引言
din是阿里妈妈17年的论文,其中在之前embedding&mlp基础上增加了attention,主要思想是:embedding&mlp结构中,并未考虑到用户历史商品的针对性,举个例子:
- 用户a历史商品中主要都是衣服;
- 用户b历史商品中主要都是电子书
可以得出,用户a,如果给他呈现的推荐商品是衣服,他更感兴趣一些,所以,如何基于注意力机制,将用户历史商品的感兴趣点提取出来,然后针对召回集中的衣服类商品进行提权,不感兴趣的进行降权,就很有意思了。
din相对embedding&mlp结构改动其实不大,就是将tf.nn.embedding_lookup_sparse 的 sum 结合器改成加权形式。
改动点
假定输入数据如下:
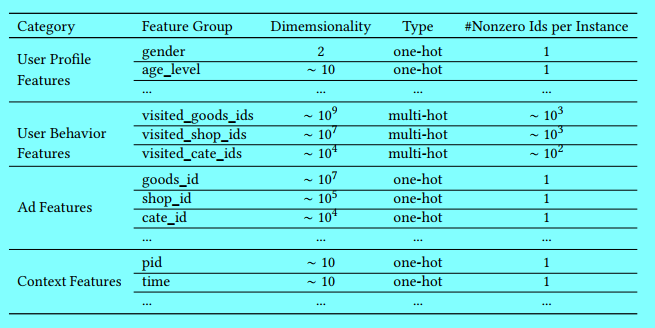
主要就是4类数据:
- 用户属性,是onehot类,如:性别,年龄;
- 用户历史行为特征,是multihot类,比如逛过的店(第1家,第3家,第5家),商品类别(第1类,第5类,第999类);
- 推荐的商品,是onehot类,
- 上下文特征,可以是onehot类,也可以直接是一个向量矩阵(如用户点击触发的在线特征组成一个向量,商品的离线特征组成一个向量)

上图就是embedding&mlp结构,可以看出4类信息,
- 第一类用户属性特征,通过embedding直接生成并concat成一个向量,即最终是一个向量
- 第二类就是用户历史行为特征,即多个历史商品,生成多个向量,这多个向量经过sum pool得到一个向量
- 第三类就是推荐的那个商品,如第一类用户属性特征一样,最终生成一个向量
- 第四类就是上下文特征,也如第一类用户属性特征一样,最终生成一个向量
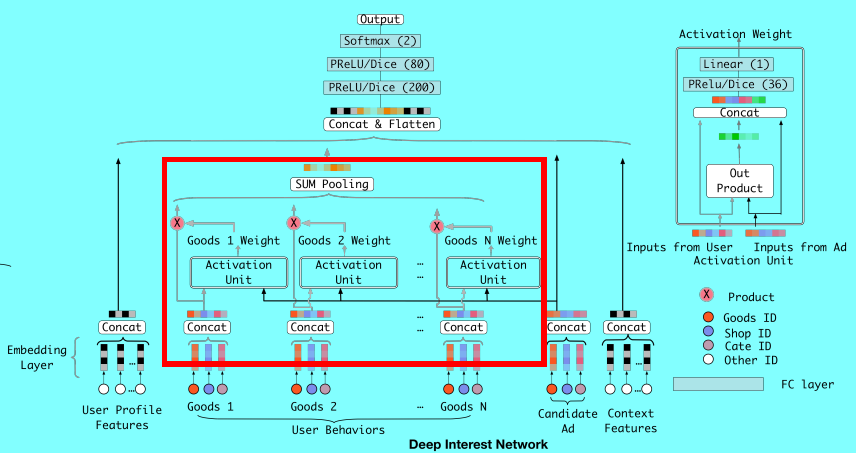
上图可以看出,相比embedding&mlp的改变就是在第二类特征和第三类特征之间多了个权重计算,
- 第二类中每个历史商品都和第三类特征计算出一个权重;
- 对应权重乘以对应历史商品
- 再将上面的权重后的历史商品进行sum pooling
核心结构代码
这里,我们假定输入数据如下,即不是和论文中一致:
{
# 一共三个样本,label表示用户是否点击
label:[1,0,1],
#---------------------------
good:['商品id1','商品id2','商品id3'], # 候选商品
brand:['类别1','类别2','类别1'], # 候选商品对应品类
l4:['4级页1','4级页2','4级页3'], # 候选商品对应的4级页
#-------------------------------
# @为分隔符
history_good:["商品id9@商品id1000@商品id2",
"商品id9@商品id1000@商品id2@商品id7",
"商品id9@商品id976"
]
history_brand:["类别9@类别1000@类别2",
"类别9@类别1000@类别id2@类别7",
"类别9@类别976"
]
history_l4:[ "4级页9@4级页1000@4级页2",
"4级页9@4级页1000@4级页2@4级页d7",
"4级页9@4级页976"
]
#-------------------------------
# 商品物料特征,,离线式,每一个样本都是一个实值向量 ,
offfeatures:[[98,123,32,123,42,31,5324],
[2,13,2,123,424,341,53524],
[931,134123,342,12323,42,31,5324]
]
# 用户属性及触发行为特征,在线式,每一个样本都是一个实值向量
onlinefeatures:[[98,123,32,123,42,31,5324],
[1,2,3,4,5,6,7],
[9,8,7,6,5,4,3]
]
}
假定真实数据如上述形式,则对应的,我们生成三个embedding,分别为g,b,l
- good与history_good共享名称为g的embedding矩阵;
- brand与history_brand共享名为b的embedding矩阵;
- l4与history_l4共享名为l的embedding矩阵
其中:
cluster_di={ 'embeddingmatrix': {'matrixname': ['g', 'l', 'b'],
'g': {'inputsize': 100000, 'outputsize': 32},
'l': {'inputsize': 100000, 'outputsize': 32},
