今天老师请了前几届的学长来讲课,可是讲课为什么要考试呢...
学长说难度是NOIP,于是我就naive的跟着参加了,然而T3难度并不友好,感觉确实不是很适合我们现在做......不过课本来也不是给我们这一届讲的?好像逻辑非常自洽的样子。
T1:签到题
题意概述:从一个长度为n的序列中选出一个长度为k的子序列,使得子序列的字典序最大。$n<=1.5*10^7,k<=10^6$
本来想的是一个二维的dp,然而数组开不下,这时候我看向了题目名称:“签到题”,并没有意识到出题人的用意的我坚信这是一道简单题,就真的想出来了...
因为字典序是从前往后比较,如果一个数大后面的就不用再比了,有种贪心的感觉,如果一个数大,就一直往前放,这样不就可以了吗?维护一个单调栈,按照顺序往里面加数,不过还要考虑一个问题,如果这个数虽然非常大,但是太靠后了以至于把它作为第一个后面就无法选出k个数了,那不就....但是还是非常好改的,根据每一个点后面有几个点处理出它最早能插入到哪里就好了。(这个问题竟然是对拍才发现的qwq


1 # include <cstdio> 2 # include <iostream> 3 # define R register int 4 5 using namespace std; 6 7 int Top,x,y,z,n,k; 8 int a[15000009]; 9 int q[1000009]; 10 11 void ins (int x) 12 { 13 while (Top>0&&q[Top]<a[x]&&n-x>=k-Top) Top--; 14 q[++Top]=a[x]; 15 } 16 17 int main() 18 { 19 freopen("red.in","r",stdin); 20 freopen("red.out","w",stdout); 21 22 scanf("%d%d%d%d%d",&x,&y,&z,&n,&k); 23 a[1]=x; 24 for (R i=2;i<=n;++i) 25 a[i]=(long long)a[i-1]*y%z+1; 26 for (R i=1;i<=n;++i) 27 ins(i); 28 for (R i=1;i<=k;++i) 29 printf("%d ",q[i]); 30 31 fclose(stdin); 32 fclose(stdout); 33 return 0; 34 }
T2:送分题
题意概述:在一个n*m的矩阵中有一些障碍,从(1,1)出发到(n,m),每次只能往下往右走且不能走到障碍上,选出两条这样的不相交路径,求方案数。(n,m<=5000)
设$dp[i][j][k]$表示第一条路径进行到(i,j),第二条进行到(k,i+j-k)时的方案数,随便转移一下即可,但是这样只能过n,m<=300的60分,考场上没有想到正解,后来听了题解感觉非常巧妙。
1 # include <cstdio> 2 # include <iostream> 3 # define mod 1000000007 4 # define R register int 5 6 using namespace std; 7 8 int n,m,d,x; 9 int g[5005][5005]; 10 int dp[305][305][305]; 11 12 int main() 13 { 14 freopen("sun.in","r",stdin); 15 freopen("sun.out","w",stdout); 16 17 scanf("%d%d",&n,&m); 18 for (int i=1;i<=n;++i) 19 for (int j=1;j<=m;++j) 20 { 21 scanf("%1d",&x); 22 g[i][j]=x; 23 } 24 dp[1][1][1]=1; 25 for (R a=1;a<=n;++a) 26 for (R b=1;b<=m;++b) 27 for (R c=a;c<=n;++c) 28 { 29 x=0; 30 d=a+b-c; 31 if(d<1||d>m) continue; 32 if(g[a][b]||g[c][d]) continue; 33 if(a==c&&b==d&&((a==n&&b==m&&c==n)==false)) continue; 34 if(a-1!=c-1||b!=d||(a-1==1&&b==1&&c-1==1)) x=(x+dp[a-1][b][c-1])%mod; 35 if(a-1!=c||b!=d-1||(a-1==1&&b==1&&c==1)) x=(x+dp[a-1][b][c])%mod; 36 if(a!=c-1||b-1!=d||(a==1&&b-1==1&&c-1==1)) x=(x+dp[a][b-1][c-1])%mod; 37 if(a!=c||b-1!=d-1||(a==1&&b-1==1&&c==1)) x=(x+dp[a][b-1][c])%mod; 38 dp[a][b][c]=(dp[a][b][c]+x)%mod; 39 } 40 printf("%d",dp[n][m][n]); 41 fclose(stdin); 42 fclose(stdout); 43 return 0; 44 }
T3:水题
感觉题目的名字都非常神奇呢...
