使用selenium 多线程爬取爱奇艺电影信息
转载请注明出处。
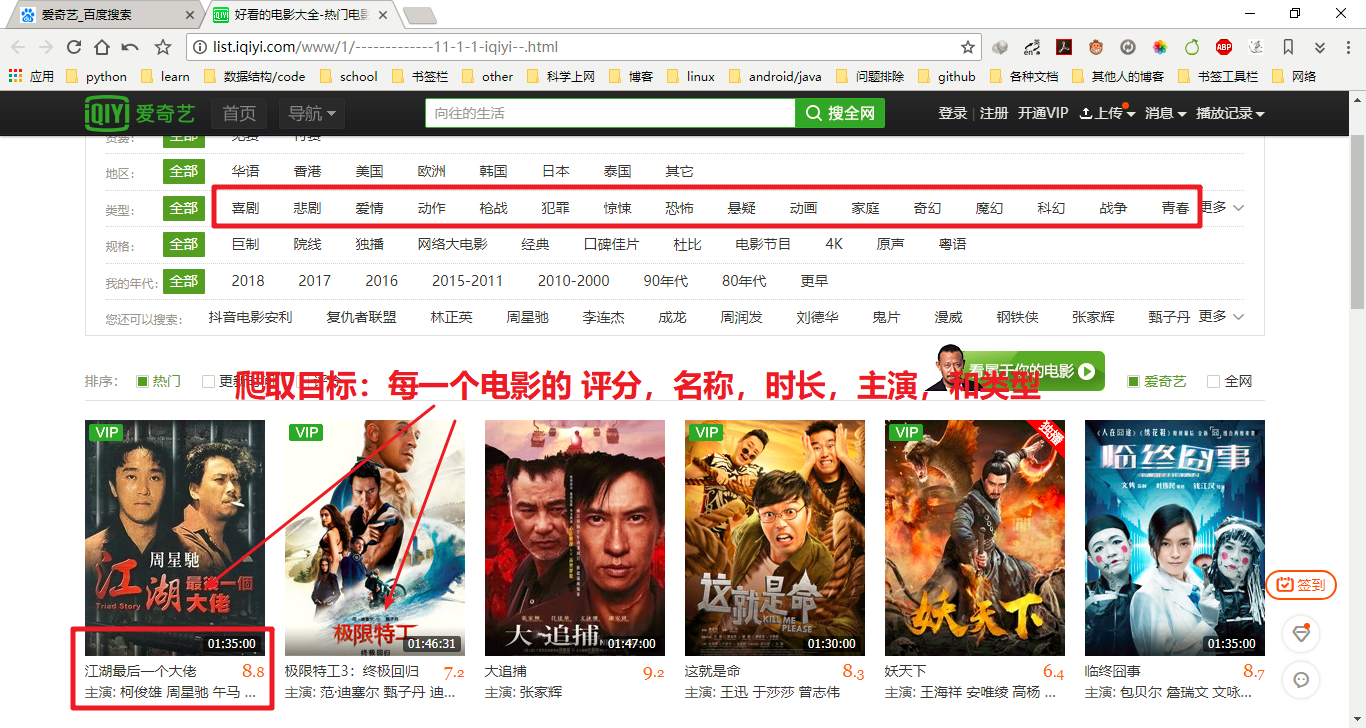
爬取目标:每个电影的评分、名称、时长、主演、和类型
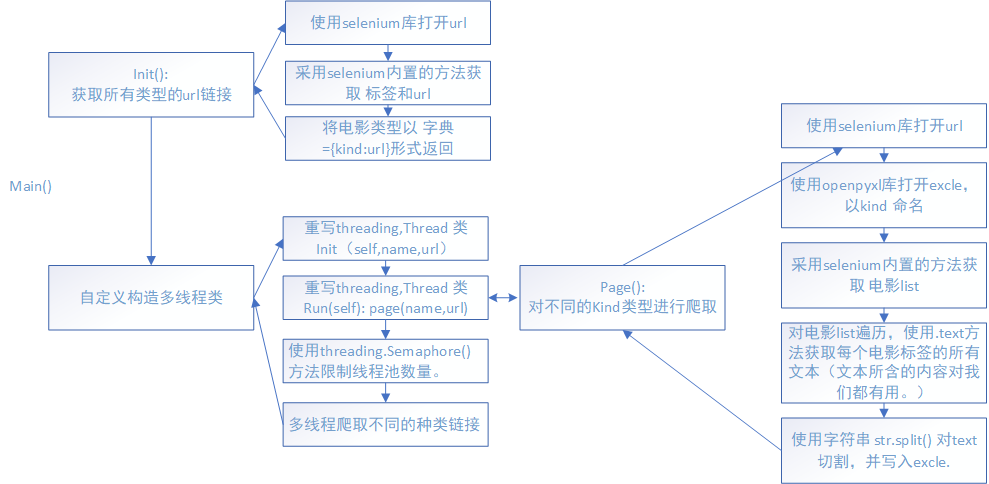
爬取思路:
源文件:(有注释)
from selenium import webdriver
from threading import Thread
import threading
import time
import openpyxl #操作excel
#爱奇艺的看电影的url 不是首页。
url='http://list.iqiyi.com/www/1/-8------------11-1-1-iqiyi--.html'
#自定义一个线程类 实现多线程爬取
class M_Thread(Thread):
def __init__(self,name1,url):
Thread.__init__(self)
self.url=url
self.name1=name1
def run(self):
self.kind_movie=page(self.name1,self.url)
#page运行完后lock进行 让 当前movie 结束
# 初始化爬虫,从url中爬爬取各个种类相对于的连接。
def init():
# 浏览器 无界面 和有界面。
fireFoxOptions = webdriver.FirefoxOptions()
fireFoxOptions.set_headless()
Brower = webdriver.Firefox(firefox_options=fireFoxOptions)
# Brower = webdriver.Firefox()
Brower.get(url)
#定位到种类标签 (发现不用Xpath容易出错)
kind=Brower.find_element_by_xpath("/html/body/div[3]/div/div/div[1]/div[4]/ul")
#a标签就是那个 连接
kinds=kind.find_elements_by_tag_name("a")
#将每个类型的页面连接储存到kinds_dict中
movie_kind_link={}
for a in kinds:
try:
if(a.text=="全部" or a.text==""): #去掉 全部类型 和一个空类型。
continue
movie_kind_link[a.text] = a.get_attribute("href")
except:
print("error!")
continue
Brower.close()
return movie_kind_link #返回的是 种类:url 字典。
def page(name,link):
#每一个种类 都打开一个excle储存
wordbook=openpyxl.Workbook()
sheet1=wordbook.active
num=1
#初始化excle第一行
for qwe in ["电影名","时长","评分","类型","演员"]:
sheet1.cell(row=1,column=num,value=qwe)
num+=1
num=2
#本来一开始是用txt写的但是布局太丑。 优点是速度快!
# 采用过 用数据库存 ,但是同时写入大量数据 总是会出莫名奇妙的错误。暂时没解决
# file=open(name+".txt","w",encoding="utf-8")
fireFoxOptions = webdriver.FirefoxOptions()
