在RCNN,Fast RCNN之后,Ross B. Girshick在2016年提出Faster RCNN,将特征提取(feature extraction),proposal提取,目标定位location,目标分类classification整合到了一个网络中,性能大幅提升。作为Two-stage的代表,相比于yolo,ssd等one-stage检测方法,Faster RCNN的检测精度更高,速度相对较慢。
为了加深对Faster RCNN的理解,还是从网络结构,正负样本分配,loss函数三个方面来记录下自己的学习过程。原版Faster RCNN的backbone为VGG16, 而实际工作中,我主要使用Resnet50为backbone的Faster RCNN,这里以Resnet50_Faster_RCNN为例进行说明
1. Resnet50_Faster_RCNN 网络结构
下面两张图中,第一张是Resnet50_Faster_RCNN的网络结构流程图,第二张是详细展开后的网络卷积模块。可以发现其网络结构中主要包括Resnet50 Conv layers,RPN(Region Proposal Network), ROIPooling/ROIAlign, class/box Predictors四个模块:
1.Resnet50 Conv layers: 包括了Head, Layer1, Layer2, Layer3, Layer4,主要负责特征提取;(Head, Layer1, Layer2, Layer3为最开始的特征提取,layer4是在确定正负样本后第二次的特征提取) 2.RPN:主要负责proposal的提取,给出每个proposal的属于正负样本的分数,并修正其位置; 3.ROIPooling/ROIAlign:根据RPN给出的Proposal,从Feature map中得到每个proposal对应的局部feature,并进行汇总后输入下一层网络 4.class/box Predictors: 预测proposal所属类别(class), 以及其位置偏移量(box regression),从而修正box
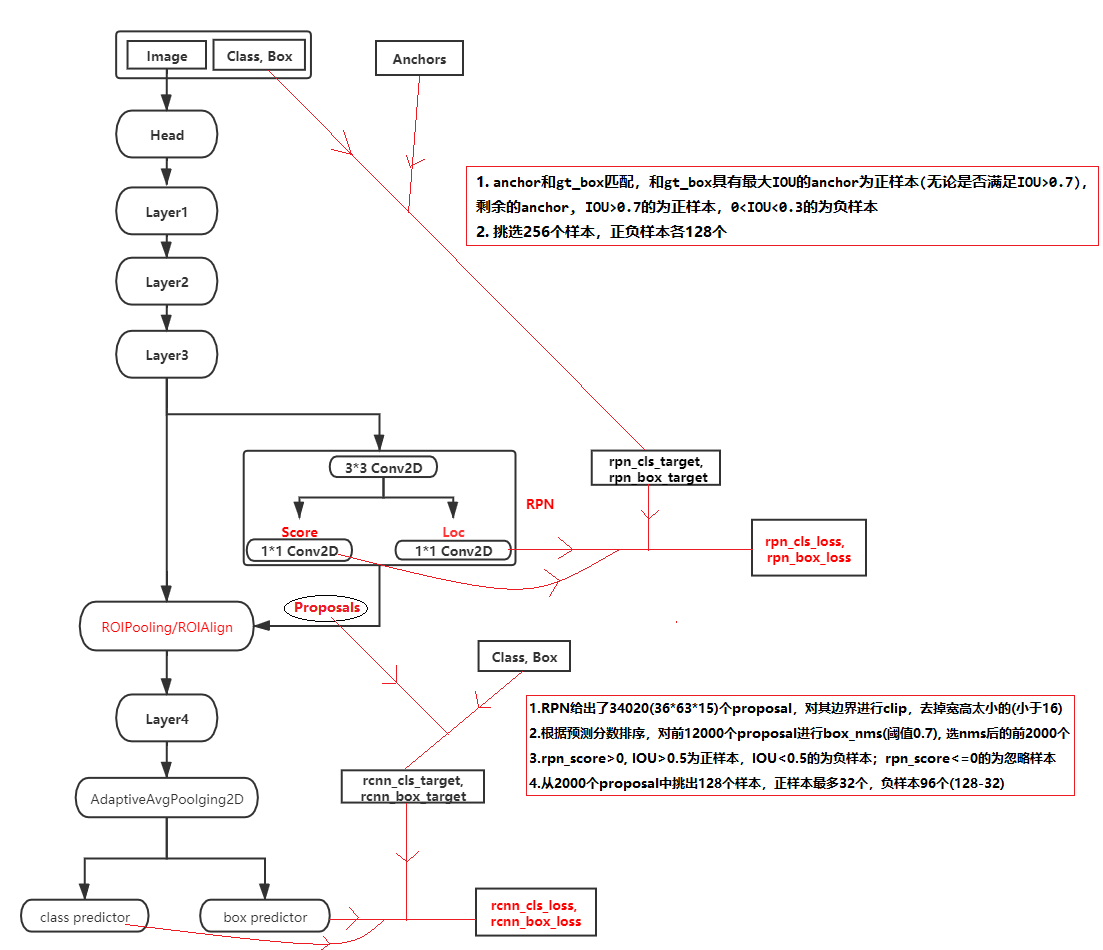
图1 resnet50_faster_rcnn流程结构图

图2 resnet50_faster_rcnn网络结构图
网络结构中比较难理解的主要是RPN和ROIPooling/ROIAlign两部分,需要详细了解下。
RPN网络流程
1. 上述图中Layer3得到的feature为B*1024*36*63,送入RPN网络首先卷积得到B*1024*36*63,然后score分支预测proposal的概率,尺寸为B*15*36*63(每个位置有15个anchor),loc预测proposal的偏移量,尺寸为B*60*36*63;
2. 根据B*15*36*63的分数置信度,B*60*36*63的位置偏移量,利用已经设置好的34020(36*63*15)个anchor和匹配规则,选择128个proposal(32个正样本,96个负样本)
ROIPooling/ROIAlign流程
