-as -o main.o main.s
$ arm-none-eabi-as -o sum-sub.o sum-sub.s
$ arm-none-eabi-nm main.o
00000004 t arr
00000007 t eoa
00000008 t start
00000018 t stop
U sum
$ arm-none-eabi-nm sum-sub.o
00000004 t loop
00000000 T sum
现在,关注第二列的字母,它指定了符号的类型。t表示这个符号在text段是定义了的。u表示这个符号未定义。大写字母表示符号是.global的。
很明显符号sum在sum-sub.o中定义了,不过在main.o中还未解析。当链接器被调用后,符号引用被解析,然后生成可执行文件。
6.2.重定位
重定位是改变标签已分配地址的过程。这还包括调整所有标签的引用地址以使对应上最新分配的地址。重定位主要基于以下两个原因:
- 段合并
- 段排布
要理解重新定位的过程,理解段的概念是必不可少的。
代码和数据有不同的run-time需求。例如代码可以放置在只读的存储介质中,数据则要放置在读-写存储介质中。如果代码和数据不混在一起,也许会更合适。为此,程序被分割为段。大多程序至少包含2个段,.text段放代码,.data段放数据。汇编器指令.text和.data用于在这两个段间来回切换。
可以把每个段想象成一个桶。当汇编器识别到一个段指令时,它会把紧跟指令的代码/数据放到对应的桶里面。因此,属于特定段的代码/数据的位置是紧挨着的。下面的图显示了汇编器如何将数据重新排列到段中。
Figure 3. Sections
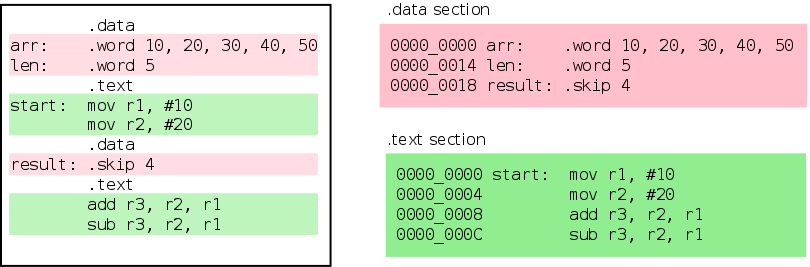
现在我们已经了解了段,让我们看看执行重定位的主要原因。
6.2.1.段合并
当处理多源文件程序时,在每个文件中可能会出现同样名字的段(例如.text)。链接器负责将输入文件的段合并到一起放到输出文件对应的段中。默认情况下,拥有同样名字的段会被放置到一起,标签引用的地址也会被调整到对应的新的地址上。
通过查看目标文件和相应的可执行文件的符号表,可以看到段合并的效果。多源文件的sum of array程序可以用来阐明段合并。目标文件main.o、sum-sum.o和可执行文件sum.elf的符号表如下所示。
$ arm-none-eabi-nm main.o
00000004 t arr
00000007 t eoa
00000008 t start
00000018 t stop
U sum
$ arm-none-eabi-nm sum-sub.o
00000004 t loop ❶
00000000 T sum
$ arm-none-eabi-ld -Ttext=0x0 -o sum.elf main.o sum-sub.o
$ arm-none-eabi-nm sum.elf
...
00000004 t arr
00000007 t eoa
00000008 t start
00000018 t stop
00000028 t loop ❷
00000024 T sum
❶ ❷ loop符号在sum-sub.o中地址是0x4,在sum.elf中地址是0x28。这是因为sum-sub.o的.text段恰好放置在main.o的.text之后。
6.2.2.段排布
当一个程序被汇编后,它的每个段都假定从0地址开始。因此,标签被分配的值是相对于段的起始处的。最后可执行文件生成时,段被放置到某个地址X上。并且所有对该部分中定义的标签的引用都被加上一个X的偏移,因此它们指向新的位置。
每个段在内存中的特定位置的排布,对段中每个标签引用的调整都是由链接器来完成的。
通过查看目标文件的符号表和相应的可执行文件,可以看到段排布的效果。单源文件的sum of array程序可以用来说明节的位置。为了更清楚,我们将把.text段放在地址0x100处。
$ arm-none-eabi-as -o sum.o sum.s
$ arm-none-eabi-nm -n sum.o
00000000 t entry ❶
00000004 t arr
00000007 t eoa
00000008 t start
00000014 t loop
00000024 t stop
$ arm-none-eabi-ld -Ttext=0x100 -o sum.elf sum.o ❷
$ arm-none-eabi-nm -n sum.elf
00000100 t entry ❸
00000104 t arr
00000107 t eoa
00000108 t start
00000114 t loop
00000124 t stop
...
