一、os模块目录处理
需要导入: import os
import os # os 模块提供了非常丰富的方法用来处理文件和目录 1.用于返回当前工作目录 dir_name1 = os.getcwd() # 打印:H:Pycharm_Projectslemon_20homework print('dir_name1:', dir_name1) 2.获取操作系统名称 print(os.name) # 若是Windows系统会打印nt,若是linux/Unix会打印posix 3.在某个路径下创建一个新目录 # 相对路径, 相对当前py文件 os.mkdir("test1") # 使用绝对路径来创建文件 os.mkdir(r"H:Pycharm_Projectslemon_20homework\test2") 4.删除目录 os.rmdir("test1") 5.删除文件 os.remove('song1_new.mp3') 6.获取当前路径下的目录列表 print(os.listdir(r"H:Pycharm_Projectslemon_20homework")) # 第二种: print(os.listdir(".")) 7.打印当前模块所在目录的上级目录的目录列表 print(os.listdir("..")) 8.获取某个文件所在的目录路径 dir_name2 = os.path.dirname(r"homework est.py") dir_name3 = os.path.dirname(r"test.py") dir_name4 = os.path.dirname(r"sdafhjsdgasdjgldfgsdg431gsdhomework_0703.py") dir_name5 = os.path.dirname(r"sdafhjsdgasdjgldfgsdg431gsd est.py") print('dir_name2:', dir_name2) print('dir_name3:', dir_name3) print('dir_name4:', dir_name4) print('dir_name5:', dir_name5) 9.连接两个部分的路径,组成一个完整的路径 print(os.path.join(r'H:Pycharm_Projectslemon_20homework est.py', 'testcases')) 10.判断某个路径是否存在 result = os.path.exists(r"H:Pycharm_Projectslemon_20homeworkhua.py") print(result) 11.判断某个目录是否存在 result = os.path.isdir(r"H:Pycharm_Projectslemon_20homework est") print(result) 12.判断某个文件是否存在 result = os.path.isfile("homework_0703.py") print(result)
二、文件处理
1.概念
- 计算机中的文件,就是存储在某种长期储存设备上的一段数据
- 长期存储设备包括:硬盘、U盘、移动硬盘、光盘...
2.作用
- 将数据长期保存下来,在需要的时候使用
3.存储方式
- 在计算机中,文件是以二进制的方式保存在磁盘上的
4.分类
- 文本文件
- 可以使用文本编辑软件查看
- 本质上还是 二进制文件
- 例如: python 的源程序
- 二进制文件
- 保存的内容不是给人直接阅读的,而是提供给其他软件使用的
- 例如:图片文件、音频文件、视频文件等等
- 不能使用文本编辑软件查看
5.文件指针
- 文件指针标记从哪个位置开始读取数据
- 第一次打开文件时,通常文件指针会指向文件的开始位置
- 当执行了read方法后,文件指针会移动到读取内容的末尾
- 默认情况下会移动到文件末尾
6.打开制文件的方式
- 默认以 只读方式 打开文件,并且返回文件对象
语法:
f = open("文件名","访问方式")
- r:以 只读 方式打开文件。文件的指针将会放在文件的开头,这是默认模式。如果文件不存在,抛出异常
- w:以 只写 方式打开文件。如果文件存在会被覆盖。如果文件不存在,创建新文件
- a:以 追加 方式打开文件。如果该文件已存在,文件指针将会放在文件的结尾。如果文件不存在,创建新文件进行写入
- r+:以 读写 方式打开文件。文件的指针将会放在文件的开头。如果文件不存在,抛出异常
- w+:以 读写 方式打开文件。如果文件存在会被覆盖。如果文件不存在,创建新文件
- a+:以 读写 方式打开文件。如果该文件已存在,文件指针将会放在文件的结尾。如果文件不存在,创建新文件进行写入
- b :读写二进制文件(默认是t,表示文本),需要与上面几种模式搭配使用,如ab,wb, ab, ab+(POSIX系统,包括Linux都会忽略该字符)
注意:频繁的移动文件指针,会影响文件的读写效率,开发中更多的时候会以只读、只写的方式来操作文件
7.按行读取
- read:方法默认会把文件的所有内容-次性读取到内存
- 如果文件太大,对内存的占用会非常严重
- 使用readline方法
- readline方法可以一次读取一行内容
- 方法执行后,会把文件指针移动到下一行,准备再次读取
三、文件的读取与写入
1、文件操作的步骤:
- 1. 打开文件
- 2. 读写操作
- 3. 关闭文件
2、读取文件 read
使用read方法,会将文件中的所有内容读取出来, 以字符串类型呈现