'b': {'inputsize': 100000, 'outputsize': 32}},
'embedding_di': {'densefeature': {'offeatures': 100, 'onlinefeatures': 200},
'onehot_featurename': ['good', 'l4', 'brand'],
'good': {'hash_size': 100000, 'emb_size': 32, 'copyfrom': 'g'},
'l4': {'hash_size': 100000, 'emb_size': 32, 'copyfrom': 'l'},
'brand': {'hash_size': 100000, 'emb_size': 32, 'copyfrom': 'b'},
'multihot_featurename': ['history_good', 'history_l4', 'history_brand'],
'history_good': {'spliter': '@', 'hash_size': 100000, 'emb_size': 32, 'copyfrom': 'g'},
'history_l4': {'spliter': '@', 'hash_size': 100000, 'emb_size': 32, 'copyfrom': 'l'},
'history_brand': {'spliter': '@', 'hash_size': 100000, 'emb_size': 32, 'copyfrom': 'b'}},
'attention_di': {'attentionlist': ['att1', 'att2', 'att3'],
'att1': ['histgds', 'general_gds_cd'],
'att2': ['histl4', 'l4_gds_group_cd'],
'att3': ['histbrd', 'brand_cd']}
}
def build_multihot_attention(self):
''基于din论文,平替tf.nn.embedding_lookup_sparse 的 sum 结合器 ''
self.input_multihotfeature = OrderedDict()
self.multihotfeature = OrderedDict()
attention_di = cluster_di['attention_di']
for att_name in attention_di['attentionlist']:
multi,one = attention_di[att_name] if attention_di[att_name] else ['','']
if not multi or not one: continue
placeholder = tf.placeholder(dtype=tf.string, shape=[None], name=multi)
self.input_multihotfeature[multi] = placeholder
str_splits = tf.string_split(placeholder, delimiter=cluster_di['embedding_di'][multi]['spliter'])
str_values = tf.string_to_number(str_splits.values,out_type = tf.int32)
str_sparse = tf.SparseTensor(str_splits.indices, str_values, str_splits.dense_shape)
''1-先转换成密度id,后缀自动以0补齐 ''
str_dense = tf.sparse_tensor_to_dense(str_sparse)
#[[1,2],[2,9,15]] 得到[[1,2,0],[2,9,15]]
# 基于str_dense将其扩充为embedding[[eb1,eb2,eb0],[eb2,eb9,eb15]]
embedding_mat = tf.nn.embedding_lookup(cluster_di['embedding_di'][multi], str_dense)
# 将embedding最后一维进行平铺形成二维矩阵
# 分别为batch column,lastsize,不能通过py的维度匹配
embedding_shape = tf.shape(embedding_mat)# [batch max emb_size]
one_mat = cluster_di['embedding_di']['onehot_featurename'][one]
