前言
鉴于最近在做观点挖掘的相关工作,观点的数据源是网络评论数据,于是第一个想到的就是新闻观点数据,一个热门的新闻可能一晚上就会有上万条评论,所以如何分析并利用好这些评论信息,将会是一件非常有意思的事情,观点挖掘是我研究的目的,当然要想很好解决这个问题,所以我自然要解决数据源的问题,于是乎,我就想到了去爬取腾讯新闻的评论数据。下面我会介绍一下这个过程,这个过程还是非常有意思的哦。
为什么爬的是腾讯新闻的数据
我从网上查阅了许多爬取新闻数据的相关技术帖,发现除了腾讯的之外,还有新浪,网易的比较多,但是他们的请求链接都不是那么好破解,腾讯新闻的稍稍简单一点,而且初步分析了一下,可以利用技术的手段去构造请求,从而获取评论数据。先来看一个例子链接,这个也是我从网上找的。
http://coral.qq.com/article/1004703995/comment?commentid=0&reqnum=20&tag=&callback=mainComment&_=1389623278900
链接附带的参数还是有点多的,下面给出参数的各个意思:
http://coral.qq.com/article/评论页ID(即cmt_id)/comment?commentid=起始ID&reqnum=显示数目&tag=&callback=mainComment&_=时间戳+3位随机整数
最后一位随机值其实没什么用处了。然后点击链接,我们截取其中的一条评论数据,获取到的数据是这样的:
mainComment({"errCode":0,"data":{"targetid":1004703995,"display":1,"total":14000,"reqnum":20,"retnum":20,"maxid":"5990116449200978034","first":"5990116449200978034","last":"5840477226068943893","hasnext":true,"commentid":[{"id":"5990116449200978034","rootid":"0","targetid":1004703995,"parent":"0","timeDifference":"04u670804u65e5 21:44:12","time":1428155052,"content":"u65e9u8be5u7528u56fdu4ea7u7684u8f66u4e86uff0cu7279u522bu662fu7ea2u65d7u8001u724cu5b50uff0cu6240u6709u7684u516cu8f66u5e94u8be5u90fdu7528u56fdu4ea7u7684uff0cu4f60u770bu97e9u56fdu4ebau6240u6709u7528u7684u90fdu4ee5u56fdu4ea7u4e3au4e3b","title":"","up":"0","rep":"0","type":"1","hotscale":"0","checktype":"1","checkstatus":"1","isdeleted":"0","tagself":"","taghost":"","source":"2","location":"","address":"","rank":"-1","custom":"","extend":{"at":0,"ut":0},"orireplynum":"0","richtype":0,"userid":"171498810","poke":0,"abstract":"","replyuser":"","replyuserid":0,"replyhwvip":0,"replyhwlevel":0,"userinfo":{"userid":"171498810","uidex":"eca292c6a6414f6e1fcb977697686602af","nick":"HLXu6d77u5170u8f69","head":"http://q1.qlogo.cn/g?b=qq&k=IFD4IB50ib9kwDdYwdo4Rxw&s=40&t=1431792000","gender":1,"viptype":"0","mediaid":0,"region":"u4e2du56fd:u5c71u4e1c:u4e1cu8425","thirdlogin":0,"hwvip":0,"hwlevel":0,"identity":"","wbuserinfo":{"name":"zhangzhongliang4372","nick":"u5f20u5fe0u826f","url":"","vip":0,"ep":0,"brief":"","identification":"","intro":"","liveaddr":{"country":"1","province":"37","city":"5","area":""},"gender":1,"level":0,"classify":""},"remark":"","fnd":0}},
一个超级庞大的json字符串,而且评论数据content里面的中文被编成Unicode的格式了,无法直接查看,在评论数据中,有时还会有用户的许多信息。这样不直观,可以在Google上去查看,但是得需要安装jsonView插件,会有一定的结构呈现:

接下来我们要好好的分析一下这里面的数据属性结构了。
腾讯新闻评论数据构成
我们关注的属性值不会很多,首先这些数据是被mainComment这个包着的,所以在解析之前需要把这个得剥离掉。
1、errCode:首先有errCode,一看就知道是响应回复值,用来判断请求是否成功和失败了。