# 1. 打开文件 one_file = open("test1.txt", encoding="utf-8") # 2. 读写操作 # 使用read方法, 会将文件中的所有内容读取出来, 以字符串类型呈现 content = one_file.read() print(content) # 3. 关闭文件 one_file.close()
3、写入文件 w
在写入文件的时候, 如果指定的文件名不存在, 那么会自动创建
在写入文件的时候, 如果指定的文件名存在, 那么会先清空原文件, 然后再写入
# 1. 打开文件 # 在写入文件的时候, 如果指定的文件名不存在, 那么会自动创建 # 在写入文件的时候, 如果指定的文件名存在, 那么会先清空原文件, 然后再写入 one_file = open("test2.txt", mode="w", encoding="utf-8") # 2. 写操作 one_file.write("生如花开") one_file.write("阿登") one_file.write("雪地里的蜗牛") # 3. 关闭文件 one_file.close()
4、追加写入 a
在追加文件的时候,,如果指定的文件名存在, 那么会在文件的尾部添加新的内容
在追加文件的时候,如果指定的文件名不存在, 那么会先创建文件, 然后再写入
# 1. 打开文件 # 在追加文件的时候, 如果指定的文件名存在, 那么会在文件的尾部添加新的内容 # 在追加文件的时候, 如果指定的文件名不存在, 那么会先创建文件, 然后再写入 one_file = open("test3.txt", mode="a", encoding="utf-8") # 2. 读写操作 # 文件原本第一次写入 # one_file.write("生如花开") # one_file.write("阿登") # one_file.write("雪地里的蜗牛") # 再次写入,以追加的形式 a one_file.write("100 200 300 ") # 3. 关闭文件 one_file.close()
5、每次只读取一行内容 readline、readlines
read(读取小文件用这个)、readline(读取大文件用这个)、readlines
- 使用read()方法, 会将文件中的所有内容读取出来, 以字符串类型呈现
- 使用readline()方法, 每调用一次, 会读取一行的内容,以字符串类型呈现, 读到文件尾部之后, 会读取空格
- 使用readlines()方法, 会把每一行数据读取出来, 放在一个列表中
# 1. 打开文件 one_file = open("test1.txt", encoding="utf-8") # 2. 读写操作 # 使用readline方法, 每调用一次, 会读取一行的内容, 读到文件尾部之后, 会读取空格 # content = one_file.readline() # 读取第一行内容 # content1 = one_file.readline() # 读取第二行内容 # print(content) # print(content1) # readlines方法, 会把每一行数据读取出来, 放在一个列表中 content3 = one_file.readlines() print(content3) # 读取全部内容,放到一个列表中 print(content3[2]) # 以索引的方式,读取列表中 指定数据 # 3. 关闭文件 one_file.close()
6、读取图片(二进制文件):读取图片并写入到新的文件
# 1. 打开文件 # open("图片所在路径", mode="rb") one_file = open("keyou_2.png", mode="rb") # r:读 b:二进制文件 two_file = open("keyou.png", mode="wb") # w:写 b:二进制文件 # 2. 读写操作 content = one_file.read() # 读取图片二进制数据 two_file.write(content) # 将读取的二进制数据, 写入到第二个文件中 # 3. 关闭文件 one_file.close() two_file.close()
四、练习题:
1. __name__变量有什么特性?
- 运行当前模块,值为 __main__
- 作为模块导出,值为 模块名
2.os模块中有哪些常用的方法?用什么作用?
详细看上面最上面
- os.getcwd() :# getcwd()方法显示当前的工作路径,只具体到路径,不具体到文件。
- os.path.join(a,b) :# 连接两个部分的路径,组成一个完整的路径
- os.mkdir(路径名字) :# 在某个目录下创建一个新目录
- os.rmdir(路径名字) :# 删掉一个目录
- os.listdir() :# 获取当前路径下的目录列表
- os.path.isdir :# 判断当前文件是否是目录,返回布尔值
- os.path.isfile :# 判断当前文件是否是文件,返回布尔值
3.文件有哪些种类?
- 文本文件
- 二进制文件
4.文件的操作步骤
- 打开文件
- 读写文件
- 关闭文件
5.操作文件的常用函数/方法有哪些?
- open:负责打开文件,并且返回文件对象
- read:将文件内容读取到内存
- write:将指定内容写入文件
- close: 关闭文件
6.read、readline、readlines有什么区别?
