- 需求:模糊搜索。
- 前提: 本例中使用lucene 5.3.0
package com.shyroke.lucene; import java.io.File; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.nio.file.Paths; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.document.TextField; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.index.IndexableFieldType; import org.apache.lucene.queries.function.valuesource.DualFloatFunction; import org.apache.lucene.store.Directory; import org.apache.lucene.store.SimpleFSDirectory; public class Indexer { // 写索引 private IndexWriter indexWriter; /** * 实例化写索引 * * @param dir * 保存索引的目录 * @throws IOException */ public Indexer(String dir) throws IOException { Directory indexDir = new SimpleFSDirectory(Paths.get(dir)); /** * IndexWriterConfig实例化该类的时候如果是空的构造方法,那么默认 public IndexWriterConfig() { this(new * StandardAnalyzer()); } */ Analyzer analyzer=new StandardAnalyzer(); //分词器 IndexWriterConfig conf = new IndexWriterConfig(analyzer); indexWriter = new IndexWriter(indexDir, conf); } /** * 索引文件 */ public void index(File file) throws Exception { System.out.println("被索引的文件为:" + file.getCanonicalPath()); Document document = getDocument(file); indexWriter.addDocument(document); } /** * 从文件中获取文档 * * @param file * @return * @throws IOException */ private Document getDocument(File file) throws IOException { Document document = new Document(); Field contentField = new TextField("fileContents", new FileReader(file)); /** * Field.Store.YES表示把该Field的值存放到索引文件中,提高效率,一般用于文件的标题和路径等常用且小内容小的。 */ Field fileNameField = new TextField("fileName", file.getName(), Field.Store.YES); Field filePathField = new TextField("filePath", file.getCanonicalPath(), Field.Store.YES); document.add(contentField); document.add(fileNameField); document.add(filePathField); return document; } /** * 创建索引 * * @param dataFile 数据文件所在的目录 * @return 索引文件的数量 * @throws Exception */ public int CreateIndex(String dataFile, FileFilter filter) throws Exception { File[] files = new File(dataFile).listFiles(); for (File file : files) { /** * 被索引文件必须不能是 1.目录 2.隐藏 3. 不可读 4.不是txt文件, * 否则不被索引 */ if (!file.isDirectory() && !file.isHidden() && file.canRead() && filter.accept(file)) { index(file); } } return indexWriter.numDocs(); } /** * 关闭写索引 * * @throws IOException */ public void close() throws IOException { indexWriter.close(); } }
- 这个类用来遍历数据文件夹,生成索引文件。
-
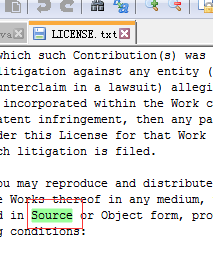
对特定项搜索
public class SearchTest { private IndexWriter writer; private IndexSearcher search; private IndexReader reader; private String indexDir = "E:\\lucene4\\index"; private String dataDir = "E:\\lucene4\\data"; @Before public void setUp() throws Exception { Indexer indexer = new Indexer(indexDir); indexer.CreateIndex(dataDir, new FileFilter()); /** * 一定要把IndexWriter实例关闭,否则segments_1文件不会生成。 */ indexer.close(); Directory indexDirectory = FSDirectory.open(Paths.get(indexDir)); reader = DirectoryReader.open(indexDirectory); search = new IndexSearcher(reader); } @After public void tearDown() throws Exception { reader.close(); } /** * 对特定项搜索 * @throws IOException */ @Test public void textTermQuery() throws IOException { System.out.println("--------------------"); String key = "particular"; Term t = new Term("fileContents", key); Query query = new TermQuery(t); TopDocs hits = search.search(query, 10); System.out.println("匹配 '" + key + "',总共查询到" + hits.totalHits + "个文档"); for (ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = search.doc(scoreDoc.doc); System.out.println(doc.get("filePath")); } } }
- 注意:上述代码中的橙色标注代码,一定要把IndexWriter实例关闭,否则segments_1文件不会生成。
结果:
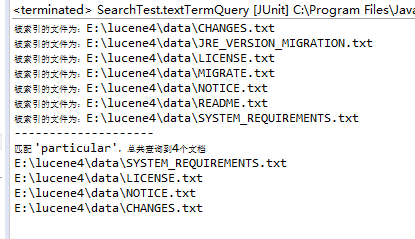
- 解析:对特定项搜索的方法是以搜索关键字作为单位查询,如果把关键字key改为key="particul" ,则结果如下,无法匹配到particular:
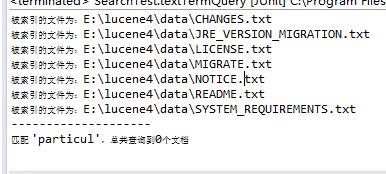
-
解析查询表达式
/** * 解析查询表达式,在要搜索的关键字中可以使用AND OR ~ * ?等 * AND 与 OR 或 ~相近 * AND和OR只能大写 * @throws ParseException * @throws IOException */ @Test public void testQueryParse() throws ParseException, IOException { System.out.println("--------------------"); Analyzer analyzer=new StandardAnalyzer(); QueryParser parser=new QueryParser("fileContents", analyzer); String key="Source* AND Derivati*"; Query query=parser.parse(key); TopDocs hits =search.search(query, 10); System.out.println("匹配 '" + key + "',总共查询到" + hits.totalHits + "个文档"); for (ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = search.doc(scoreDoc.doc); System.out.println(doc.get("filePath")); } }
结果:
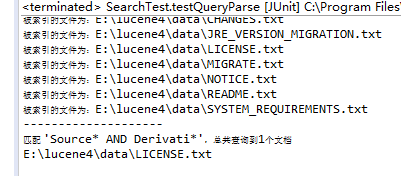
- 查看LICENSE.txt文档,