❶ 在一个段内,标签的地址从0开始分配。
❷ 创建可执行文件时,指定链接器将.text段放在地址0x100处。
❸ .text段中标签的地址被从地址0x100处开始重新分配,所有标签引用都被调整反应了这一点。
段合并、段排布的过程如下图所示。
Figure 4. Section Merging and Placement
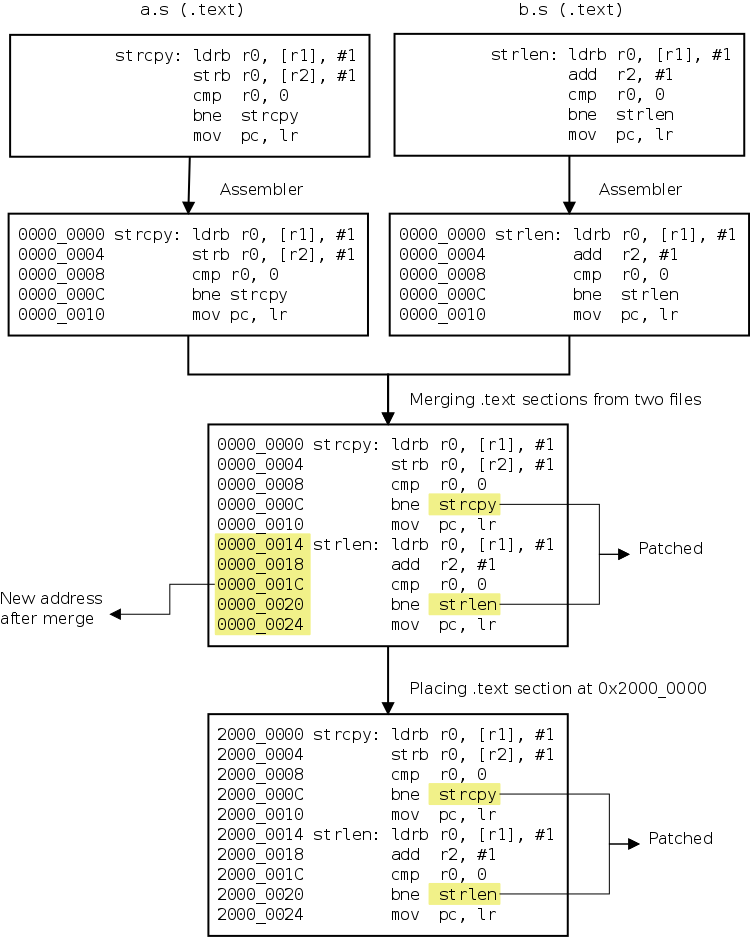
7.链接脚本文件
如前一节所述,段的合并和段的排布是由链接器完成的。编程人员可以通过一个链接脚本文件控制段如何合并以及它们在内存中的位置。下面是一个非常简单的链接脚本。
Listing 6. Basic linker script
SECTIONS { ❶
. = 0x00000000; ❷
.text : { ❸
abc.o (.text);
def.o (.text);
} ❹
}
❶ SECTIONS命令是最重要的链接器命令,它指定了如何合并这些段以及将它们放置在什么位置。
❷ 在SECTIONS命令之后的语句块,.(dot)表示位置计数器。位置总是初始化为0x00000000。可以通过给它赋一个新的值来修改它。将开始处的位置计数器赋值为0x00000000是多余的。
❸ ❹ 链接脚本的这个部分指定了,输入文件abc.o、def.o的.text段将被放置到输出文件的.text段。
通过使用通配符*而不是单独指定文件名,可以进一步简化和通用化链接器脚本。
Listing 7. Wildcard in linker scripts
SECTIONS {
. = 0x00000000;
.text : { * (.text); }
}
如何程序既包含.text段也包含.data段,.data段的合并和位置可以像下面这样指定。
Listing 8. Multiple sections in linker scripts
SECTIONS {
. = 0x00000000;
.text : { * (.text); }
. = 0x00000400;
.data : { * (.data); }
}
此处.text段被放置到地址0x00000000处,.data被放置到地址0x00000400处。注意,如果位置计数器未分配不同的值,则.text和.data段会被放置到相邻的存储位置。
7.1.链接脚本示例
为了演示链接器脚本的使用,我们将使用[listing-8-multiple-sections-in-linker-scripts](Listing 8. Multiple sections in linker scripts)中所示的链接器脚本来控制程序的.text和.data段的排布。为此,我们将使用稍微修改过的sum of array程序。代码如下所示。
.data
arr: .byte 10, 20, 25 @ Read-only array of bytes
eoa: @ Address of end of array + 1
.text
start:
ldr r0, =eoa @ r0 = &eoa
ldr r1, =arr @ r1 = &arr
mov r3, #0 @ r3 = 0
loop: ldrb r2, [r1], #1 @ r2 = *r1++
add r3, r2, r3 @ r3 += r2
cmp r1, r0 @ if (r1 != r2)
bne loop @ goto loop
stop: b stop
这里唯一的变化是数组现在位于.data部分。还要注意,不需要使用额外的分支指令跳过数据部分,因为链接器脚本将适当地放置.text段和.data段。因此,语句可以以任何方便的方式放置在程序中,而链接脚本将负责将这些段正确地放置在内存中。
当一个程序被链接时,链接脚本作为一个输入传给链接器,如下命令。
$ arm-none-eabi-as -o sum-data.o sum-data.s
$ arm-none-eabi-ld -T sum-data.lds -o sum-data.elf sum-data.o
选项-T sum-data.lds指定了sum-data.lds将作为链接脚本。转储符号表,将使您了解如何在内存中放置段。
$ arm-none-eabi-nm -n sum-data.elf
00000000 t start
0000000c t loop
0000001c t stop
00000400 d arr
00000403 d eoa
从符号表中可以明显看出·text段是从地址0x0开始放置的,.data段是从地址0x400开始放置的。
8.数据位于RAM中示例
