决策树是最经常使用的数据挖掘算法,本次分享jacky带你深入浅出,走进决策树的世界
基本概念
决策树(Decision Tree)
- 它通过对训练样本的学习,并建立分类规则,然后依据分类规则,对新样本数据进行分类预测,属于有监督学习。
优点
1)决策树易于理解和实现
- 使用者不需要了解很多的背景知识,通过决策树就能够直观形象的了解分类规则;
2)决策树能够同时处理数值型和非数值型数据
- 在相对短的时间内,能够对大型数据做出可行且效果良好的结果;
逻辑-类比找对象
决策树分类的思想类似于找对象,例如一个女孩的母亲要给这个女孩介绍男朋友,于是母女俩有了下面的对话:
女儿问:“多大年龄了”;母亲答:“26”
女儿接着问:“长得帅不帅?”;母亲答:“挺帅的。”
女儿问:“收入高不?”;母亲答:“不算很高,中等情况”
女儿问:“是公务员吗?”;母亲答:“是,在财政局上班”
最后,女儿做出决定说:“那好,我去见见!”
这个女孩的决策过程就是典型的分类树决策:
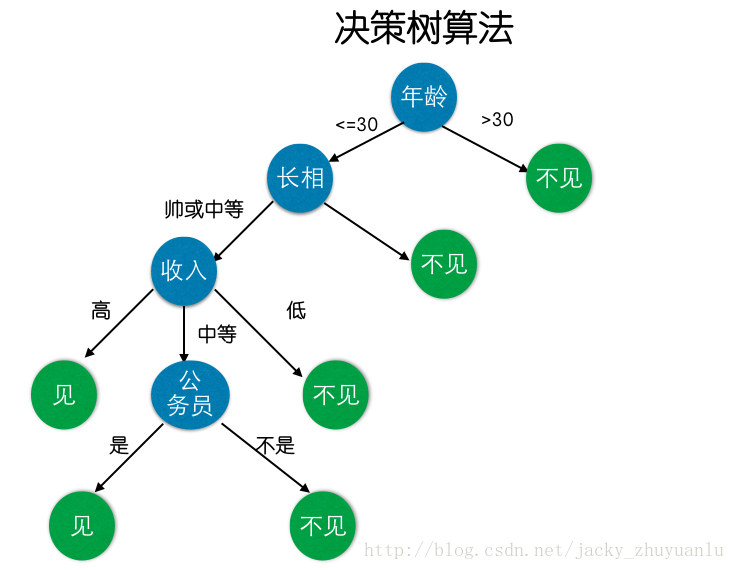
在来看一个金融场景下的举例:客户向银行贷款的时候,银行对用户的贷款资格做一个评估的流程:
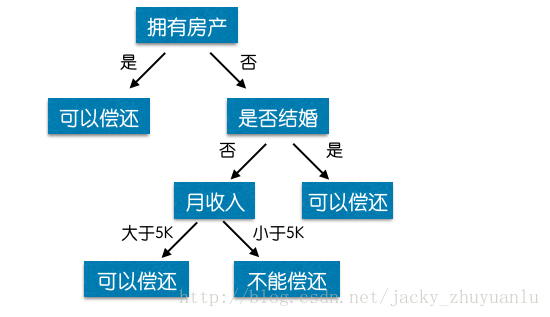
首先银行工作人员询问客户是否有房产,如何回答有,则判断客户可以偿还贷款,如果没有则进入第二层的属性判断询问,是否结婚,如何已婚,两个人可以负担的起贷款,则判断为可以偿还,否则进入第三层的属性判断询问,月薪是否超过五千,如果满足,则判断为可以偿还,否则给出不能偿还贷款的结论。
看完上面两个例子,我们可以看出,决策树是非常实用的,下面我们就进入正式案例的讲解;
案例实操
下面以金融场景举例:
情景铺垫
用户在购买互联网金融产品的过程“类似于”理财,对于P2P平台来说,严格来说,这个过程称之为撮合。
用户金融平台上充值购买相应期限和约定利率的金融产品,产品到期后,用户有两种选择一个是提现(赎回),另一个就是复投。
对于用户到期赎回的理解是比较简单的,比如你在2018年1月1日买了6个月10万定存金融产品,那么在2018年7月1日的时候,你可以选择连本带息全部赎回,当然你也可以在到期日选择在平台还款时,继续投资,这个过程就是复投。
下面,在严谨一点归纳复投的定义就是:
针对按月等额本息还款的用户,还款或,用户自己再投,这个过程就是复投。
需解决的问题
作为金融平台来说,为了把控风险,保证资金的流动性,都一定要提前预测(预判)未来一段时间内的用户充值和提现金额。
那么,准确预测用户到期是否复投,对于我们金融从业者和管理人员来说,就是特别重要了。
那么,我们可以提出我们亟需解决的问题:
- 用户到期是否复投,我们改怎样预判?