one_shape = tf.shape(one_mat) #[batch emb_size]
emb_size = cluster_di['embedding_di'][multi]['emb_size'] # 主要解决din all的reshape最后一个值需要常量而不是tensor
''2-自动扩充one ''
# [[1,2,3],[4,5,6]] -> 2倍的话[[1,2,3,1,2,3],[4,5,6,4,5,6]]
one_mat = tf.tile(one_mat,[1,embedding_shape[1]])
''3-将multi和one都进行reshape成batch*feature ''
#
emb1 = tf.reshape(embedding_mat,[-1,emb_size])
# [[1,2,3],[1,2,3],[4,5,6],[4,5,6]]
one1 = tf.reshape(one_mat,[-1,one_shape[-1]])
''4-进行论文图2右上角那个小图形式 ''
# activation weight部分start
din_all = tf.concat([emb1, emb1*one1, one1], axis=1)
# 上面concat之后,这里需要注意reshape也对应乘以3才行
din_all = tf.reshape(din_all, [-1,emb_size*3])
d_layer_1_all = tf.layers.dense(din_all, 80, activation=prelu, name='f1_att', reuse=tf.AUTO_REUSE)
#d_layer_1_all = dice(d_layer_1_all, name='dice_1_f1')
d_layer_2_all = tf.layers.dense(d_layer_1_all, 40, activation=prelu, name='f2_att', reuse=tf.AUTO_REUSE)
#d_layer_2_all = dice(d_layer_2_all, name='dice_1_f2')
d_layer_3_all = tf.layers.dense(d_layer_2_all, 1, activation=None, name='f3_att', reuse=tf.AUTO_REUSE)
# activation weight部分end
''5-回到图2右边user behaviors上部分 ''
# 将权重进行embedding 维度复制,如[[0.1],[0.2]] ->[[0.1,0.1,0.1],[0.2,0.2,0.2]]
# 输出第二维是一个元素,batch为3倍(之前concat了3个),所以这里需要tile成完整的emb_size
weight = tf.tile(d_layer_3_all,[1,emb_size])
output = emb1*weight
''6-将所有的multi reshape后进行权重乘后,接下来就是进行mask计算了 ''
output = tf.reshape(output,embedding_shape)
paddings = tf.ones_like(output) * (0.0000000001)
str_dense1 = tf.expand_dims(str_dense,[-1])
str_dense1 = tf.tile(str_dense1,[1,1,embedding_shape[-1]])
cond1 = tf.cast(str_dense1,dtype = tf.bool)
# 通过where进行选择,使得之前因为扩展的部分都为0
mask_output = tf.where(cond1,output,paddings)
''7-通过reduce_sum将第二列进行sum pool操作 ''
mask_output = tf.reduce_sum(mask_output,1)
self.multihotfeature[multi] = mask_output
如上面代码,这里值得注意的一点是,因为每个样本中multihot中有效值(即为1的值)的个数是不固定的,有可能这个用户有2个历史商品,那个人有10个,如din图表示,则需要将这不固定数目的multihot与其中某个onehot进行计算注意力,然后最终加权并基于sum pooling完成合多为一。
所以就不能单独设定一个函数用来计算activation unit,通过将multihot中的个数,也就是din论文中good的个数转换成 batch中的个数,即代码第4部分。