现在我们知道了如何编写链接器脚本,我们将尝试编写一个程序,并将.data部分放在RAM中。
将add程序修改为从RAM加载两个值,将它们相加并将结果存储回RAM。两个值和结果存放在.data段。
Listing 9. Add Data in RAM
.data
val1: .4byte 10 @ First number
val2: .4byte 30 @ Second number
result: .4byte 0 @ 4 byte space for result
.text
.align
start:
ldr r0, =val1 @ r0 = &val1
ldr r1, =val2 @ r1 = &val2
ldr r2, [r0] @ r2 = *r0
ldr r3, [r1] @ r3 = *r1
add r4, r2, r3 @ r4 = r2 + r3
ldr r0, =result @ r0 = &result
str r4, [r0] @ *r0 = r4
stop: b stop
使用下面的链接脚本。
SECTIONS {
. = 0x00000000;
.text : { * (.text); }
. = 0xA0000000;
.data : { * (.data); }
}
elf文件的符号表转储如下所示。
$ arm-none-eabi-nm -n add-mem.elf
00000000 t start
0000001c t stop
a0000000 d val1
a0000001 d val2
a0000002 d result
链接脚本似乎已经解决了在RAM中放置.data段的问题。但是等等,解决方案还没有完成!
8.1.RAM是易失性的
RAM是易失性的存储介质,因此不可能在开机时直接在RAM中使数据。(要从非易失性的存储介质复制过来)
所有代码和数据都应该在开机前存储在Flash中。在启动时,启动代码应该将数据从Flash复制到RAM,然后继续执行程序。因此,程序的.data段有两个地址,Flash中的加载地址和RAM中的运行时地址。
Tip
在
ld的说法中,加载地址称为LMA(Load Memory Address),run-time地址称为VMA(Virtual Memory Address)。
为了让程序正常运行,需要做下面2个修改。
- 链接器需要同时指定
.data段的加载地址和运行地址。 - 一段用于将
.data段从Flash(加载地址)拷贝至RAM(运行地址)的代码。
8.2.指定加载地址
run-time地址应该用于确定标签的地址。在前面的链接脚本中,我们为.data段指定了运行地址,但是加载地址没有显式指定,而是默认为运行时地址。对于前面的示例,这是可以的,因为程序是直接从Flash执行的。但是,如果要在执行期间将数据放在RAM中,那么加载地址应该与Flash对应,而运行时地址应该与RAM对应。
可以使用AT关键字指定与运行地址不同的加载地址。修改后的链接器脚本如下所示。
SECTIONS {
. = 0x00000000;
.text : { * (.text); }
etext = .; ❶
. = 0xA0000000;
.data : AT (etext) { * (.data); } ❷
}
❶ 可以在SECTIONS命令中通过为符号赋值来动态创建符号。这里,etext被赋值为该位置的位置计数器的值。etext包含代码段之后Flash中的下一个空闲位置的地址。稍后将使用它来指定.data段在Flash中的位置。注意etext本身不会分配任何内存,它只是符号表中的一个条目。
❷ AT关键字指定.data段的加载地址。地址或符号(其值是有效地址)可以作为参数传递给AT。这里.data的加载地址被指定为Flash中代码段之后的位置。
8.3.拷贝.data至RAM
要拷贝.data至RAM,需要下面的信息。
- data在Flash中的位置(
flash_sdata)。 - data在RAM中的位置(
ram_sdata)。 .data段的大小(data_size)。
有了这些信息,可以使用以下代码片段将数据从Flash复制到RAM。
ldr r0, =flash_sdata
ldr r1, =ram_sdata
ldr r2, =data_size
copy:
ldrb r4, [r0], #1
strb r4, [r1], #1
subs r2, r2, #1
bne copy
可以稍微修改链接脚本以提供这些信息。
Listing 10. Linker Script with Section Copy Symbols
SECTIONS {