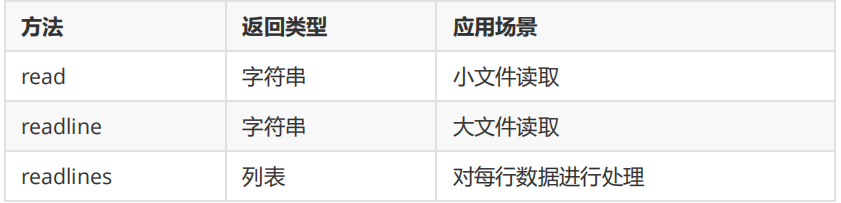
- 使用read()方法,会将文件中的所有内容读取出来, 以字符串类型呈现
- 使用readline()方法,每调用一次, 会读取一行的内容,以字符串类型呈现,读到文件尾部之后,会读取空格
- 使用readlines()方法,会把每一行数据读取出来,放在一个列表中
7. 打开文件的方式有哪些?
默认以 只读方式 打开文件,并且返回文件对象
语法:f = open("文件名",("访问方式"))
- r 以只读模式打开文件,并将文件指针指向文件头;如果文件不存在会报错
- w 以只写模式打开文76件,并将文件指针指向文件头;如果文件存在则将其内容清空,如果文件不存在则创建
- a 以只追加可写模式打开文件,并将文件指针指向文件尾部;如果文件不存在则创建
- r+ 在r的基础上增加了可写功能
- w+ 在w的基础上增加了可读功能
- a+ 在a的基础上增加了可读功能
- b 读写二进制文件(默认是t,表示文本),需要与上面几种模式搭配使用,如ab,wb, ab, ab+(POSIX系统,包括Linux都会忽略该字符
8.编写如下程序,将你喜欢的一首歌(音乐文件拓展名为mp3,比如刘德华忘情水.mp3),通过文件读写的方法将其复制并修改文件名
# 方式一: # 1. 打开文件 src_file = open("keyou_2.png", mode="rb") # r:读 b:二进制文件 des_file = open("keyou.png", mode="wb") # w:写 b:二进制文件 # 2. 读写操作 content = src_file.read() # 读取图片二进制数据 des_file.write(content) # 将读取的二进制数据, 写入到第二个文件中 # 3. 关闭文件 src_file.close() des_file.close() # 方式二 # 1. 打开文件 src_file = open("keyou_2.png", mode="rb") # r:读 b:二进制文件 des_file = open("keyou.png", mode="wb") # w:写 b:二进制文件 # 2. 读写操作 while True: part_content = src_file.read(1024) # 当读取到末尾结束 if not part_content: break des_file.write(part_content) # 3. 关闭文件 src_file.close() des_file.close() # 方式三 # 1. 打开文件 with open("mp3", "rd") as src_file, open("mp3", "wd") as des_file: # 处理文件 while True: part_content = src_file.read(1024) # 当读取到末尾结束 if not part_content: break des_file.write(part_content) # 2. 关闭文件 src_file.close() des_file.close()
9.编写如下程序,有两行数据,存放在txt文件里面:
- url:http://test.lemonban.com/futureloan/mvc/api/member/register@mobile:18866668888@pwd:123456
- url:http://test.lemonban.com/futureloan/mvc/api/member/recharge@mobile:18866668888@amount:1000
- 请利用所学知识,读取txt文件里面的两行内容,然后转化为如下格式(嵌套字典的列表):(可定义函数)
- [{'url':'http://test.lemonban.com/futureloan/mvc/api/member/register','mobile':'18866668888','pwd':'123456'},{'url':'http://test.lemonban.com/futureloan/mvc/api/member/recharge','mobile':'18866668888','amount':'1000'}]
def handle_data(one_list): """ 将字符串切割之后,转换为字典 :param one_list:[str] :return:字典 """ full_result_list = [] # 用于存储最终结果 tmp_result_list = [] # 用于存储临时结果 for item in one_list: # 第一次以@来分隔 # ['url:http://test.lemonban.com/futureloan/mvc/api/member/register','mobile:18866668888', 'pwd:123456'] tmp_list = item.split("@") for val in tmp_list: # 第二次以:来分隔,只分隔一次 # [['url','http://test.lemonban.com/futureloan/mvc/api/member/register'], # ['mobile', '18866668888'], ['pwd', '123456']] tmp_result_list.append(val.split(":", 1)) full_result_list.append(dict(tmp_result_list)) # 将嵌套列表的列表转化为字典,然后添加到full_result_list中 return full_result_list def read_file_lines(file_path, mode='r', encoding='utf-8'): """ 读取文件 :param file_path: 文件路径 :param mode: 文件打开模式 :param encoding: 文件编码 :return: [str] """ # 打开文件 one_file = open(file_path, mode=mode, encoding=encoding) # 读取文件 file_lines_list = one_file.readlines() for key, value in enumerate(file_lines_list): # 将列表中每一行末尾的 去除 file_lines_list[key] = value[:-1] # 关闭文件 one_file.close() return file_lines_list def main(): """ 启动函数 :return: """ completed_data = handle_data(read_file_lines("urlshujv.txt")) print("最终处理的数据为: {}".format(completed_data)) if __name__ == '__main__': main()
11.编写如下程序
创建一个txt文本文件,以csv格式(数据之间以英文逗号分隔)来添加数据
- a.第一行添加如下内容:
- name,age,gender,hobby,motto
- b.从第二行开始,每行添加具体信息,例如:
- 可优,17,男,臭美,Always Be Coding!
