爬取的思路
首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号信息和被关注信息的关注列表,爬取这些用户的信息,通过这种递归的方式从而爬取整个知乎的所有的账户信息。整个过程通过下面两个图表示:

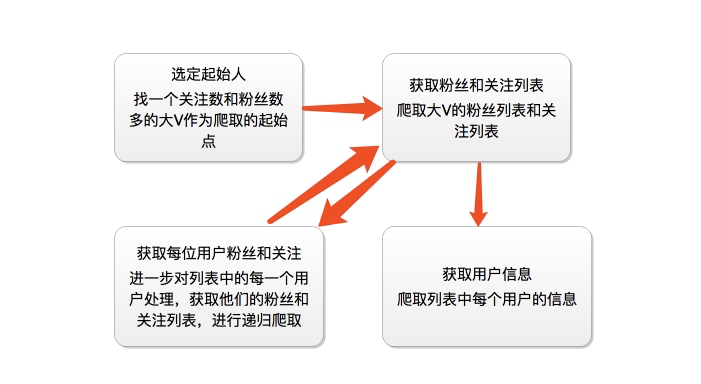
爬虫分析过程
这里我们找的账号地址是:https://www.zhihu.com/people/excited-vczh/answers
我们抓取的大V账号的主要信息是:

其次我们要获取这个账号的关注列表和被关注列表
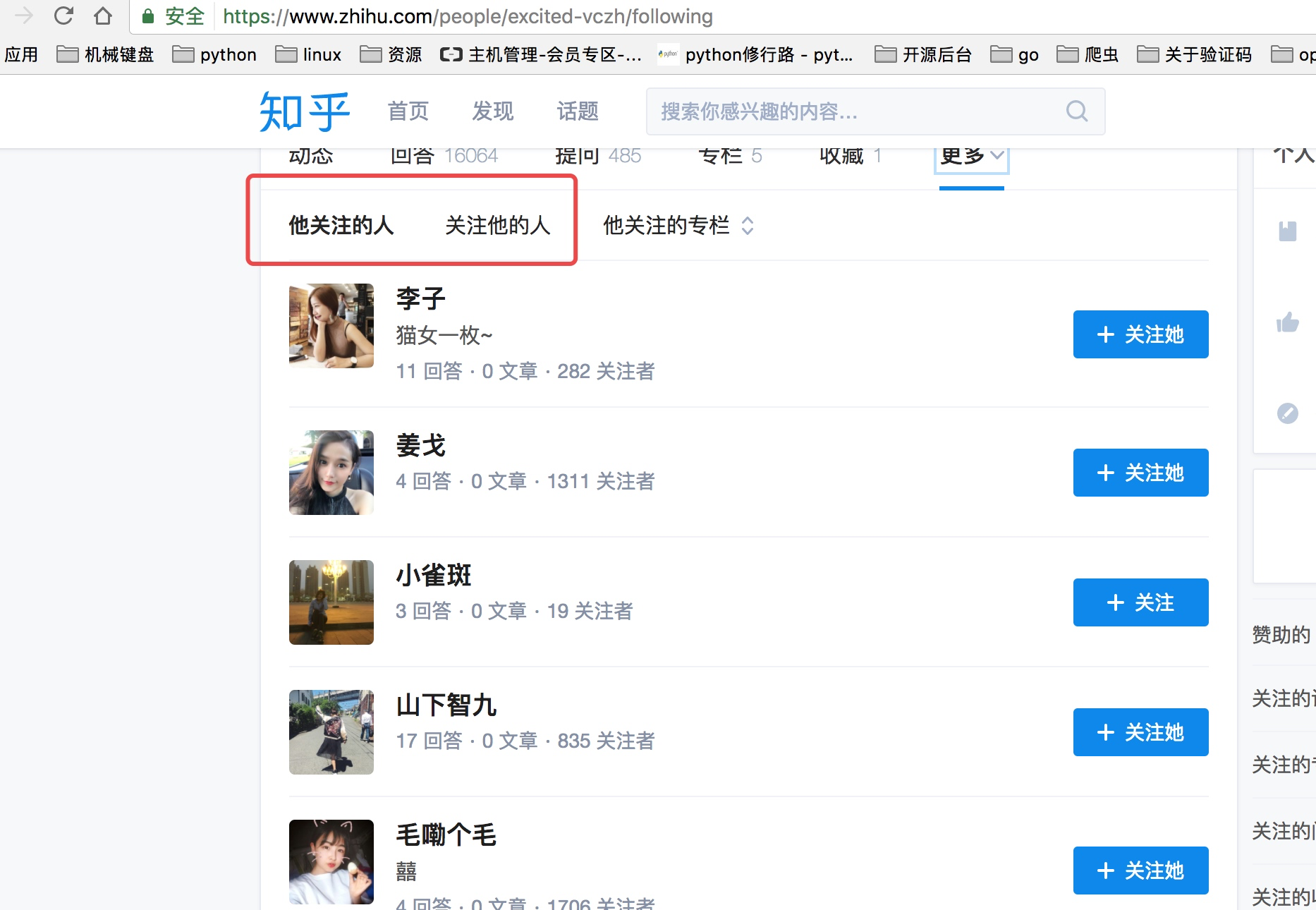
这里我们需要通过抓包分析如果获取这些列表的信息以及用户的个人信息内容
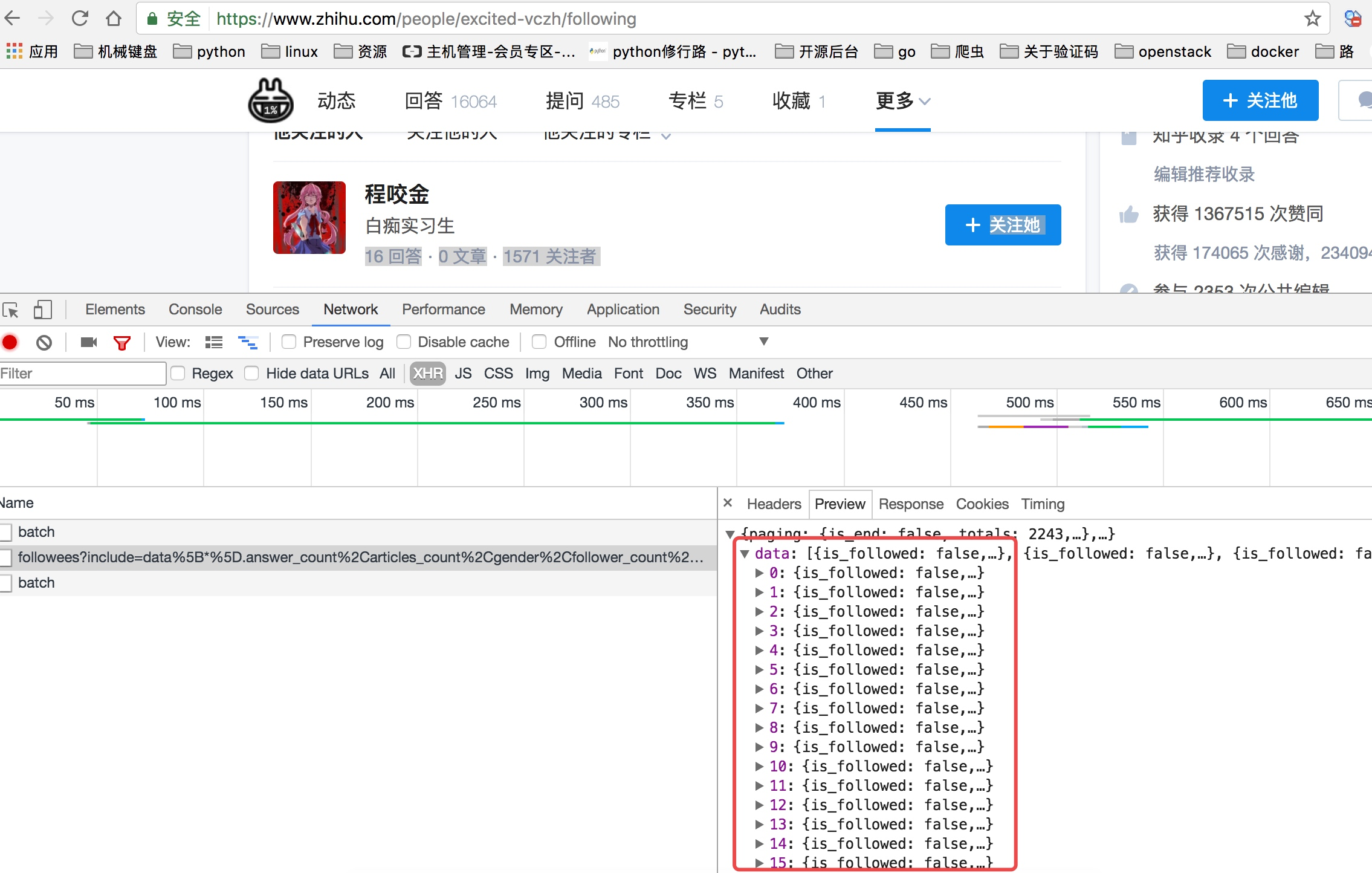
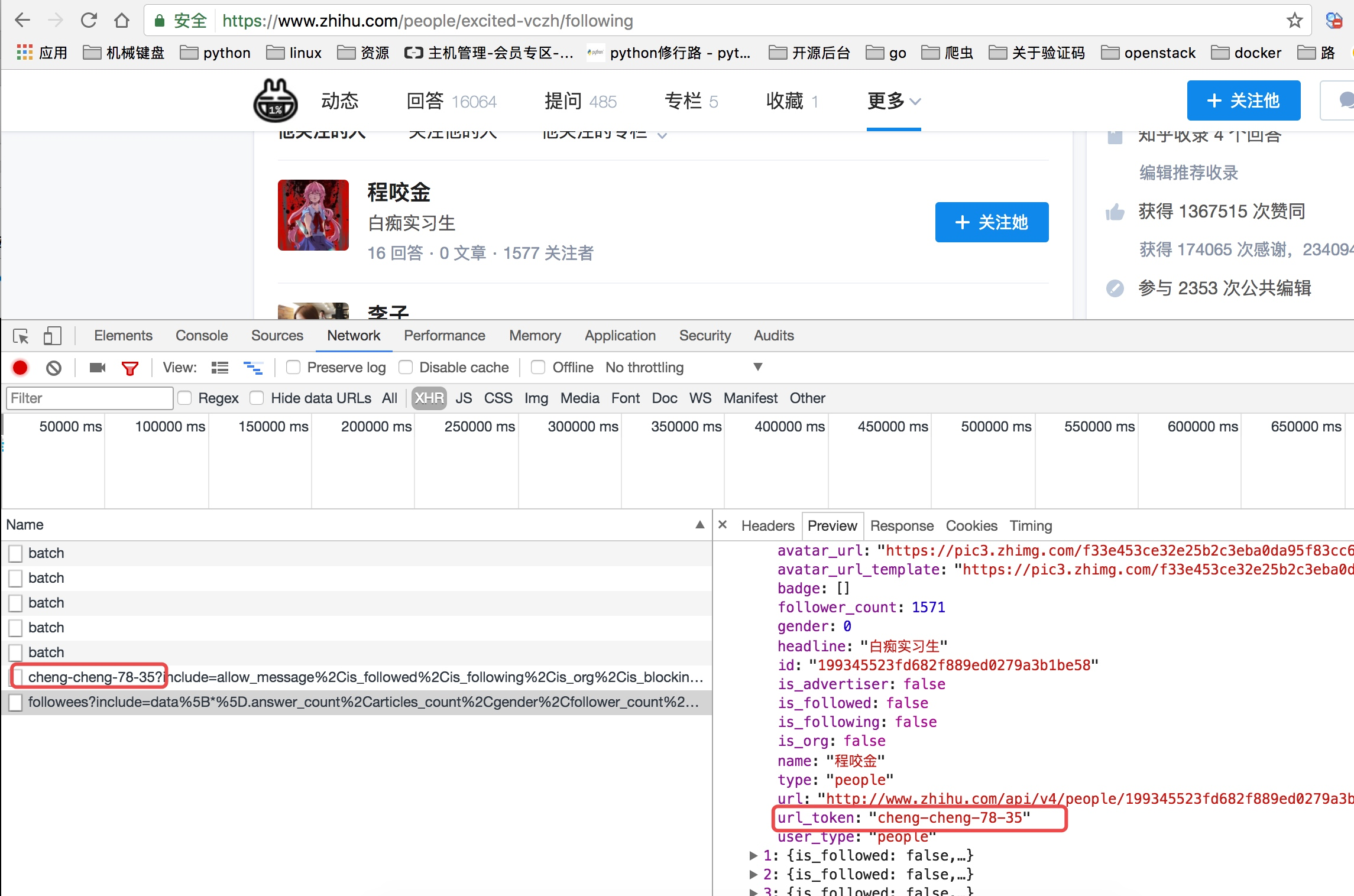