2.、targetId:然后data才是我们所关心的,首先是一个targetId,暂且可先理解为具体新闻的id,但是事实上不是,这个在后面会做解释
3、total:指的是的此条新闻的所有评论数据的总条数。
4、reqnum:此次请求评论数据的条数。这里需要小小提醒一下,每次请求数据的上限条数50条,如果某次请求超出这个值,还是会返回50条。
5、retnum:此次请求返回的评论数,如果没有到评论数据的末尾,一般请求值与返回值是相等的。
6、maxid:指的是此次返回的评论数据中评论id最大的值。
7、firsr:指的是返回的评论中的首条评论id。
8、last:指的是返回的评论数据中的末尾条的评论id。
然后这个时候可以在介绍一下刚刚提到的问题,targetid其实不是真实的新闻页id,其实是一个映射的关系吧,一个新闻页会对应一个评论id,这个id其实是一个类似于评论组id的概念,然后在这个id下面,每条评论数据都有自己的id值,所以才会有first,last这些值的存在。
下面再简单一看下评论数据的属性信息了
1、id:针对自己的评论id,这个id是唯一的,至于具体怎么生出,这个我也不清楚。
2、targetid:同样有定义targetid的定义,表明所属于哪条新闻的评论数据。
3、time:评论数据的发表时间,以时间戳的方式存在。
4、content:这个就是我们最最关注的评论数据了。
如何爬取新闻评论数据
在了解了评论数据的结构数据后,我们当然想要的是如何去获取其中的数据,请求模板链接已经在上面给出了,再次在下面给出,
http://coral.qq.com/article/评论页ID(即cmt_id)/comment?commentid=起始ID&reqnum=显示数目&tag=&callback=mainComment&_=时间戳+3位随机整数
需要填入的参数有,reqnum,每次请求数,评论页id,其实id,时间戳那个你可以固定写死都没问题。OK,下面我们一个个解决。
1、评论页id,即cmt_id,这个没有什么API,只能自己去匹配,爬取,常用的办法就是解析新闻页的HTML代码,利用写好的正则表达式去匹配。cmt_id在详情页的代码中的展示为
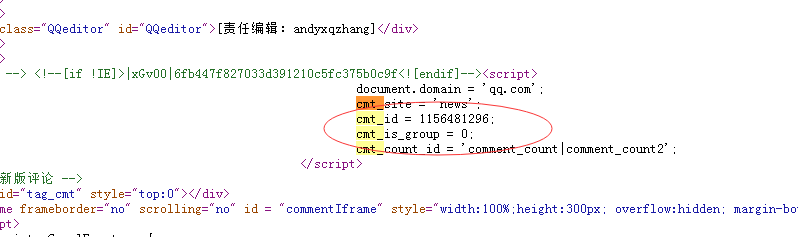
所以可以写一个cmt_id = "(,*)";的匹配规则去匹配。在我后面的代码实现中都会出现。匹配到cmt_id后,就第一个参数搞定。
2、起始id,指的是从哪个id开始的评论数据,因为每次获取的都是一批数据,要知道起始位置才能获取相对应的数据,开始时0,表明取得是最前面的几十条数据,如果想要接下来取的话,需要把这批数据中最后一个评论id,加入到新的请求中,才能往后取,就是刚刚的last值的定义。
3‘、reqnum请求数据这个很简单,不超过50都没问题。
以上具体的过程会在我后面的程序中有所体现,现在不理解没有关系。
爬取示例
我选取了一则最近的新闻,页面如下
标题为俄罗斯红场阅兵....ok,标题其实我们也可以爬到的。查看一下目前最新的一部分评论,用于后面做对比:
然后我们爬取一下数据,输出到本地的一个文件中,格式为发表时间戳+评论内容。
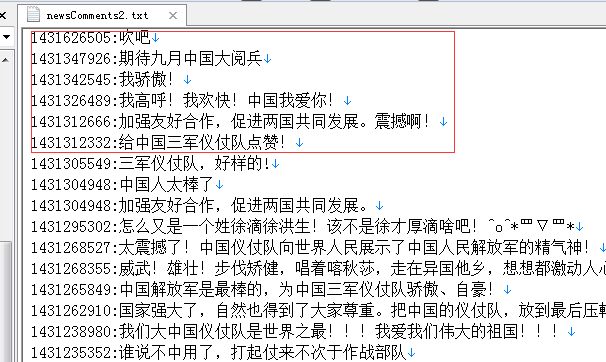
然后与网上的数据比对一下
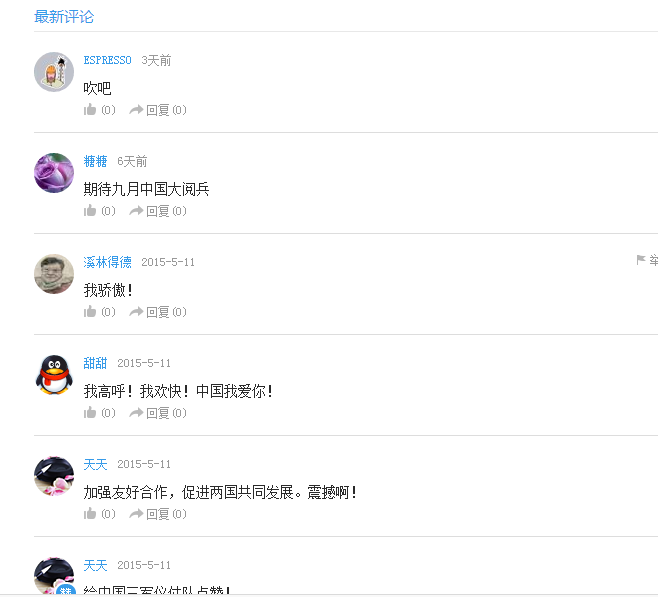
数据完全吻合,由此评论过程顺利完成。而且能够连续的爬取到数据。下面看看关键的代码实现
爬取算法代码实现
只需要输入新闻页的链接即可。在算法中会有2次的http请求,第一次获取cmt_id评论id,第二次才是评论数据的爬取。废话不多说,贴代码,这里小小提醒一下,为了避免太频繁的爬取请求,我在每次爬取完毕之后进行随机几秒的时间睡眠。在解析json数据时,需要有Gson的依赖,在我的github上完整的代码和jar包,上面还有如何使用,地址同样贴上,点击我的腾讯新闻评论数据爬取项目。
爬取工具封装类QQNewCrawler.java:
package TextMining.crawler;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.net.URL;
import java.net.URLConnection;
import java.text.MessageFormat;
import java.util.ArrayList;
import java.util.Random;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import TextMining.crawler.entity.Comment;
import TextMining.crawler.entity.Data;
import TextMining.crawler.entity.DataContainer;
import com.google.gson.Gson;
/**
* 腾讯新闻爬虫工具类
*
* @author lyq
*
*/
public class QQNewsCrawler {
// 腾讯新闻评论链接url的格式
public static final String NEWS_COMMENTS_URL_FORMAT = "http://coral.qq.com/article/{0}/comment?commentid={1}&reqnum={2}&tag=&callback=mainComment&_=1389623278900";
// 腾讯新闻详情页的链接
private String newsUrl;
//爬取到的新闻标题
private String newsTitle;
//评论数据输出路径
private String outputPath;