- 柠檬小姐姐,16,女,可优,Lemon is best!
- c.具体用户信息要求来自于一个嵌套字典的列表(请自定义这个列表),例如:
person_info = [{"name": "可优",
"age": 17,
"gender": "男",
"hobby": "臭美",
"motto": "Always Be Coding!"},
{"name": "柠檬小姐姐",
"age": 16,
"gender": "女",
"hobby": "可优",
"motto": "Lemon is best!"},
]
- d.将所有用户信息写入到txt文件中之后,然后再读出
- e.有精力的同学可以试试,多种方法来读取文件,比如csv模块(不作要求)
- 注意:csv格式的数据,是以英文逗号分隔的
# 构造数据 person_info = [{"name": "可优", "age": 17, "gender": "男", "hobby": "臭美", "motto": "Always Be Coding!"}, {"name": "柠檬小姐姐", "age": 16, "gender": "女", "hobby": "可优", "motto": "Lemon is best!"}, ] def handle_data(one_list): """ 处理数据 :param one_list: 嵌套字典的列表 :return:字符串 """ datas_str = "" for item in one_list: # 将字典的所有值转化为列表之后,使用逗号拼接 tmp_list = [] for i in item.values(): tmp_list.append(str(i)) datas_str = datas_str + ','.join(tmp_list) + " " return datas_str def write_file(file_path, data, mode='a', encoding='utf-8'): """ 写数据到文件 :param file_path: 文件路径 :param data: 添加的数据 :param mode: 文件打开模式 :param encoding: 文件编码 :return: """ # 打开文件 one_file = open(file_path, mode=mode, encoding=encoding) # 添加内容到文件 one_file.write(data) # 关闭文件 one_file.close() def main(): # 文件路径 file_path = 'result_datas.txt' first_line = 'name,age,gender,hobby,motto ' # 写入第一行内容 write_file(file_path, first_line) # 写入其他数据 write_datas = handle_data(person_info) # 将嵌套字典的列表数据转化为字 符串 write_file(file_path, write_datas) # 读取数据 with open(file_path, encoding="utf-8") as one_file: contents = one_file.read() print("最终文件内容为: {}".format(contents)) if __name__ == '__main__': main()
方法二:
import csv # 构造数据 person_info = [{"name": "可优", "age": 17, "gender": "男", "hobby": "臭美", "motto": "Always Be Coding!"}, {"name": "柠檬小姐姐", "age": 16, "gender": "女", "hobby": "可优", "motto": "Lemon is best!"}, ] def write_from_dict(file_path, fieldnames, datas): """ 将来自于字典的数据写入csv文件中 :param file_path: 文件路径 :param fieldnames: 列名所在列表 :param datas:嵌套字典的列表 :return: """ with open(file_path, mode='w', encoding='utf-8', newline='') as csv_file: writer = csv.DictWriter(csv_file, fieldnames=fieldnames) # 将列名写在首行 writer.writeheader() # 将数据写在其他行 # for item in datas: # writer.writerow(item) writer.writerows(datas) def read_from_csv(file_path): """ 将csv文件中的数据读出 :param file_path: csv文件路径 :return: """ with open(file_path, mode='r', encoding='utf-8') as csv_file: # reader = csv.DictReader(csv_file) reader = csv.reader(csv_file) for row in reader: if row: print("{},{},{},{},{}".format(*row)) def main(): """ 程序入口函数 : return: """ # 文件路径 file_path = 'result_datas1.txt' field_names = ['name', 'age', 'gender', 'hobby', 'motto'] write_from_dict(file_path, field_names, person_info) read_from_csv(file_path) if __name__ == '__main__': main()
*******请大家尊重原创,如要转载,请注明出处:转载自:https://www.cnblogs.com/shouhu/,谢谢!!*******