fireFoxOptions.set_headless()
Br = webdriver.Firefox(firefox_options=fireFoxOptions)
# Br = webdriver.Firefox()
# try:
Br.get(link)
print("正在打开 %s 页面"%name)
page = Br.find_element_by_class_name("mod-page")
page_href=[]
for aa in page.find_elements_by_tag_name("a"):
page_href.append(aa.get_attribute("href"))
for cc in page_href:
print("*****正在爬取 {} 的第 {} 页*****".format(name,page_href.index(cc)+1))
# time.sleep(1)
# 第一页不用重新打开
if(page_href.index(cc)!=0):
Br.get(cc)
#movie 即当前页面的 电影tag 列表
movie=Br.find_element_by_class_name("wrapper-piclist").find_elements_by_tag_name("li")
for bb in movie:
# try:
things=bb.text.split("
")
"""
这里为什么要区分?
爱奇艺很垃圾,有点电影评分不给,
但是在直接获取text在if判断和分元素去获取四个属性,我觉得还是if好用。
"""
if(len(things)==4):
sheet1.cell(row=num, column=1, value=things[2])
sheet1.cell(row=num, column=2, value=things[0])
sheet1.cell(row=num, column=3, value=things[1])
sheet1.cell(row=num, column=4, value=name)
sheet1.cell(row=num, column=5, value=things[3])
num+=1
elif (len(things) == 3):
sheet1.cell(row=num, column=1, value=things[1])
sheet1.cell(row=num, column=2, value="*")
sheet1.cell(row=num, column=3, value=things[0])
sheet1.cell(row=num, column=4, value=name)
sheet1.cell(row=num, column=5, value=things[2])
num +=1
else:
print("error (moive)")
# break
Lock_thread.release() # 解锁
wordbook.save(name+".xlsx")
Br.close()
if __name__=="__main__":
#控制线程最大数量为3
Lock_thread= threading.Semaphore(3) #控制线程数为3
#kind:link
dict=init()
# print(dict)
#多线程爬取
for name1,link in dict.items():
Lock_thread.acquire() #枷锁 ,在每一个page()运行完后解锁
thread_live=M_Thread(name1,link)
print(name1," begin")
thread_live.start()
time.sleep(3)