// 需要爬取的评论数总量
private int totalCommentcount;
// 每次请求的评论数,一次上限50条评论
private int reqCommentNum;
// 评论列表
private ArrayList<Comment> commentLists;
public QQNewsCrawler(String newUrl, int totalCommentcount, int reqCommentNum, String outputPath) {
this.newsUrl = newUrl;
this.totalCommentcount = totalCommentcount;
this.outputPath = outputPath;
if (reqCommentNum > 50) {
// 每次请求最多只能50条
reqCommentNum = 50;
}
this.reqCommentNum = reqCommentNum;
}
/**
* 获取评论内容数据
* @return
*/
public ArrayList<Comment> getCommentLists() {
return commentLists;
}
/**
* 获取新闻标题
* @return
*/
public String getNewsTitle(){
return this.newsTitle;
}
/**
* 从新闻详情页中爬取新闻标题和评论ID
*
* @return
*/
public String[] crawlCmtIdAndTitle() {
String[] array;
String[] tempArray;
// 页面HTML字符
String htmlStr;
String cmtId;
String newsTitle;
String filePath = "C:\Users\lyq\Desktop\icon\input2.txt";
Pattern p;
Matcher m;
cmtId = null;
newsTitle = null;
array = new String[2];
htmlStr = sendGet(newsUrl);
// htmlStr = readDataFile(filePath);
p = Pattern.compile("cmt_id = (.*);");
m = p.matcher(htmlStr);
while (m.find()) {
cmtId = m.group();
System.out.println(cmtId);
break;
}
p = Pattern.compile("<title>(.*)</title>");
m = p.matcher(htmlStr);
while (m.find()) {
newsTitle = m.group();
System.out.println(newsTitle);
break;
}
// 对匹配到的评论id字符做解析
if (cmtId != null && !cmtId.equals("")) {
tempArray = cmtId.split(";");
cmtId = tempArray[0];
tempArray = cmtId.split("=");
cmtId = tempArray[1].trim();
System.out.println(cmtId);
}
int pos1;
int pos2;
// 对匹配到的新闻标题做解析
if (newsTitle != null && !newsTitle.equals("")) {
pos1 = newsTitle.indexOf(">");
pos2 = newsTitle.lastIndexOf("<");
newsTitle = newsTitle.substring(pos1 + 1, pos2);
System.out.println(newsTitle);
}
array[0] = cmtId;
array[1] = newsTitle;
this.newsTitle = newsTitle;
return array;
}
/**
* 根据新闻评论ID爬取腾讯新闻评论数据
*
* @throws
*/
public void crawlNewsComments() {
String resultCommentStr;
String requestUrl;
String cmtId;
String[] info;
String startCommentId;
int index1;
int index2;
// 当前获取到评论条数
int currentCommentNum;
int sleepTime;
Random random;
startCommentId = "";
currentCommentNum = 0;
random = new Random();
commentLists = new ArrayList<>();
info = crawlCmtIdAndTitle();
cmtId = info[0];
// cmtId = "1004703995";
// 当请求总量达到要求的量时,跳出循环
while (currentCommentNum < totalCommentcount) {
requestUrl = MessageFormat.format(NEWS_COMMENTS_URL_FORMAT, cmtId,
startCommentId, reqCommentNum);
resultCommentStr = sendGet(requestUrl);
// 截取出json格式的评论数据
