写在前面
数据同步 是一个脏活,而且是个高风险的活
大多数情况下,应用架构设计不好,引入什么新存储,引入什么DDD,治标不治本,都是扯淡。
但万一灵验呢?这就是数据同步的需求基础。且看下面需求场景。
应用场景
-
业务数据发展到一定水平,需要将大部分冷热数据从熟悉的DB迁移到其他存储进行复杂查询和分析
-
分库分表后,某些报表类查询无法工作,需要汇总到单库表进行操作
-
分库分表有多个维度,需要拷贝多份数据达成冗余
-
通过伪数据共享(没办法引入MQ、无法共享库表)进行业务改造
-
慢存储→Cache之间的同步
-
不停服数据迁移/scheme变更
-
导数据导数据
-
归档
很多时候,DataBus提供的仅仅是一个工具集。要完成最终的功能,大多数需要引入其他组件,如MQ、JOB等进行配合。同时,大部分数据同步工具需要有规范的数据库支持。所以,在忙着进行数据同步之前,需要对遗留数据进行一次集中数据治理。
一般数据同步,可以 应用驱动 双写:应用层同时向数据库或者多个存储写数据。因为代码在自己手中,这种方式在直觉上是简单可控的。但它引入的一致性问题将会是非常大的减分,因为没有复杂的协调协议(比如两阶段提交协议或者paxos算法),当出现问题时,很难保证多个存储处于相同的锁定状态。两个系统需要精确完成同样的写操作,并以同样的顺序完成序列化。如果写操作是有条件的或是有部分更新的语义,那么事情就会变得更麻烦。
基于 数据库日志 :将数据库作为唯一真实数据来源,并将变更从事务或提交日志中提取出来。这可以解决一致性问题,但是很难实现,MySQL这样的数据库有私有的交易日志格式和复制冗余解决方案,难以保证版本升级之后的可用性。由于要解决的是处理应用代码发起的数据变更,然后写入到另一个数据库中,冗余系统就得是用户层面的,而且要与来源无关。对于快速变化的技术公司,这种与数据来源的独立性非常重要,可以避免应用栈的技术锁定,或是绑死在二进制格式上。
数据同步方式
目前的数据同步解决方案,大体有以下三种:
-
针对特定AB方数据同步进行的私有定制,如trigger
-
binlog、wal日志级别的精确数据同步
-
基于lastUpdateTime的查询结果集数据同步
针对于数据同步方式,有增量和全量同步两种:
-
全量 一次性导出倒入完毕
-
增量 数据随到随倒,小溪汇大海~
数据同步考虑的因素
基本特性
-
同机房同步实时性(RTT)
-
增量同步/全量同步策略
-
事务支持粒度
-
峰值应对策略 (消峰降级、延迟写入、扩容策略)
多机房(X一般公司不到这水平)
-
数据库异地灾备
-
多机房同步延迟
-
机房切换(单元化切流/全站切流)
-
数据对其方案
-
双活
AB端数量和质量
-
支持常见的SQL,如MySQL、Postgres
-
其他AB端支持,如:Redis、Mongo、ES
-
数据同步的
-
扩展方式和社区活跃度
高吞吐、低延迟
-
并行化(并行读、并行写)
-
顺序场景串行化
高可用
-
监控、故障恢复
-
A(源端)端故障感知
-
B (目的端)端故障感知
-
主从切换(或为对等节点)
-
支持服务演练
-
动态配置、故障重启
数据完整性
-
较高的SLA高可用服务水准
-
故障数据有回放机制和降级策略
-
A/B端数据自动校验功能(一致性验证)
其他
-
数据过滤机制
-
学习、部署成本
-
硬件成本
实现
我们从几个典型实现、来看一下数据同步的复杂性。阿里在数据同步上可谓吓足了功夫,如:datax(ETL工具)、canal、otter、drc、dts、drds愚公精卫等。其中,使用最广泛的就是canal和datax。
另外,还有一些其他较活跃的工具,如sqoop、Maxwell 、debezium等
基于数据库的组件,一般都是伪装成一个DB的从库接收一份数据,剩下的都是框架内玩的事情了。如MySQL一般使用基于row的binlog、postgres基于wal日志进行复制。以MySQL为例、如果通过Binlog方式,将数据同步到ES、Hbase等其他盲区,就需要手写大量代码,包括组装数据、批量、顺序、HA等等很多场景都需要考虑。
我们限定一下一个最简单的使用场景,然后追踪在其上需要哪些工作量,又有哪些优缺点。场景如下:
将MySQL数据库的数据,同步一份数据到Postgres
Canal
最新的Canal已经支持MQ
