什么特征选择
- 特征选择 ( Feature Selection )也称特征子集选择( Feature Subset Selection , FSS ) ,或属性选择( Attribute Selection ) ,是指从全部特征中选取一个特征子集,使构造出来的模型更好。
为什么要做特征选择
在机器学习的实际应用中,特征数量往往较多,其中可能存在不相关的特征,特征之间也可能存在相互依赖,容易导致如下的后果:
特征个数越多,分析特征、训练模型所需的时间就越长。
特征个数越多,容易引起“维度灾难”,模型也会越复杂,其推广能力会下降。
特征选择能剔除不相关(irrelevant)或亢余(redundant )的特征,从而达到减少特征个数,提高模型精确度,减少运行时间的目的。另一方面,选取出真正相关的特征简化了模型,使研究人员易于理解数据产生的过程。
特征选择基本原则
数据预处理完成之后,我们需要选择有意义的特征,输入机器学习的算法和模型进行训练,通常来说,从两个方面考虑来选择特征
如何选择特征
是否发散
是否相关
如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本没有差异,那我们就可以判断,这个特征对于样本的区别并没有什么用
第二个是特征与目标的相关性,与目标相关性高的特征应该优先选择
特征选择常用的四种方法
我们以互联网金融实际情景举例:
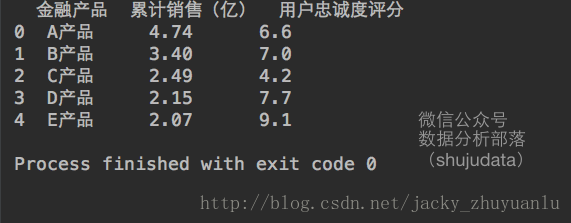
- 说白了,特征选择,就是看累计销售和用户忠诚度评分能不能成为金融产品的特征,我们会有一系统的评估标准,当然这些评估标准也都有人为主观判断在的。
(一)方差选择法(过滤法)
- 使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。使用feature_selection库的VarianceThreshold类来选择特征的代码如下:
#首先把数据导入到data变量中
import pandas
data=pandas.read_csv('路径.csv')
#使用VarianceThreshold类进行方差过滤
from sklearn.feature_selection import VarianceThreshold
#要生成这个类的对象,就需要一个参数,就是最小方差的阈值,我们先设置为1,然后调用它的transform方法进行特征值的过滤
variancethreshold=VarianceThreshold(threshold=1)
variancethreshold.fit_transform(data[['累计销售(亿)','用户忠诚度评分']])
#使用get_support方法,可以得到选择特征列的序号,然后根据这个序号在原始数据中把对应的列名选择出来即可
varianceThreshold.get_support()threshold=1两个特征都被显示出来了
为什么阈值设定为1,累计销售与用户忠诚度这两个特征都被选择了出来?
首先我们看下累计销售与用户忠诚度各自的方差是什么?
#看下这两个特征的方差是什么?
data[['累计销售(亿)','用户忠诚度评分']].std()
(二)相关系数法
- 先计算各个特征对目标值的相关系数,选择更加相关的特征。
以互联网金融行业为例

#首先导入数据到data变量中
import pandas
data=pandas.read_csv('路径.csv')
#然后,SelectKBest类,通过回归的方法,以及要选择多少个特征值,新建一个 SelectKBest对象,
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
selectKBest = SelectKBest(
f_regression,k=2
)
#接着,把自变量选择出来,然后调用fit_transform方法,把自变量和因变量传入,即可选出相关度最高的两个变量。
feature =data[['月份','季度','广告推广费','注册并投资人数']]
bestFeature =selectKBest.fit_transform(
feature,
data['销售金额']
)
#我们想要知道这两个自变量的名字,使用get_support方法即可得到相应的列名
feature.columns[selectKBest.get_support()]最终,python帮助我们选择的特征是:

(三)递归特征消除法
- 使用一个基模型来进行多轮训练,经过多轮训练后,保留指定的特征数。
还是延用上面那个案例
#首先导入数据到data变量中
import pandas
data=pandas.read_csv('路径.csv')
#接着,我们使用RFE类,在estimator中,把我们的基模型设置为线性回归模型LinearRegression,然后在把我们要选择的特征数设置为2,接着就可以使用这个rfe对象,把自变量和因变量传入fit_transform方法,即可得到我们需要的特征值
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
feature =data[['月份','季度','广告推广费','注册并投资人数']]
rfe =RFE(
estimator=LinearRegression(),
n_features_to_select=2
)
sFeature = rfe.fit_transform(
feature,
data['销售金额']
)
#同理,我们要想知道这两个自变量的名字,使用get_support方法,即可得到对应的列名
rfe.get_support()(四)模型选择法
- 它是一种我们把建好的模型对象传入选择器,然后它会根据这个已经建好的模型,自动帮我吗选择最好的特征值。
还是延用上面那个案例
import pandas
data = pandas.read_csv('file:///Users/apple/Desktop/jacky_2.csv',encoding='GBK')
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LinearRegression
feature =data[['月份','季度','广告推广费','注册并投资人数']]
lrModel = LinearRegression()
selectFromModel = SelectFromModel(lrModel)
selectFromModel.fit_transform(
feature,
data['销售金额']
)
selectFromModel.get_support()- 这里jacky就强调一点,模型选择法并不需要指定我们需要多少个特征,selectFromModel的方法会自动帮我们选择最优的特征数
总结
对于特征选择来说,其实是非常简单的,科学总把简单的问题说的如此的复杂,在彰显它严谨的同时,也是不想让太多的人进入科学这个圈子,因为它真的太简单了。
有时间的小伙伴可以思考一下,特征选择的第一个方法对应的就是发散性,后面三个方法对应的就是回归。我们细细琢磨,后三个方法其实是一回事,但是得到的结果却略有不同,参透这其中的道理,也就参透数据挖掘和机器学习的奥秘了。