序言
好好努力。
---WH
一、Iterator和ListIterator的区别是什么?
自我解答:
Iterator是针对所有collection来使用的,而看名字ListIterator,顾名思义,就是给list集合特有的,增加了其他专有的方法吧。
参考答案:
下面列出了他们的区别:
Iterator可用来遍历Set和List集合,但是ListIterator只能用来遍历List。
Iterator对集合只能是前向遍历,ListIterator既可以前向也可以后向。
ListIterator继承了Iterator接口,并包含其他的功能,比如:增加元素,替换元素,获取前一个和后一个元素的索引,等等。
自我评价:
首先第一映像,我只看过Iterator,第二个ListIterator我是没听过的,但是通过这么久的学习,我可以看出,ListIterator就是只能给list集合用,而不是给其他集合,
1、Iterator:是接口,能给所有的集合使用
2、ListIterator:也是接口,继承了Iterator接口,同时肯定对Iterator接口中的方法进行了增强
·ListIterator只能对list集合迭代,
·ListIterator不仅能向后迭代,也能想前迭代
·ListIterator还能增加元素和删除元素,并且还能获得前一个元素和后一个元素
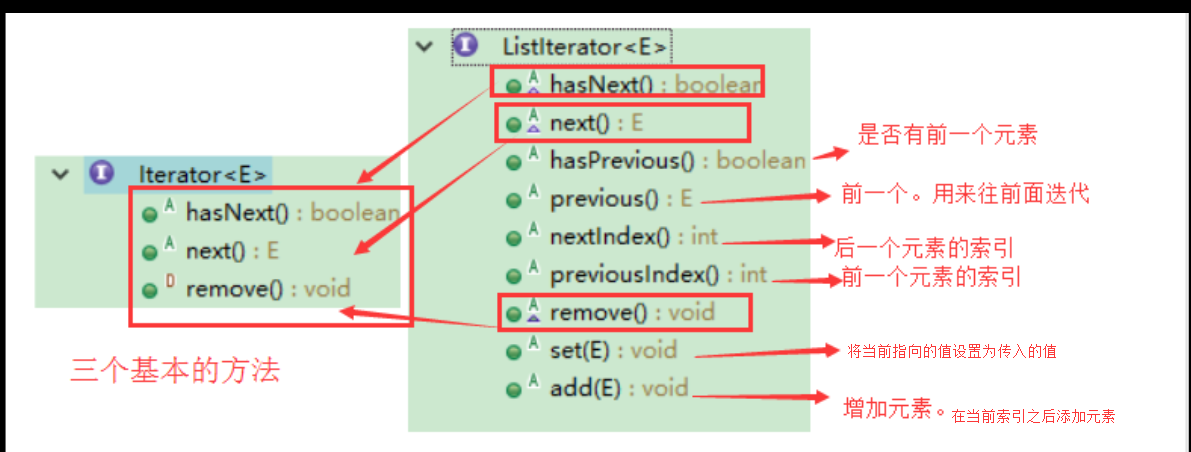
注意:使用Iterator迭代的时候需要注意几个问题
1、xx.next(); 每次使用这个,就会往后面推一位,也就是索引会往后移一位,
2、xx.hasNext(); 当检测到后面没有值了,返回false,但是指向器还是会往后面移一位。指向最后一位的后一位,这也是在ListIterator发现的,使用Iterator没有这个考虑,无所谓,因为只有ListIterator才有往前迭代的方法,所以才有前面这一大堆话。
3、ListIterator使用xx.add();在当前索引的后面增加,不是替代当前索引的值
4、ListIterator使用xx.set(E);将当前索引的值给替换成我们给定的值
二、快速失败(fail-fast)和安全失败(fail-safe)的区别是什么?