index1 = resultCommentStr.indexOf("{");
index2 = resultCommentStr.lastIndexOf("}");
resultCommentStr = resultCommentStr.substring(index1, index2 + 1);
System.out.println(resultCommentStr);
// 以上次最后一条评论的id为起始ID,继续爬取数据
startCommentId = parseJSONData(resultCommentStr);
// 如果解析出现异常,则立即退出
if (startCommentId == null) {
break;
}
try {
// 随机睡眠1到5秒
sleepTime = random.nextInt(5) + 1;
Thread.sleep(1000 * sleepTime);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
currentCommentNum += reqCommentNum;
}
// 最后将本次爬取的所有评论写入到文件中
writeStringToFile(commentLists, outputPath);
}
/**
* 解析评论数据的json格式字符串
*
* @param dataStr
* json数据
* @return 返回此次获取的最后一条评论的id
*/
private String parseJSONData(String dataStr) {
String lastId;
Gson gson = new Gson();
DataContainer dataContainer;
Data data;
ArrayList<Comment> cList;
dataContainer = gson.fromJson(dataStr, DataContainer.class);
// 如果获取数据异常,则返回控制
if (dataContainer == null || dataContainer.getErrCode() != 0) {
return null;
}
data = dataContainer.getData();
//一旦发现已经没有数据了,则返回
if (data == null) {
return null;
}
cList = data.getCommentid();
if(cList == null || cList.size() == 0){
return null;
}
commentLists.addAll(cList);
lastId = dataContainer.getData().getLast();
return lastId;
}
/**
* 向指定URL发送GET方法的请求
*
* @param url
* 发送请求的URL
* @return URL 所代表远程资源的响应结果
*/
private String sendGet(String requestUrl) {
String result = "";
BufferedReader in = null;
try {
URL realUrl = new URL(requestUrl);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
// 设置通用的请求属性
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际的连接
connection.connect();
// 定义 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
/**
* 从文件中读取数据
*/
private String readDataFile(String filePath) {
File file = new File(filePath);
String resultStr = "";
try {
BufferedReader in = new BufferedReader(new FileReader(file));
String str;
while ((str = in.readLine()) != null) {
resultStr = resultStr + str;
}
in.close();
} catch (IOException e) {
e.getStackTrace();
}
return resultStr;
}
/**
* 写评论到目标文件中
*
* @param resultStr
*/
public void writeStringToFile(ArrayList<Comment> commentList,
String desFilePath) {
File file;
PrintStream ps;
try {
file = new File(desFilePath);
ps = new PrintStream(new FileOutputStream(file));
for (Comment c : commentList) {
ps.println(c.getTime() + ":" + c.getContent());// 往文件里写入字符串
}
ps.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
Comment.java:
package TextMining.crawler.entity;
/**
* 具体的单条评论类
*
* @author lyq
*
*/
public class Comment {