(ROIPooling和ROIAlign详细解释参见:https://zhuanlan.zhihu.com/p/73138740)
1.上述图中Layer3得到的feature为B*1024*36*63,RPN网络得到proposal为B*128*4,对于每一个proposal根据其坐标位置,在feature中找到其对应的局部特征sub_feature(例如1024*20*30),对这个局部特征进行AvgPooling得到1024*14*14。共有B*128个proposal,因此所有proposal处理完成得到尺寸为[B*128, 1024, 14, 14]
2. 正负样本分配
faster_rcnn网络结构中有两次正负样本分配,一是从设置好的anchor中挑选样本给RPN网络学习,从而使RPN网络预测出精准的proposal;二是从RPN预测出的proposal挑选样本给RCNN网络(layer4+predictor部分)学习,使RCNN网络预测proposal的类别,并修正其坐标位置
2.1 faster_rcnn网络anchor设置
faster_rcnn论文采用9个anchor(三个尺寸,三个比例),这里采用了15个anchor(5个尺寸,三个比例),增加对小目标的检测。以网络layer3输出feature为基础,其anchor设置的示意图如下:
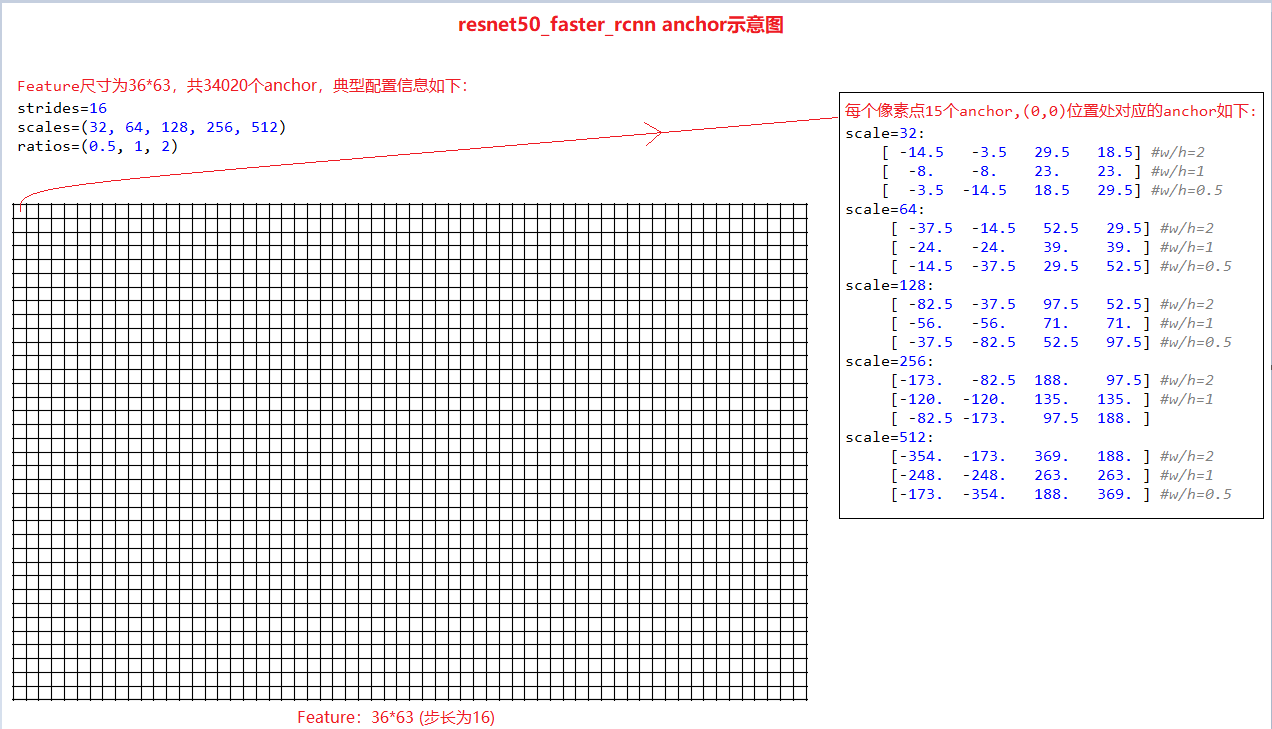
产生anchor的简单示例代码如下:


import numpy as np strides=16 # scales=(8, 16, 32) scales=(2,4,8,16,32) ratios=(0.5, 1, 2) alloc_size=(36, 63) scales = [i*strides for i in scales] print(scales) center_point = ((strides-1)/2, (strides-1)/2) anchors = [] for scale in scales: for ratio in ratios: area = scale*scale ws = np.round(np.sqrt(area/ratio)) hs = np.round(np.sqrt(area*ratio)) anchor = [center_point[0]-(ws-1)/2, center_point[1]-(hs-1)/2, center_point[0]+(ws-1)/2, center_point[1]+(hs-1)/2] anchors.append(anchor) print(np.array(anchors))
2.2 RPN网络正负样本分配
RPN网络的目的是给出精确的proposal,其学习样本来自于设置的anchor。如上一步共设置了34020个anchor,根据这些anchor和gt_box的IOU,挑选出256个anchor作为样本给RPN网络学习,anchor挑选流程如下:
1. 去掉anchor中坐标超出图片边界的(图片为562*1000) 2. 计算所有anchor和gt_box的IOU,和gt_box具有最大IOU的anchor为正样本(无论是否满足IOU>0.7),剩余的anchor, IOU>0.7的为正样本,0<IOU<0.3的为负样本 3. 挑选出256个样本,正负样本各128个。(若正样本不够128个时,有多少取多少,若正本超过128个,随机选取128个正样本,多余的标注未忽略样本;负样本一般会多余128个,随机选取128个负样本,多余的标注未忽略样本) (最后会出现两种情况,一是正负样本各128个,总共256个样本;二是正样本少于128个(如50个),负样本128个,总样本少于256个)
2.3 RCNN网络正负样本分配
同样的,对于layer3 feture(36*63), 每个像素点预测15个proposl,因此RPN网络会预测出34020个proposal,需要从这34020个proposal中选出128个proposal给RCNN网络的(layer4+predictor)模块来学习。proposal挑选流程如下:
1.共34020(36*63*15)个proposal,对proposal边界进行clip,去掉宽高太小(小于16)的proposal; 2.根据预测分数排序,对前12000个proposal进行box_nms(阈值为0.7),nms后选择排序最前面的2000个proposal 3.rpn_score>0, IOU>0.5的proposal为正样本,IOU<0.5的为负样本;rpn_score<=0的为忽略样本 4.从2000个proposal中挑出128个样本,正样本最多32个,负样本96个(128-32)
3. Loss函数理解
faster_rcnn的损失包括RPN loss和RCNN loss两部分,都包括置信度和位置偏移量损失;RPN Loss的置信度采用二分类交叉熵损失SigmoidBinaryCrossEntropyLoss,位置偏移量采用SmoothL1;RCNN Loss的置信度采用多分类交叉熵损失SoftmaxCrossEntrophyLoss, 位置偏移量采用SmoothL1。faster_rcnn的训练策略上,原始论文中采用先训练RPN网络(只对RPN Loss进行backward),然后再训练RCNN网络(只对RCNN Loss进行backward),现在一般都同时训练RPN和RCNN,即将RPN Loss和RCNN Loss汇总后一起backward,下面是摘录的部分源码,便于理解loss的计算和backwar
#self.rpn_cls_loss =mx.gluon.loss.SigmoidBinaryCrossEntropyLoss(from_sigmoid=False) #self.rpn_box_loss = mx.gluon.loss.HuberLoss(rho=config.rpn_smoothl1_rho) # == smoothl1 #self.rcnn_cls_loss = mx.gluon.loss.SoftmaxCrossEntropyLoss() #self.rcnn_box_loss = mx.gluon.loss.HuberLoss(rho=config.rcnn_smoothl1_rho) # == smoothl1 