. = 0x00000000;
.text : {
* (.text);
}
flash_sdata = .; ❶
. = 0xA0000000;
ram_sdata = .; ❷
.data : AT (flash_sdata) {
* (.data);
};
ram_edata = .; ❸
data_size = ram_edata - ram_sdata; ❹
}
❶ Flash中,data开始于所有code之后。
❷ RAM中,data开始于RAM的基址。
❸❹ 获取数据的大小并不简单。数据大小根据RAM中数据开始和结束时的差值计算。在链接器脚本中允许使用简单的表达式。
从Flash复制数据到RAM的add程序如下所示。
Listing 11. Add Data in RAM (with copy)
.data
val1: .4byte 10 @ First number
val2: .4byte 30 @ Second number
result: .space 4 @ 1 byte space for result
.text
;; Copy data to RAM.
start:
ldr r0, =flash_sdata
ldr r1, =ram_sdata
ldr r2, =data_size
copy:
ldrb r4, [r0], #1
strb r4, [r1], #1
subs r2, r2, #1
bne copy
;; Add and store result.
ldr r0, =val1 @ r0 = &val1
ldr r1, =val2 @ r1 = &val2
ldr r2, [r0] @ r2 = *r0
ldr r3, [r1] @ r3 = *r1
add r4, r2, r3 @ r4 = r2 + r3
ldr r0, =result @ r0 = &result
str r4, [r0] @ *r0 = r4
stop: b stop
程序使用Listing 10 Linker Script with Section Copy Symbols中列出的链接脚本进行汇编和链接。程序在Qemu中执行和测试。
qemu-system-arm -M connex -pflash flash.bin -nographic -serial /dev/null
(qemu) xp /4dw 0xA0000000
a0000000: 10 30 40 0
Note在具有SDRAM的实际硬件中,不应该立即访问内存。在执行内存访问之前,必须对内存控制器进行初始化。我们的代码可以工作,因为模拟内存
不需要初始化内存控制器。

9.异常处理
到目前为止给出的示例有一个重大的错误。内存映射中的前8个words保留给异常向量。当异常发生时,PC指针被转移到这8个位置之一。异常及其异常向量地址如下表所示。
Note异常向量具体是几个要看硬件架构,异常向量表是和具体硬件相关的。
Table 1. Exception Vector Addresses
| Exception | Address |
|---|---|
| Reset | 0x00 |
| Undefined Instruction | 0x04 |
| Software Interrupt (SWI) | 0x08 |
| Prefetch Abort | 0x0C |
| Data Abort | 0x10 |
| Reserved, not used | 0x14 |
| IRQ | 0x18 |
| FIQ | 0x1C |
这些位置应该包含一个分支语句,该分支语句将跳转至对应的异常处理程序。在我们目前看到的示例中,我们没有在异常向量地址处插入分支指令。我们没有遇到任何问题是因为这些异常没有发生。通过将上述程序与以下汇编代码链接,可以修复所有上述程序。
.section "vectors"
reset: b start
undef: b undef
swi: b swi
pabt: b pabt
dabt: b dabt
nop
irq: b irq
fiq: b fiq
只有reset异常向量被定向到和它自己标签不同的地址start。所有其他异常向量都被定向到相同的标签地址。因此,如果发生除reset之外的任何异常,处理器将在相同的位置死循环。然后可以通过调试器(在我们的例子中是monitor接口)查看pc的值来识别异常。
为了确保这些指令位于异常向量地址,链接器脚本应该如下所示。
SECTIONS {
. = 0x00000000;
.text : {
* (vectors);
* (.text);
...