题意概述:(n,x<=10^6) 对于60%的数据 (n<=100,x<=10^6)
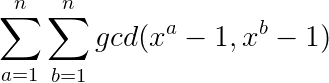
答案对1000000007取模。
感觉不大好做,就打了一个表找规律,结果还真的有规律,发现每个gcd的值都是$x^k-1$,但是这个k看起来不是很有规律,又打了一个更大的表,发现$k=gcd(a,b)$,于是就用快速幂预处理一下x的幂,$N^2logN$求出答案。这样只有60分,但是我也没有别的办法了。
1 # include <cstdio> 2 # include <iostream> 3 # define mod 1000000007 4 # define R register int 5 6 using namespace std; 7 8 int T; 9 int n,x; 10 long long ans=0; 11 long long p[10009]; 12 13 int gcd (int a,int b) 14 { 15 return b?gcd(b,a%b):a; 16 } 17 18 int main() 19 { 20 freopen("mrazer.in","r",stdin); 21 freopen("mrazer.out","w",stdout); 22 23 scanf("%d",&T); 24 while (T--) 25 { 26 ans=0LL; 27 scanf("%d%d",&x,&n); 28 p[0]=1LL; 29 for (R i=1;i<=n;++i) 30 p[i]=p[i-1]*x%mod; 31 for (R i=1;i<=n;++i) 32 for (R j=1;j<=n;++j) 33 ans=(ans+p[gcd(i,j)]-1)%mod; 34 printf("%lld ",ans); 35 } 36 fclose(stdin); 37 fclose(stdout); 38 return 0; 39 }
T2的真实做法:
为了防止重复,我们钦定第一条路永远在第二条的上面,所以可以认为第一条的起点是(1,2),终点是(n-1,m),第二条的则是(2,1),(n,m-1),两种路径的总数$n^2$就可以算,乘法原理再乘起来,这样就是不考虑相交的情况了。
相交情况的分析非常有趣。如果一条路起点是(1,2),终点是(n,m-1),另一条起点是(2,1)终点是(n,m-1),那就肯定相交了,但是既然已经钦定过了,怎么会出现这种情况呢...?所以我们拿出两条不合法的路径来看一看怎么转化。
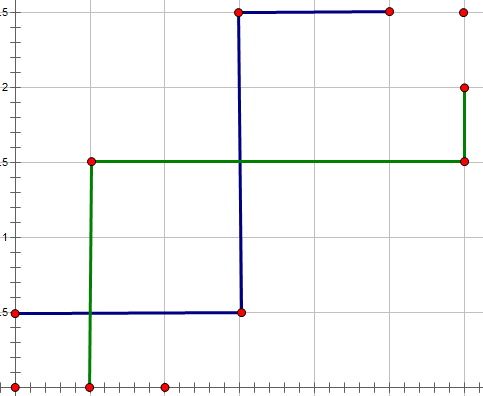
这两条路线显然是不合法的,但是它们并不满足刚刚说的不合法条件,没有关系,我们来转化一下。
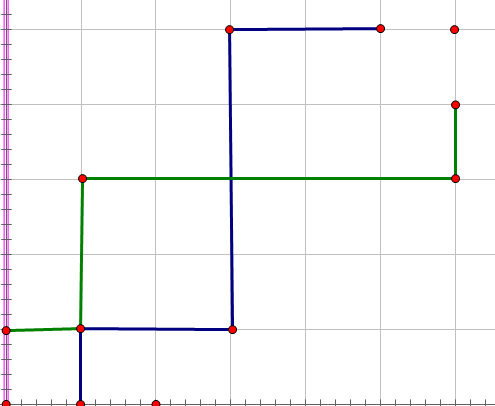
把两条不合法路径最后一次相交的点找出来,并且对调两条路径从这里往后的部分,就成了那种之前说的不合法情况了,而且这个变化是可逆的,也就是说,每一种不合法路径都有与之唯一对应的"不合法情况",所以再$n^2$处理这样的路径总数,用总方案数减去即可。
T3的真正做法:
莫比乌斯反演,线性筛欧拉函数,最后...NOIP难度。
先解释一下打表找规律的正确性,学了辗转相除gcd之后也不要忘了最简单的更相减损术呢。
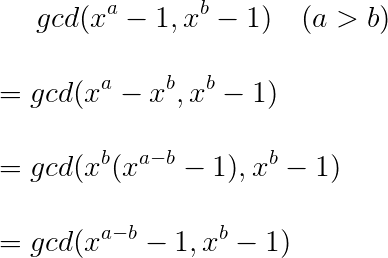
第三步是怎么推到第四步的呢?因为$gcd(x^k,x^k-1)=1$,又因为$gcd(a*c,b)=gcd(a,b) (gcd(b,c)=1)$这个结论在某一篇讲斐波那契公因数的blog里证明过。
对于指数接着用更相减损术就证出来了。(还是打表找规律好)
100分做法我也不会呀,抄抄题解先存在这里以后再看吧。