with autograd.record(): gt_label = label[:, :, 4:5] gt_box = label[:, :, :4] cls_pred, box_pred, _, _, _Z, rpn_score, rpn_box, _, cls_targets, box_targets, box_masks, _ = self.net(data, gt_box, gt_label) # losses of rpn rpn_score = rpn_score.squeeze(axis=-1) num_rpn_pos = (rpn_cls_targets >= 0).sum() rpn_loss1 = self.rpn_cls_loss(rpn_score, rpn_cls_targets, rpn_cls_targets >= 0) * rpn_cls_targets.size / num_rpn_pos #rpn_cls_targets中1表示正样本,0负样本,-1忽略样本 rpn_loss2 = self.rpn_box_loss(rpn_box, rpn_box_targets, rpn_box_masks) * rpn_box.size / num_rpn_pos #rpn_box_masks中1表示正样本,0表示负样本和忽略样本 # rpn overall loss, use sum rather than average rpn_loss = rpn_loss1 + rpn_loss2 # losses of rcnn num_rcnn_pos = (cls_targets >= 0).sum() rcnn_loss1 = self.rcnn_cls_loss( cls_pred, cls_targets, cls_targets.expand_dims(-1) >= 0) * cls_targets.size/num_rcnn_pos #cls_targets中1表示正样本,0负样本,-1忽略样本 rcnn_loss2 = self.rcnn_box_loss(box_pred, box_targets, box_masks) * box_pred.size/num_rcnn_pos #box_masks中1表示正样本,0表示负样本和忽略样本 rcnn_loss = rcnn_loss1 + rcnn_loss2 # overall losses total_loss = rpn_loss.sum() * self.mix_ratio + rcnn_loss.sum() * self.mix_ratio total_loss.backward()
参考:https://zhuanlan.zhihu.com/p/273587749?utm_source=wechat_session
https://zhuanlan.zhihu.com/p/82185598?utm_source=wechat_session
https://zhuanlan.zhihu.com/p/123962549
https://zhuanlan.zhihu.com/p/31426458