自我解答:
这个没接触过。。。
参考答案:
Iterator的安全失败是基于对底层集合做拷贝,因此,它不受源集合上修改的影响。
java.util包下面的所有的集合类都是快速失败的,快速失败的迭代器会抛出ConcurrentModificationException异常
java.util.concurrent包下面的所有的类都是安全失败的。,而安全失败的迭代器永远不会抛出这样的异常。
自我评价:
先说一下,这个题目花了我两个多小时,才彻底弄明白,但是还是很有效果的,比如,我查看了Iterator实现的源码,和之前看ArrayList源码时不懂得地方都弄清楚了,Iterator实现的原理和ArrayList源码分析我会在别的文章中写出来,到时候可以看看。现在来解决这个问题
1、fail-fast 和 fail-safe 这两个针对的是Iterator,
2、fail-fast:快速失败,在那些不是线程安全的集合使用Iterator时发生的问题,因为在迭代的时候,有别的线程对集合内部的构造进行了改变,比如,add、delete这类操作,都会使之发生快速失败。
3、fail-safe:安全失败,在线程安全的集合中发生上面的问题,就会出现该fail-safe了。
因为我明白了其中到底发生了什么,所以,写上面的文字,我知道意思,可能大家有点不理解,可以先了解一下fail-fast是什么,推荐博文:http://blog.csdn.net/chenssy/article/details/38151189 这里面就详细讲解了fail-fast是什么, 建议先观看arrayList源码,在其中重点了解Iterator的实现,还有modCount是什么,知道了这些,结合这篇博文和我说的,差不多就了解啦。
3、Java中的HashMap的工作原理是什么?
自我解答:
使用数组存储键值数据,每个数组中的位置又是一个链表。
参考答案:
HashMap的底层是用hash数组和单向链表实现的 ,当调用put方法是,首先计算key的hashcode,定位到合适的数组索引,然后再在该索引上的单向链表进行循环遍历用equals比较key是否存在,如果存在则用新的value覆盖原值,如果没有则在链头保存该值。HashMap的两个重要属性是容量capacity和加载因子loadfactor,默认值分布为16和0.75,当容器中的元素个数大于 capacity*loadfactor时,容器会进行扩容resize 为2n,在初始化Hashmap时可以对着两个值进行修改,负载因子0.75被证明为是性能比较好的取值,通常不会修改,那么只有初始容量capacity会导致频繁的扩容行为,这是非常耗费资源的操作,所以,如果事先能估算出容器所要存储的元素数量,最好在初始化时修改默认容量capacity,以防止频繁的resize操作影响性能。
自我评价:
1、没搞清楚hashMap的存储结构,虽然看了源码,但还是模模糊糊,现在差不多知道了
2、hashMap是用hash表和单向链表来实现存储数据的,具体模型如下,并且在hashmap中有一个内部类entry,它有四个属性V、K、next、hash,我们放入的key和value会分别放入entry的K、V中,所以存放的都市entry对象。

3、首先将key通过hash算法算出hashcode值,
4、通过hashcode值找到在hash数组中对应的位置,然后通过equals方法,遍历单向链表,看有没有相同的key值,如果有,则替换key所对应的value值,如果没有,将该数据插入链表的开始。
四、hashCode()和equals()方法的重要性体现在什么地方?
自我解答:
这个问题可以看我那边hashcode详解的文章,因为有hashCode()和equals()两个方法,使对数据的查询的效率变得很高,比如set集合中,就用到了这两个方法,不可以存放相同的值,这里就得到了体现
参考答案:
Java中的HashMap使用hashCode()和equals()方法来确定键值对的索引,当根据键获取值的时候也会用到这两个方法。如果没有正确的实现这两个方法,两个不同的键可能会有相同的hash值,因此,可能会被集合认为是相等的。而且,这两个方法也用来发现重复元素。所以这两个方法的实现对HashMap的精确性和正确性是至关重要的。
自我评价:
差不多就是这样,就解释一下大概的情况,举个例子,差不多了。
五、HashMap和Hashtable有什么区别?
自我解答:
hashMap是Hashtable的父类,hashtable是线程安全的,而hashmap不是。
参考答案:
HashMap和Hashtable都实现了Map接口,因此很多特性非常相似。但是,他们有以下不同点:
HashMap允许键和值是null,而Hashtable不允许键或者值是null。
Hashtable是同步的,而HashMap不是。因此,HashMap更适合于单线程环境,而Hashtable适合于多线程环境。
HashMap提供了可供应用迭代的键的集合,因此,HashMap是快速失败的。另一方面,Hashtable提供了对键的列举(Enumeration)。
一般认为Hashtable是一个遗留的类。
自我评价:
map的各种继承关系模糊了,
1、hashMap的子类是linkedHashMap
2、hashTable和hashMap的关系就好像arrayList和Vector的关系差不多
3、hashTable是同步的,而hashMap是异步的,也就是一个线程安全一个线程不安全
4、hashMap的key值可以为null 而hashTable不可以
5、具体的可以去看collections集合的那篇总结文章