// 代表的是此评论的ID
private String id;
// 评论对应的新闻ID
private String targetid;
// 评论的时间
private long time;
// 评论的具体内容
private String content;
// 评论被顶的次数
private String up;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getTargetid() {
return targetid;
}
public void setTargetid(String targetid) {
this.targetid = targetid;
}
public long getTime() {
return time;
}
public void setTime(long time) {
this.time = time;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getUp() {
return up;
}
public void setUp(String up) {
this.up = up;
}
}
package TextMining.crawler.entity;
import java.util.ArrayList;
/**
* 总评论实体
*
* @author lyq
*
*/
public class Data {
// 对应的新闻ID
private String targetid;
// 此新闻的评论总数
private int total;
// 当前获取数据评论中的首条评论子id
private String first;
// 当前获取数据评论中的末尾评论子id
private String last;
// 判断在此数据后面还有没有评论数据
private boolean hasnext;
// 具体子评论列表
private ArrayList<Comment> commentid;
public String getTargetid() {
return targetid;
}
public void setTargetid(String targetid) {
this.targetid = targetid;
}
public int getTotal() {
return total;
}
public void setTotal(int total) {
this.total = total;
}
public String getFirst() {
return first;
}
public void setFirst(String first) {
this.first = first;
}
public String getLast() {
return last;
}
public void setLast(String last) {
this.last = last;
}
public boolean isHasnext() {
return hasnext;
}
public void setHasnext(boolean hasnext) {
this.hasnext = hasnext;
}
public ArrayList<Comment> getCommentid() {
return commentid;
}
public void setCommentid(ArrayList<Comment> commentid) {
this.commentid = commentid;
}
}
package TextMining.crawler.entity;
/**
* 数据外层包装类
*
* @author lyq
*
*/
public class DataContainer {
// 请求回应码
private int errCode;
// 主题数据类
private Data data;
public Data getData() {
return data;
}
public void setData(Data data) {
this.data = data;
}
public int getErrCode() {
return errCode;
}
public void setErrCode(int errCode) {
this.errCode = errCode;
}
}
package TextMining.crawler;
/**
* 腾讯新闻爬虫程序测试类
* @author lyq
*
*/
public class Client {
public static void main(String[] args){
//每次评论请求数量
int reqNum;
//总评论数
int totalCommentCount;
//评论的输出路径
String outputPath;
//腾讯新闻页url链接
String newsUrl;
QQNewsCrawler crawler;
reqNum = 50;
totalCommentCount = 100;
newsUrl = "http://news.qq.com/a/20150508/004453.htm";
outputPath = "C:\Users\lyq\Desktop\我的毕业设计\newsComments2.txt";
crawler = new QQNewsCrawler(newsUrl, totalCommentCount, reqNum, outputPath);
crawler.crawlNewsComments();
}
}