}
...
}
注意vectors段是如何放在其他代码之前的,以确保vectors段位于从0x0开始的地址。
译者注:
只有裸机程序才有加异常向量表的需求。在操作系统上跑的程序不用关心这些,它们由操作系统接管。
10.C语言启动代码
处理器刚复位时是不可能直接执行C代码的。因为与汇编语言不同,C程序需要满足一些基本的先决条件。本节将描述先决条件以及如何满足这些先决条件。
我们将以sum of array的C程序为例。在本节结束时,我们将能够执行必要的设置,将控制转移到C代码并执行它。
Listing 12. Sum of Array in C
static int arr[] = { 1, 10, 4, 5, 6, 7 };
static int sum;
static const int n = sizeof(arr) / sizeof(arr[0]);
int main()
{
int i;
for (i = 0; i < n; i++)
sum += arr[i];
}
在将执行逻辑转移到C代码之前,必须正确设置以下内容。
- 栈
- 全局变量
- 已初始化的
- 未初始化的
- 只读数据
10.1.栈
C语言使用栈来存储本地(自动)变量,传递参数,存储返回地址等。所以在将控制权交给C代码之前,栈必须正确设置。
栈在ARM架构中是非常灵活的,因为它完全由软件实现。不熟悉ARM架构的可以看看概述附录C.ARM的栈。
为了确保不同编译器生成的代码具被互操作性(例如链接器的输入目标文件可以是由不同的编译器生成的),ARM创建了ARM Architecture Procedure Call Standard (AAPCS)。用作栈指针的寄存器,栈增长的方向,AAPCS中都有阐述。依据AAPCS,寄存器R13用作栈指针。栈也被规定是满-递减的。
放置全局变量和堆栈的一种方法如下图所示。
Figure 5. Stack Placement
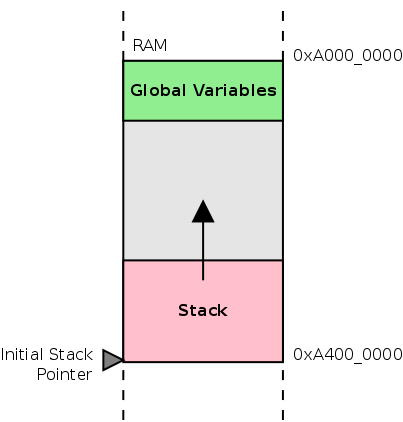
因此,在启动代码中所要做的就是将r13指向最高的RAM地址,这样堆栈就可以向下增长(指向较低的地址)。对于connex板,可以使用以下ARM指令来实现。
ldr sp, =0xA4000000
注意,汇编程序为r13寄存器提供了一个别名sp。
Note地址
0xA4000000并没有对应RAM,RAM结束地址是0xA3FFFFFF。但这没关系,因为堆栈是满递减的,在第一次push期间堆栈指针将先递减,变量值才被存储。
10.2.全局变量
编译C代码时,编译器将初始化的全局变量放在.data段。因此,与汇编一样,.data必须从Flash复制到RAM。
C语言保证所有未初始化的全局变量都将初始化为零。当编译C程序时,一个名为.bss的独立段用于放置未初始化变量的描述。由于这些变量的值都是以0开头的,所以它们不必存储在Flash中。在将控件转移到C代码之前,必须将这些变量对应的内存位置初始化为零。
10.3.只读数据
GCC将标记为const的全局变量放在一个名为.rodata的独立段中。.rodata还用于存储字符串常量。
由于.rodata段的内容不会被修改,所以可以放在Flash中。必须修改链接脚本以适应这种情况。
10.4.启动代码
现在我们知道了这些先决条件,就能创建链接脚本和启动代码。链接脚本Listing 10 Linker Script with Section Copy Symbols修改如下。
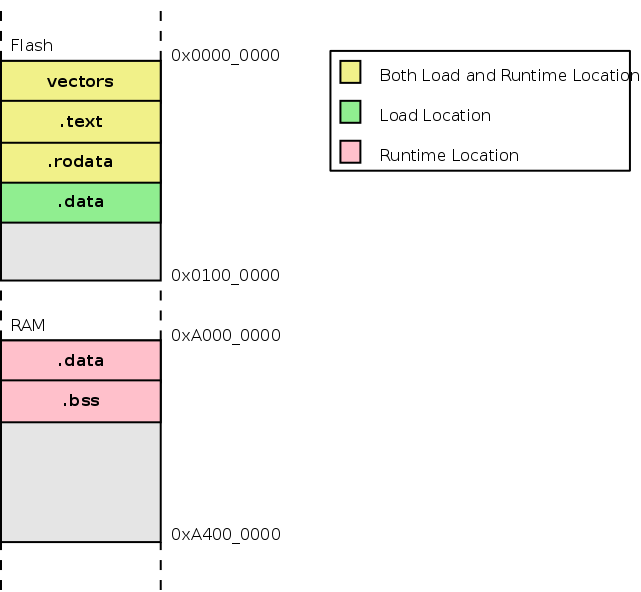
.bss段排布verctors段排布.rodata段排布
内存中,.bss段位于.data段之后。.bss段的起始和结束符号也都在链接脚本中创建。Flash中.rodata段紧跟着.text段放置 。下图展示了不同段的排布情况。
Figure 6. Section Placement
Listing 13. Linker Script for C code
SECTIONS {
. = 0x00000000;
.text : {
* (vectors);
* (.text);
}
.rodata : {
* (.rodata);
}
flash_sdata = .;
. = 0xA0000000;
ram_sdata = .;
.data : AT (flash_sdata) {
* (.data);
}
ram_edata = .;
data_size = ram_edata - ram_sdata;
sbss = .;
.bss : {
* (.bss);
}
ebss = .;
bss_size = ebss - sbss;
}
启动代码有如下几个部分。
- 异常向量表
- 从Flash拷贝
.data数据至RAM的代码 - 清零
.bss段的代码 - 设置栈指针的代码
- 跳转至main的代码
Listing 14. C Startup Assembly
.section "vectors"
reset: b start
undef: b undef