一个初步模型的建立
场景:预测用户是否复投
注:以下源数据模拟真实数据编撰
(一)选择特征变量-featureDate
1. 数据源抓取
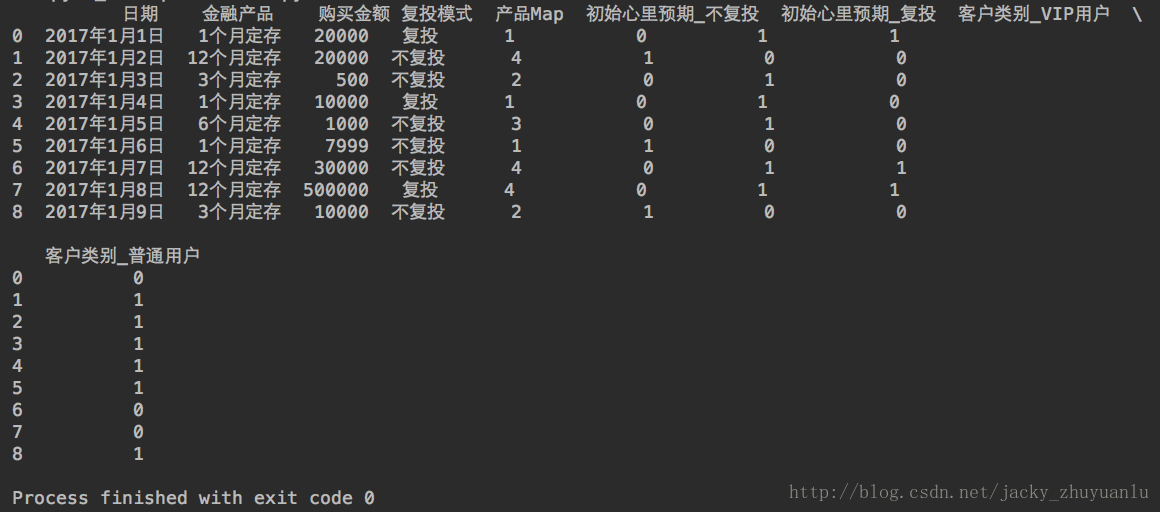
import pandas
data = pandas.read_csv('file:///Users/apple/Desktop/jacky_reinvest.csv',encoding='GBK')
print(data)
jacky注解(1):上面这份数据源其实是经过预处理(或者说是经过初步的数据清理的),我们拿到数据源的第一步一定是做数据清理的,数据科学与传统的统计科学,在实操中,区别最大的可能就是数据清理了,本文的数据源只用于学习举例用,所以数据还是比较规整的,但在实际工作中,一定不要忘了数据清洗这一步。
jacky注解(2): 初始心里预期这列是一个产品概念,就是用户在购买定存金融产品的时候,可以预先设定是否需要复投,当然这只是一个预设定,在用户购买到赎回这个过程中,我们都可以随时变更。复投模式是一个过去式,也是最终的复投结果,所以下面我们会把这列当作目标变量来处理。
2. 哑变量处理(虚拟变量转化)
需处理的特征变量有:
金融产品
初始心里预期
客户类别
#调用Map方法进行可比较大小虚拟变量的转换
productDict={'12个月定存':4,'6个月定存':3,'3个月定存':2,'1个月定存':1}
data['产品Map']=data['金融产品'].map(productDict)
#调用get_dummyColumns方法进行不可比较大小虚拟变量的转换
dummyColumns = ['初始心里预期','客户类别',]
for column in dummyColumns:
data[column]= data[column].astype('category')
dummiesData=pandas.get_dummies(
data,
columns=dummyColumns,prefix=dummyColumns
,prefix_sep='_',dummy_na=False,drop_first=False)
#挑选可以建模的变量 featureData
fData = dummiesData[[
'购买金额','产品Map','初始心里预期_复投','客户类别_VIP用户'
]]
jacky注解(3):关于哑变量更详细的说明,可以参照我《特征工程三部曲》这篇文章,哑变量处理要处理的就是离散变量,购买金额的列,因为都是连续型数据,所以就谈不上虚拟变量处理的。
jacky注解(4):离散变量分为有比较关系的离散变量和无比较关系的离散变量,所以需要用map方法和get_dummyColumns方法分别处理;
(二)选择目标变量-targerDate
#设定目标变量 targetData
tData = dummiesData['复投模式']- jacky注解(5):目标变量是我们分析问题的目标和结果,从目标变量既定的历史数据中,我们可以”喂养”数据,继而训练数据,最终达到洞察预测数据的目的。
(三)决策树问题的求解与建模
#生成决策树
from sklearn.tree import DecisionTreeClassifier
#设置最大叶子数为5
dtModel = DecisionTreeClassifier(max_leaf_nodes=5)- jacky注解(6):生成决策树并设置最大叶子树为5,使⽤sklearn的DecisionTreeClassifer类进⾏行决策树问题的求解与建模,关于最大叶子树,可以在看过图形化之后,在反过来理解这部分,就简单的多了,在这里我们可以先理解为是一个很常用的参数即可。
(四)10折交叉验证
#模型检验-交叉验证法
from sklearn.model_selection import cross_val_score
cross_val_score(
dtModel,
fData,tData,cv=10
)
- jacky注解(7):从控制台的输出可以看出,每次验证的评分都超过0.9,是一个非常不错的模型,可以用于实践;
(五)模型训练
#训练模型
dtModel=dtModel.fit(fData,tData)控制台结果输出:

(六)模型可视化
决策树的绘图方法:
sklearn.tree.export_graphviz(… …)
dtModel:决策树模型
out_file:图形数据的输出路径
class_names:目标属性的名称,一般用于中文化
feature_names:特征属性的名称,一般用于种文化
filled= True :是否使用颜色填充