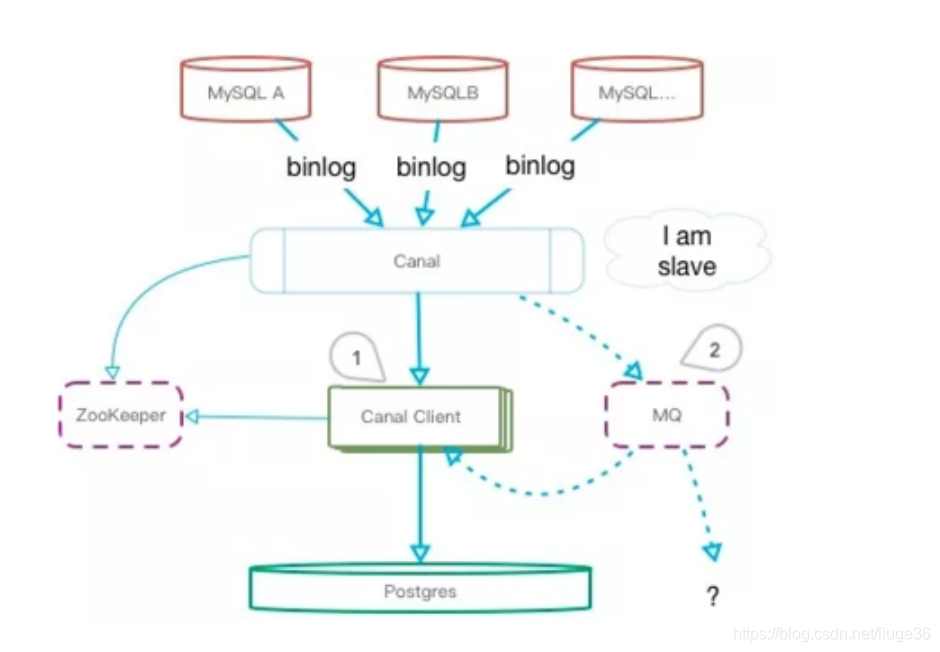
如上图,除了需要搭建canal服务,将其伪装成一个slave,然后通过zookeeper做HA。我们还需要编码一个Canal Client服务,用来读取和解析数据。更多的情况,可能要引进一个MQ组件,用来缓解Canal的压力并承担一些扩展性功能。
一些限制
-
Canal源端只支持MySQL,并且只支持基于ROW模式的同步复制
-
同步的表必须要有主键,无主键表update会是一个全表扫描 ,如果出现重复记录的话,同步会导致数据错乱
-
支持部分ddl同步,ddl语句不支持幂等性操作,所以出现重复同步时,会导致同步挂起,可通过配置高级参数:跳过ddl异常,来解决这个问题(支持create table / drop table / alter table / truncate table / rename table / create index / drop index,其他类型的暂不支持,比如grant,create user,trigger等等)
-
不支持带外键的记录同步
-
数据库慎用或者禁用trigger
-
Canal是吃内存的,注意内存相关的调优
-
堆积能力有限,这也是外部MQ的优势
maxwell
maxwell干脆就将这个过程更近了一步:直接将binlog解析成json存储在kafka中。用户使用的时候,直接订阅kafka的topic即可。
数据可能长这样:
mysql> update test.maxwell set daemon = 'firebus! firebus!' where id = 1;
maxwell: {
"database": "test",
"table": "maxwell",
"type": "update",
"ts": 1449786341,
"xid": 940786,
"commit": true,
"data": {"id":1, "daemon": "Firebus! Firebus!"},
"old": {"daemon": "Stanislaw Lem"}
}
maxwell为用户提供了默认的解决方式,需要额外引入kafka组件,这也是大部分数据分发共享的思路。由其github star数看来,要小canal一个数量级。在此基础上,有类似bireme更专某个场景的产品,不过都偏小众。
debezium
我觉得有必要提一下debezium。随着postgres的性能和特性越来越强,国内采用PG的公司逐渐增多。像这种场景,canal就无能为力了,debezium同时支持源端MySQL和Postgres、MongoDB,值得一试。同maxwell类似,同样需要kafka的支持。
缺点也是显而易见的,文档的质量不高,实践资料太少。
DataBus
Linkedin开源作品。Databus支持多种数据来源的变更抓取,包括Oracle和MySQL。是一个低延迟、可靠的、支持事务的、保持一致性的数据变更抓取系统。
大同小异,databus在MySQL的处理方式上,也是通过解析binlog的方式进行数据抓取。使用MySQL Binlog解析库,我们也可以构造一个自己的数据同步中间件。DataBus做了更多的缓冲区relay、事件优化和回溯处理。在整个技术架构中,可以充当数据总线的作用。
DataX
与Databus类似,DataX是一个在异构的数据库/文件系统之间高速交换数据的工具,实现了在任意的数据处理系统之间的数据交换,更像是一个ETL工具。
DataX支持的AB端数据源非常丰富,但因为它使用的定时抓取的方式,其延迟相比较Canal等基于日志的方式,是比较大的。同时,DataX对数据的要求较高,比如你的数据库如果没有最后更新时间之类的字段,从源端读取变更数据将有一定的困难。
总结
整体而言,Canal、DataX、DataBus的使用人数多,社区活跃,框架也比较成熟。在满足应用场景的前提下,优先选择,它们都有自己的HA方案,代价适中。
Canal、DataBus源端支持类型有限,但延迟低,需要手写Client来处理数据。大多数情况下需要加入MQ进行配合。
DataX支持丰富,使用简单,但延迟较大(依赖获取频率),只需要手写规则文件,对复杂同步自定义性不强。
文章地址:https://www.imooc.com/article/295278