当我们查看他关注人的列表的时候我们可以看到他请求了如下图中的地址,并且我们可以看到返回去的结果是一个json数据,而这里就存着一页关乎的用户信息。


上面虽然可以获取单个用户的个人信息,但是不是特别完整,这个时候我们获取一个人的完整信息地址是当我们将鼠标放到用户名字上面的时候,可以看到发送了一个请求:
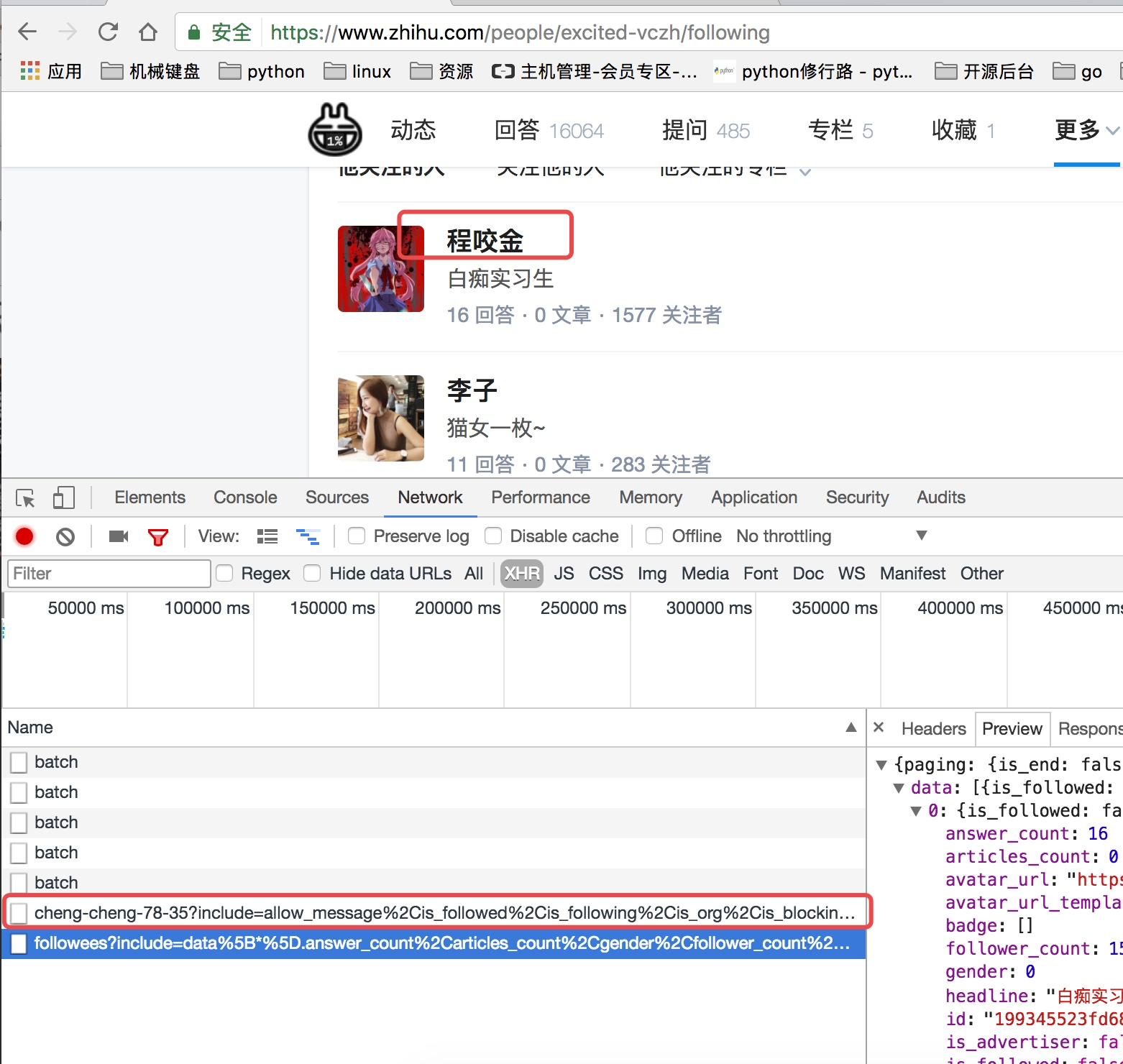
我们可以看这个地址的返回结果可以知道,这个地址请求获取的是用户的详细信息:

通过上面的分析我们知道了以下两个地址:
获取用户关注列表的地址:https://www.zhihu.com/api/v4/members/excited-vczh/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=0&limit=20
获取单个用户详细信息的地址:https://www.zhihu.com/api/v4/members/excited-vczh?include=locations%2Cemployments%2Cgender%2Ceducations%2Cbusiness%2Cvoteup_count%2Cthanked_Count%2Cfollower_count%2Cfollowing_count%2Ccover_url%2Cfollowing_topic_count%2Cfollowing_question_count%2Cfollowing_favlists_count%2Cfollowing_columns_count%2Cavatar_hue%2Canswer_count%2Carticles_count%2Cpins_count%2Cquestion_count%2Ccolumns_count%2Ccommercial_question_count%2Cfavorite_count%2Cfavorited_count%2Clogs_count%2Cmarked_answers_count%2Cmarked_answers_text%2Cmessage_thread_token%2Caccount_status%2Cis_active%2Cis_bind_phone%2Cis_force_renamed%2Cis_bind_sina%2Cis_privacy_protected%2Csina_weibo_url%2Csina_weibo_name%2Cshow_sina_weibo%2Cis_blocking%2Cis_blocked%2Cis_following%2Cis_followed%2Cmutual_followees_count%2Cvote_to_count%2Cvote_from_count%2Cthank_to_count%2Cthank_from_count%2Cthanked_count%2Cdescription%2Chosted_live_count%2Cparticipated_live_count%2Callow_message%2Cindustry_category%2Corg_name%2Corg_homepage%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics
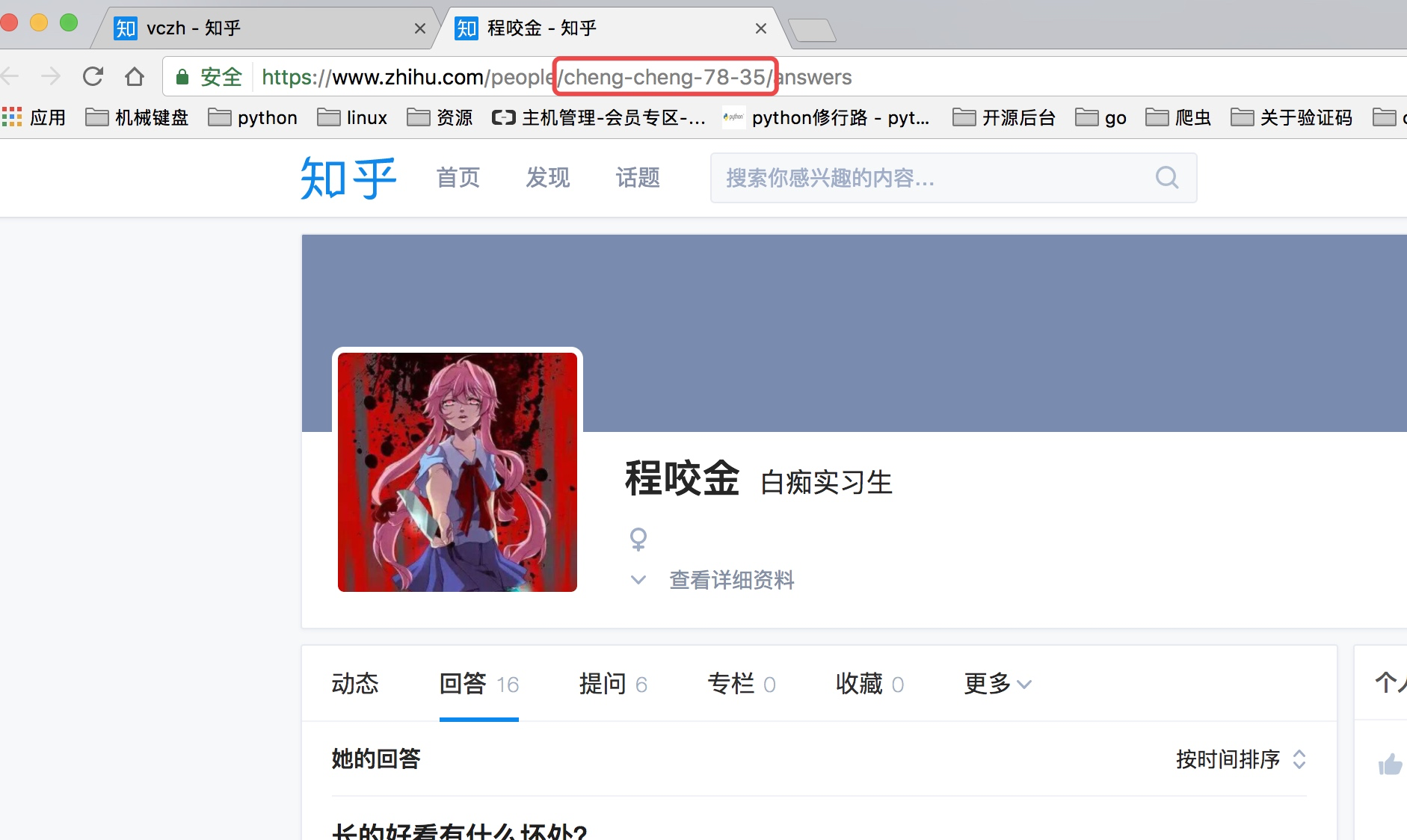
这里我们可以从请求的这两个地址里发现一个问题,关于用户信息里的url_token其实就是获取单个用户详细信息的一个凭证也是请求的一个重要参数,并且当我们点开关注人的的链接时发现请求的地址的唯一标识也是这个url_token
创建项目进行再次分析
通过命令创建项目
scrapy startproject zhihu_user
cd zhihu_user
scrapy genspider zhihu www.zhihu.com
直接通过scrapy crawl zhihu启动爬虫会看到如下错误:

这个问题其实是爬取网站的时候经常碰到的问题,大家以后见多了就知道是怎么回事了,是请求头的问题,应该在请求头中加User-Agent,在settings配置文件中有关于请求头的配置默认是被注释的,我们可以打开,并且加上User-Agent,如下:
关于如何获取User-Agent,可以在抓包的请求头中看到也可以在谷歌浏览里输入:chrome://version/ 查看
这样我们就可以正常通过代码访问到知乎了
然后我们可以改写第一次的请求,这个我们前面的scrapy文章关于spiders的时候已经说过如何改写start_request,我们让第一次请求分别请求获取用户列表以及获取用户信息

这个时候我们再次启动爬虫

我们会看到是一个401错误,而解决的方法其实还是请求头的问题,从这里我们也可以看出请求头中包含的很多信息都会影响我们爬取这个网站的信息,所以当我们很多时候直接请求网站都无法访问的时候就可以去看看请求头,看看是不是请求头的哪些信息导致了请求的结果,而这里则是因为如下图所示的参数:
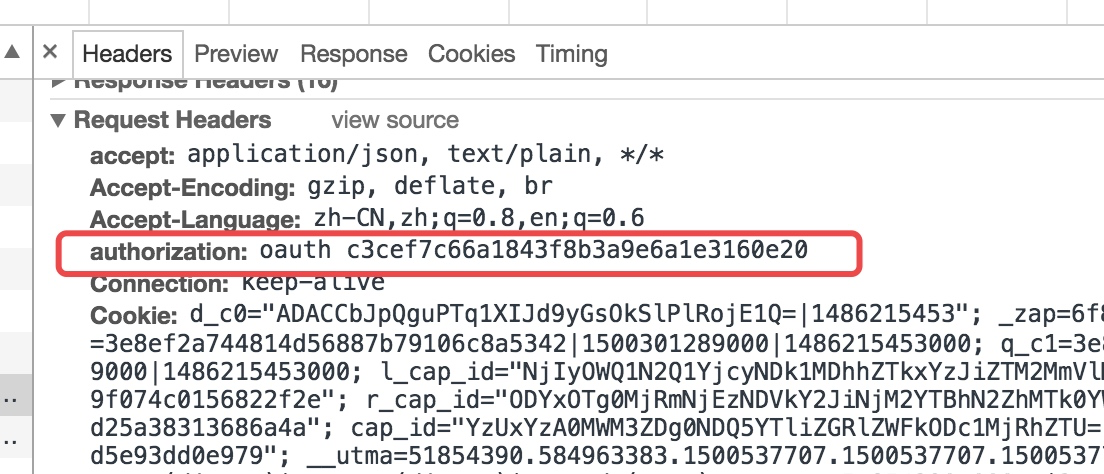
所以我们需要把这个参数同样添加到请求头中:

然后重新启动爬虫,这个时候我们已经可以获取到正常的内容
到此基本的分析可以说是都分析好了,剩下的就是具体代码的实现,在下一篇文张中写具体的实现代码内容!