rounded=True:边框是否采用圆角边框
special_characters: 是否有特殊字符
#模型可视化
import pydotplus
from sklearn.externals.six import StringIO #生成StringIO对象
from sklearn.tree import export_graphviz
dot_data = StringIO() #把文件暂时写在内存的对象中
export_graphviz(
dtModel,
out_file=dot_data,
class_names=['复投','不复投'],
feature_names=['购买金额','产品Map','初始心里预期_不复投','客户类别_VIP用户'],
filled=True,rounded=True,special_characters=True
)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('shujudata.png')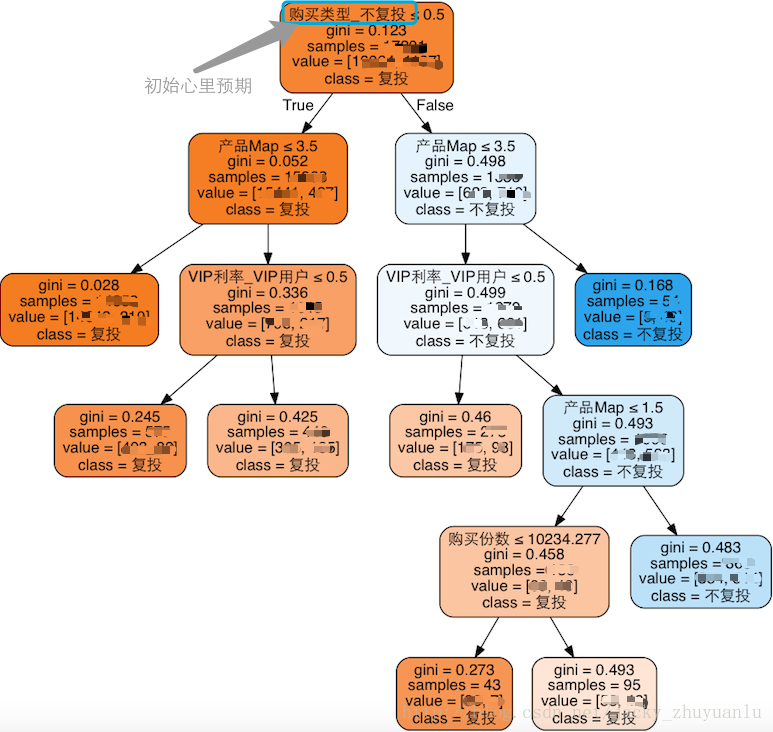
jacky注解(8):需要提前安装graphviz软件
jacky注解(9):最大叶子树,一般设置为8个,因为叶子数太多,决策树的结构越复杂,太复杂的结构就会导致训练过度的问题,因此,在决策树算法中,设置合适叶子数是非常重要的。
jacky注解(10):gini值越接近于0,那么结果就越显而易见,如果越接近于1,那么结果就越难判定;
完整代码展示
#---author:朱元禄---
import pandas
data = pandas.read_csv('file:///Users/apple/Desktop/jacky_reinvest.csv',encoding='GBK')
#调用Map方法进行可比较大小虚拟变量的转换
productDict={'12个月定存':4,'6个月定存':3,'3个月定存':2,'1个月定存':1}
data['产品Map']=data['金融产品'].map(productDict)
#调用get_dummyColumns方法进行可比较大小虚拟变量的转换
dummyColumns = ['初始心里预期','客户类别',]
for column in dummyColumns:
data[column]= data[column].astype('category')
dummiesData=pandas.get_dummies(
data,
columns=dummyColumns,prefix=dummyColumns
,prefix_sep='_',dummy_na=False,drop_first=False)
#挑选可以建模的变量 featureData
fData = dummiesData[[
'购买金额','产品Map','初始心里预期_复投','客户类别_VIP用户'
]]
#设定目标变量 targetData
tData = dummiesData['复投模式']
#生成决策树
from sklearn.tree import DecisionTreeClassifier
#设置最大叶子数为8
dtModel = DecisionTreeClassifier(max_leaf_nodes=8)
'''
#模型检验-交叉验证法
from sklearn.model_selection import cross_val_score
cross_val_score(
dtModel,
fData,tData,cv=10
)
'''
#训练模型
dtModel=dtModel.fit(fData,tData)
#模型可视化
import pydotplus
from sklearn.externals.six import StringIO #生成StringIO对象
from sklearn.tree import export_graphviz
dot_data = StringIO() #把文件暂时写在内存的对象中
export_graphviz(
dtModel,
out_file=dot_data,
class_names=['复投','不复投'],
feature_names=['购买金额','产品Map','初始心里预期_不复投','客户类别_VIP用户'],
filled=True,rounded=True,special_characters=True
)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('shujudata.png')