swi: b swi
pabt: b pabt
dabt: b dabt
nop
irq: b irq
fiq: b fiq
.text
start:
@@ Copy data to RAM.
ldr r0, =flash_sdata
ldr r1, =ram_sdata
ldr r2, =data_size
@@ Handle data_size == 0
cmp r2, #0
beq init_bss
copy:
ldrb r4, [r0], #1
strb r4, [r1], #1
subs r2, r2, #1
bne copy
init_bss:
@@ Initialize .bss
ldr r0, =sbss
ldr r1, =ebss
ldr r2, =bss_size
@@ Handle bss_size == 0
cmp r2, #0
beq init_stack
mov r4, #0
zero:
strb r4, [r0], #1
subs r2, r2, #1
bne zero
init_stack:
@@ Initialize the stack pointer
ldr sp, =0xA4000000
bl main
stop: b stop
要编译代码,不需要分别调用汇编器、编译器和链接器。gcc足够聪明,可以为我们一步完成。
如前所述,我们将编译并执行Listing 12, Sum of Array in C所示的C代码。
$ arm-none-eabi-gcc -nostdlib -o csum.elf -T csum.lds csum.c startup.s
-nostdlib选项指定不链接标准C库。当链接到C库时,需要额外注意一点。在11.使用C库会讨论。
符号表的转储可以更好地描述这些东西在内存中是如何放置的。
$ arm-none-eabi-nm -n csum.elf
00000000 t reset ❶
00000004 A bss_size
00000004 t undef
00000008 t swi
0000000c t pabt
00000010 t dabt
00000018 A data_size
00000018 t irq
0000001c t fiq
00000020 T main
00000090 t start ❷
000000a0 t copy
000000b0 t init_bss
000000c4 t zero
000000d0 t init_stack
000000d8 t stop
000000f4 r n ❸
000000f8 A flash_sdata
a0000000 d arr ❹
a0000000 A ram_sdata
a0000018 A ram_edata
a0000018 A sbss
a0000018 b sum ❺
a000001c A ebss
❶ reset,其余的异常向量从0x0开始放置。
❷ 汇编代码位于8个异常向量之后(8 * 4 = 32 = 0x20)。
❸ 只读数据n,放在Flash后的代码中。
❹ 已初始化的数据arr(一个由6个整数组成的数组)位于RAM0xA0000000的开头。
❺ 未初始化的数据sun放在已初始化的数据arr之后。(6 * 4 = 24 = 0x18)。
要执行程序,将程序转换为.bin格式,在Qemu中执行,并转储位于0xA0000018的sum变量。
$ arm-none-eabi-objcopy -O binary csum.elf csum.bin
$ dd if=csum.bin of=flash.bin bs=4096 conv=notrunc
$ qemu-system-arm -M connex -pflash flash.bin -nographic -serial /dev/null
(qemu) xp /6dw 0xa0000000
a0000000: 1 10 4 5
a0000010: 6 7
(qemu) xp /1dw 0xa0000018
a0000018: 33
11.使用C库
未完成
12.内联汇编
未完成
13.贡献
和其他开源项目一样,我们很乐意接受贡献。需要帮助的部分已经用FIXMEs标记。所有的贡献将被适当地记入贡献人员页面。此文档的源代码保存在位于https://github.com/bravegnu/gnu-eprog。要对项目做出代码贡献,可以在github上fork项目并发送pull请求。
14.Credits
14.1.People
The original tutorial was written by Vijay Kumar B., vijaykumar@bravegnu.org
Jim Huang, Jesus Vicenti, Goodwealth Chu, Jeffrey Antony, Jonathan Grant, David LeBlanc, reported typos and suggested fixes in the code and text.