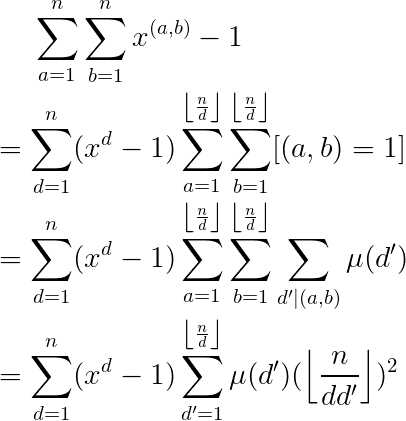
不要问我$d'$是什么,我也不知道。
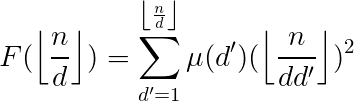
这一段可以直接复制真开心。
对每个 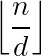 ,
, 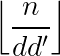 只有
只有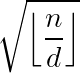 种取值。预处理$F$的复杂度是
种取值。预处理$F$的复杂度是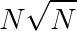 ,单次回答询问时对分段,
,单次回答询问时对分段,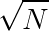 单次回答询问。时间复杂度$O(Nsqrt{N}+Tsqrt{N})$也可以不预处理,每次直接算F,时间复杂度$O(TN^{frac{4}{3}})$
单次回答询问。时间复杂度$O(Nsqrt{N}+Tsqrt{N})$也可以不预处理,每次直接算F,时间复杂度$O(TN^{frac{4}{3}})$
这都是些什么啊(小声
优化预处理F的复杂度。
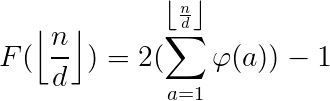
求欧拉函数的前缀和。
时间复杂度为: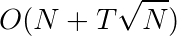
再过几年才能看懂这些呢...?
没想到我又回来了!今天是2019.1.22,烜神仙从我的blog里面又把这个题翻出来了,重新想了一下,发现没有之前认为的那么难。
回顾一下这篇文章的历史,考这套题的时候我还什么都不会,但是联赛后我就学习了反演,终于会做这道题了,甚至还找到了比之前更好想的一种做法。
下面让我们从之前咕掉的部分:更相减损术接上来,因为那一段好像已经很明白了。
$sum_{i=1}^nsum_{j=1}^nx^{(i,j)}-1$
$sum_{i=1}^nsum_{j=1}^nx^{(i,j)}-n^2$
接下来就都是一些套路了
$sum_{d=1}^nx^dsum_{i=1}^nsum_{j=1}^n[(i,j)==d]$
$sum_{d=1}^nx^dsum_{i=1}^{n/d}sum_{j=1}^{n/d}[(i,j)==1]$
看到 $gcd$ ,就可以请出莫反的常见套路了。
$sum_{d=1}^nx^dsum_{i=1}^{n/d}sum_{j=1}^{n/d}sum_{k|i,k|j}mu(k)$
$sum_{d=1}^nx^dsum_{k=1}^nmu(k)(frac{n}{kd})^2$
接下来,可以按照莫反的套路一路化下去,最终会有这个式子:
$sum_{d=1}^n(frac{n}{d})^2sum_{i|d}mu(frac{d}{i})x^i$
这之后会很难办,可以杜教筛,但是比较麻烦。
讲这个故事就是为了说明:套路固然很重要,但是如果只有套路,就会显得很不真诚,如果没有一种真诚的做题的态度,那对于不套路的题就很可能做不出来啦。
跳回几步,回到之前的式子:
$sum_{d=1}^nx^dsum_{i=1}^{n/d}sum_{j=1}^{n/d}[(i,j)==1]$
把后面一部分提出来:
$sum_{i=1}^{n/d}sum_{j=1}^{n/d}[(i,j)==1]$
改一下:
$sum_{i=1}^{n}sum_{j=1}^{n}[(i,j)==1]$
回忆一下学莫比乌斯反演的时候,做过的一些入门题目:
$sum_{i=1}^nsum_{j=1}^m[(i,j)==1]$
之所以这种题目里要引进莫比乌斯函数,是因为两个和式的上标不一样。如果一样的话,完全可以用欧拉函数来做,再一次回到原来的式子:
$sum_{i=1}^{n}sum_{j=1}^{n}[(i,j)==1]=sum_{i=1}^nsum_{j=1}^i varphi(i) imes 2-1$
形象化的说,一开始求的是一个矩阵的下半三角。(i>=j)
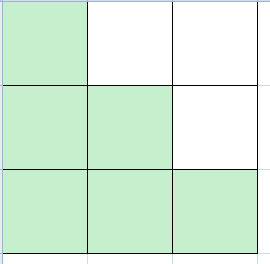
乘二是将它的对称部分也求出来。
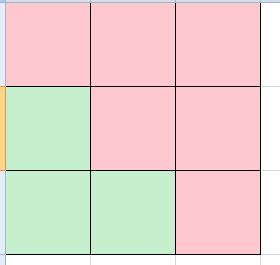
最后减掉算了两次的(1,1)这个数对,就是所需答案。
1 # include <cstdio> 2 # include <iostream> 3 # define R register int 4 # define mod 1000000007 5 # define ll long long 6 7 using namespace std; 8 9 const int maxn=1000006; 10 int T,X[maxn],N[maxn],maxx,x,n,phi[maxn],vis[maxn],pri[maxn],h; 11 ll ans; 12 13 inline int read() 14 { 15 R x=0; 16 char c=getchar(); 17 while (!isdigit(c)) c=getchar(); 18 while (isdigit(c)) x=(x<<3)+(x<<1)+(c^48),c=getchar(); 19 return x; 20 } 21 22 inline void init (int n) 23 { 24 phi[1]=1; 25 for (R i=2;i<=n;++i) 26 { 27 if(!vis[i]) pri[++h]=i,phi[i]=i-1; 28 for (R j=1;j<=h&&i*pri[j]<=n;++j) 29 { 30 vis[ i*pri[j] ]=true; 31 if(i%pri[j]==0) 32 { 33 phi[ i*pri[j] ]=1LL*phi[i]*pri[j]%mod; 34 break; 35 } 36 phi[ i*pri[j] ]=1LL*phi[i]*(pri[j]-1)%mod; 37 } 38 } 39 for (R i=2;i<=n;++i) phi[i]=(2LL*phi[i]+phi[i-1])%mod; 40 } 41 42 inline ll qui (int a,int b) 43 { 44 ll s=1; 45 while(b) 46 { 47 if(b&1) s=s*a%mod; 48 a=1LL*a*a%mod; 49 b>>=1; 50 } 51 return s; 52 } 53 54 inline int db (int x,int a,int b) 55 { 56 if(x==1) return (b-a+1); 57 return (1LL*qui(x,a)*(1-qui(x,b-a+1)+mod)%mod*qui(1-x+mod,mod-2)%mod+mod)%mod; 58 } 59 60 int main() 61 { 62 T=read(); 63 for (R i=1;i<=T;++i) X[i]=read(),N[i]=read(),maxx=max(maxx,N[i]); 64 init(maxx); 65 for (R t=1;t<=T;++t) 66 { 67 x=X[t],n=N[t],ans=0; 68 int i=1,l; 69 while(i<=n) 70 { 71 l=n/(n/i); 72 ans=((ans+1LL*phi[n/i]*db(x,i,l))%mod+mod)%mod; 73 i=l+1; 74 } 75 printf("%lld ",((ans-1LL*n*n)%mod+mod)%mod); 76 } 77 return 0; 78 }
---shzr