14.2.Tools
The following great free software tools were used for the construction of the tutorial.
asciidoc for lightweight markup
xsltproc for HTML transformation
docbook-xsl for the stylesheets
highlight.js for syntax highlighting
dia for diagram creation
GoSquared Arrow Icons for the navigation icons
mercurial for version control
emacs …
附录
附录A.ARM编程人员模型
本节提供了一个简化的ARM编程人员模型。
寄存器档案。在ARM处理器中,任何时候都有16个通用寄存器可用。每个寄存器的大小为32位。寄存器称为Rn,其中n表示寄存器索引。所有指令对寄存器R0到R13一视同仁。任何可以在R0上执行的操作都可以在寄存器R1到R13上执行。但是R14和R15由处理器分配特殊的功能。R15是程序计数器,包含要获取的下一条指令的地址。R14是链接寄存器,用于在调用子例程时存储返回地址。
Tip尽管处理器未分配给R13特殊功能,但是按照惯例,操作系统用它作为栈指针,指向栈顶。
Current Program Status Register。当前程序状态寄存器(CPSR)是一个专用的32-bit寄存器,包含下列几个域。
- 条件标识
- 中断掩码
- 处理器模式
- 处理器状态
在本教程提供的示例中,只使用condition flags字段。因此这里只阐述条件标志。
条件标志表示在执行算术和逻辑操作时发生的各种条件。下表给出了各种条件标志及其含义。
Table A.1. Condition Flags
| 标识 | 含义 |
|---|---|
进借位标识C |
操作导致了进借位 |
溢出标识O |
操作导致溢出 |
零标识Z |
操作结果为0 |
负数标识N |
操作结果为负数 |
附录B.ARM指令集
ARM处理器有一个强大的指令集,但是这里只讨论理解本教程中的示例所需的子集。
ARM有一个加载、存储架构,这意味着所有算术和逻辑指令只接受寄存器操作数。它们不能直接对内存中的操作数进行操作。独立的指令加载和存储指令用于在寄存器和内存之间移动数据。
在本节中,将阐述以下这类指令
- 数据处理指令
- 分支指令
- 加载、存储指令
数据处理指令。最常见的数据处理指令列在下表中。
Table B.1. Data Processing Instructions
| 指令 | 操作 | 例子 |
|---|---|---|
| mov rd, n | rd = n | mov r7, r5 @ r7 = r5 |
| add rd, rn, n | rd = rn + n | add r0, r0, #1 @r0 = r0 + 1 |
| sub rd, rn, n | rd = rn - n | sub r0, r2, r1 @r0 = r2 + r1 |
| cmp rn, n | rn - n | cmp r1, r2 @r1 - r2 |
默认情况下,数据处理指令不更新条件标志。如果指令的后缀是s,则指令将更新条件标志。例如,下面的指令添加两个寄存器并更新条件标志。
adds r0, r1, r2
```https://www.adminiot.com.cn/
这个规则的一个例外是`cmp`指令。由于`cmp`指令的唯一目的是设置条件标志,所以它不需要`s`后缀来设置标志。
**分支指令**。分支指令导致处理器从不同的地址执行指令。有两条分支指令可用:`b`和`bl`。除了分支,`bl`指令还将返回地址存储在`lr`寄存器中,因此可以用于子例程调用。指令语法如下所示。
```asm
b label @ pc = label
bl label @ pc = label, lr = addr of next instruction
要从子例程返回,可以使用mov指令,如下所示。
mov pc, lr
条件执行。大多数其他指令集允许根据条件标志的状态条件执行分支指令。在ARM中,几乎所有指令都可以有条件地执行。
如果对应的条件为真,则执行该指令。如果条件为假,则将该指令转换为nop。条件是通过在指令后面附加条件代码助记符来指定的。
| 条件码 | 助记符 | 条件 | 检测的条件位 |
|---|---|---|---|
| 0000 | EQ | 相等/等于零 | Z=1 |
| 0001 | NE | 不等 | Z=0 |
| 0010 | CS/HS | 进位/无符号数大于等于 | C=1 |
| 0011 | CC/LO | 无进位/无符号数小于 | C=0 |
| 0100 | MI | 负数 | N=1 |
| 0101 | PL | 正数或零 | N=0 |
| 0110 | VS | 溢出 | V=1 |
| 0111 | VC | 未溢出 | V=0 |
| 1000 | HI | 无符号数大于 | C=1 & Z=0 |
| 1001 | LS | 无符号数小于等于 | C=0 or Z=1 |
| 1010 | GE | 有符号数大于等于 | N=V |
| 1011 | LT | 有符号数小于 | N!=V |
| 1100 | GT | 有符号数大于 | Z=0 & N=V |
| 1101 | LE | 有符号数小于等于 | Z=1 or N!=V |
| 1110 | AL | 总执行 | 任何状态 |
| 1111 | NV | 从不(不要使用) | 无 |
在下面的示例中,仅当进借位置位时,指令才将r1移动到r0。
MOVCS r0, r1
加载存储指令。加载、存储指令可用于在寄存器和内存之间移动单个数据项。指令语法如下所示。
ldr rd, addressing ; rd = mem32[addr]
str rd, addressing ; mem32[addr] = rd
ldrb rd, addressing ; rd = mem8[addr]
strb rd, addressing ; mem8[addr] = rd
addressing是由两部分组成的
- 基址寄存器
- 偏移
基址寄存器可以是任何通用寄存器。偏移寄存器和基址寄存器可以以三种不同的方式交互。
- 偏移
- 从基址寄存器中添加或减去偏移量以形成地址。
ldr示例:ldr rd, [rm, offset]。
- 前变址
- 从基址寄存器中添加或减去偏移量以形成地址,寻址完成后将地址写回基址寄存器。
ldr示例:ldr rd, [rm, offset]!
- 后变址
- 基址寄存器包含要访问的地址,寻址完成后将基址址中添加或减去偏移量并存储在基寄存器中。
ldr示例:ldr rd, [rm], offset
偏移量可以采用以下格式
- 立即数
- 偏移量是一个无符号数,它可以与基址寄存器的值相加或相减。常用于访问栈中的结构成员、局部变量。立即数以
#开头。
- 寄存器
- 偏移量是通用寄存器中的一个无符号值,它可以与基址寄存器的值相加或相减。常用于访问数组元素。
一些示例
ldr r1, [r0] ; same as ldr r1, [r0, #0], r1 = mem32[r0]
ldr r8, [r3, #4] ; r8 = mem32[r3 + 4]
ldr r12, [r13, #-4] ; r12 = mem32[r13 - 4]
strb r10, [r7, -r4] ; mem8[r7 - r4] = r10
strb r7, [r6, #-1]! ; mem8[r6 - 1] = r7, r6 = r6 - 1
str r2, [r5], #8 ; mem32[r5] = r2, r5 = r5 + 8
附录C.ARM的栈
堆栈在ARM体系结构中非常灵活,因为完全由软件实现。
栈指令。ARM指令集不包含任何特定的栈指令,比如push和pop。指令集也不强制使用堆栈。push和pop操作由内存访问指令执行,具有自动增量寻址模式。
栈指针。栈指针是指向栈顶部的寄存器。在ARM处理器中,没有专用的栈指针寄存器,任何通用寄存器都可以用作堆栈指针。
栈类型。由于栈是由软件来实现的,不同的实现选择会产生不同类型的栈。根据栈的增长方式,有两种类型的栈。
- 递增栈
在push操作时栈指针增加,例如栈向更高的地址增长。
- 递减栈
在push操作时栈指针递减,例如栈向更低的地址增长。
根据栈指针指向的内容,又可以将栈分为两类。
- 空栈
栈指针指向的位置用于存储下一个存储对象。push操作先在当前位置存储这个值,然后栈指针自增。
- 满栈
栈指针指向的位置是最后一个存储对象。push操作先让栈指针自增,然后在新的位置存储这个值。
一共可以实现四种不同类型的栈——满递增、满递减、空递增和空递减。这四种类型的栈都可以使用寄存器加载存储指令来实现。