循环神经网络
绪论
-
全连接网络->卷积神经网络
- 全连接网络处理图像问题时,参数太多,容易出现过拟合现象。
- 卷积神经网络使用“局部关联,参数共享”的方法
-
卷积、特征图feature map、padding、深度channel以及池化概念
-
eg
- 输入为7x7x3的图像,则卷积核的大小应为nxnx3(此处为3x3x3),即一个卷积核里面有三个矩阵,分别与输入的三个channel做运算,每一个矩阵运算得到一个结果,然后将这些结果求加和,再加上偏置项,得到feature map中的值。然后根据步长继续进行计算,最终得到完整的feature map(3x3)
- 一个卷积核对应一个feature map,如果有m个卷积核,那么输出就会有m个feature map(3x3xm)

-
卷积神经网络->循环神经网络
- 传统神经网络、卷积神经网络,输入和输出之间是相互独立的
- RNN可以更好的处理具有时序关系的任务
- RNN通过其循环结构引入“记忆”的概念
基本组成结构
-
基本结构
-
传统结构对于一些问题,只能处理当前输入,不能够结合之前的输入信息进行处理,所以神经网络需要“记忆”
-
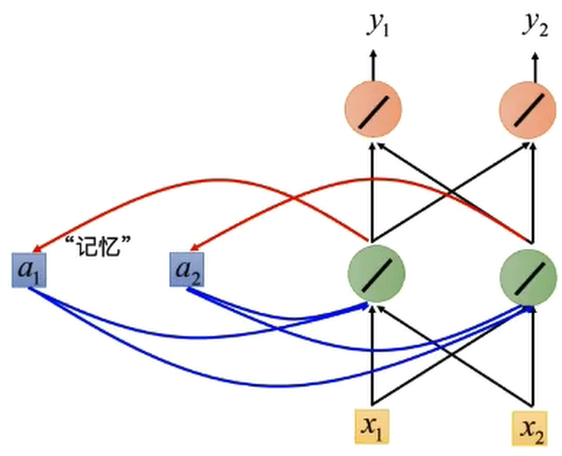
-
两种输入:正常输入,记忆单元的输入;
-
两种输出:正常输出,输出到记忆单元中;
-
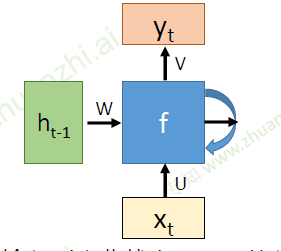
- U:从输入到隐藏状态的参数;W:从前一隐藏状态到下一个隐藏状态的参数;V:从隐藏状态到输出的参数;
- (x_t)是时间t处的输入
- (h_t)是时间t处的记忆,(h_t = f(h_{t-1},x)),f可以是双曲正切(tanh)等
- (h_t = tanh(Wh_{t-1}+Ux))
- (y_t)是时间t时刻的输出,(y_t = softmax(Vh_t))
- 函数f被不断利用;模型所需要学习的参数是固定的;这样的话就可以避免因为输入长度的不同而训练不同的网络。
-
-
深度RNN
-
双向RNN
-
BPTT算法
-
BP算法
-

-
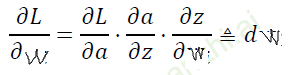
-
使用sigmoid函数时,可能在链式求导中的某一项为零,则整个求导为零,出现梯度消失
-
-
RNN的基本公式
- (h_t = tanh(Wh_{t-1}+Ux))
- (y_t = softmax(Vh_t))
-
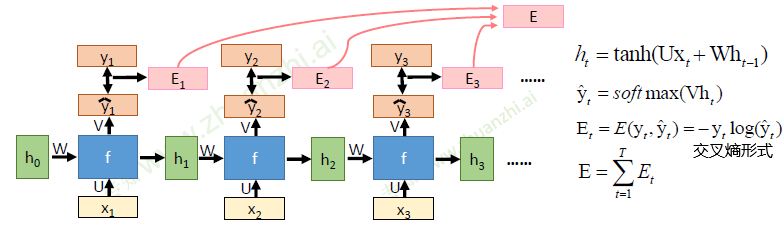
-
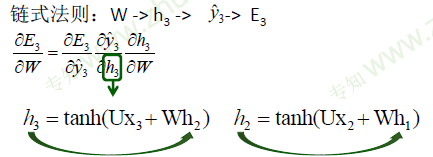
- 所以可以在此基础上继续展开,最终得到以下公式

-
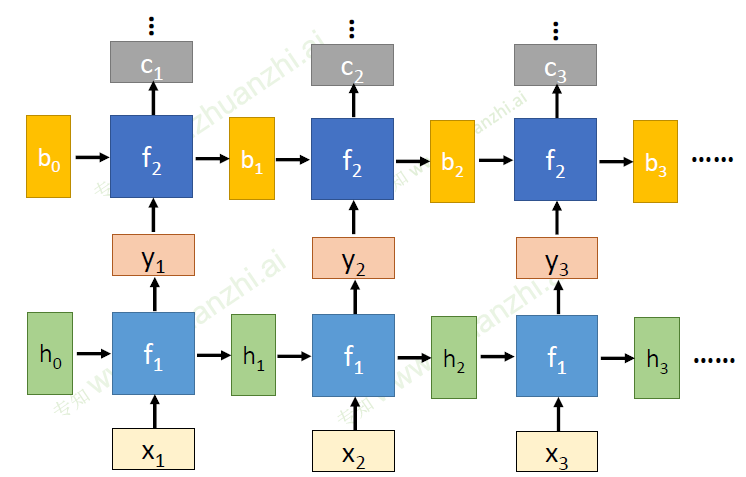
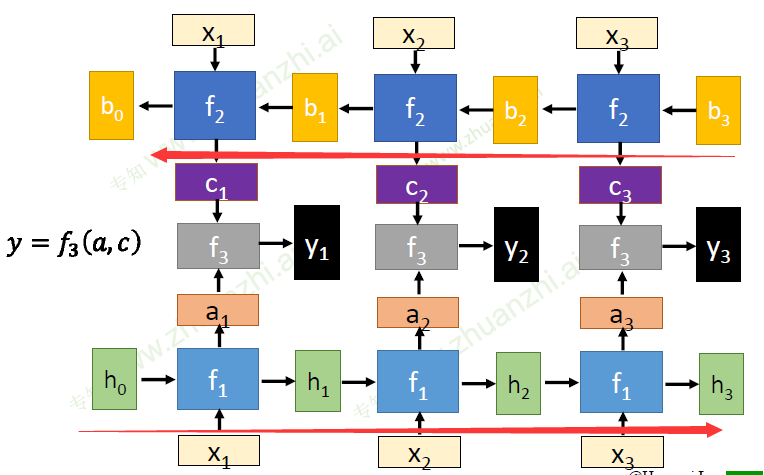
循环神经网络的变种
-
传统RNN的问题
-
当循环神经网络在时间维度上非常深的时候,会导致梯度消失或者梯度爆炸的问题
-
(h_t = tanh(Wh_{t-1}+Ux)) ,对其求偏导(= tanh' * W)
-

-
梯度爆炸的改进
- 权重衰减
- 梯度阶段:检查误差梯度的值是否超过阈值,吐过超过了那么就截断梯度,并将梯度设置为阈值
-
梯度消失导致的问题:长时依赖问题
- 随着时间间隔的不断增大,RNN会丧失学习到链接如此远的信息的能力
- 改进模型:LSTM,GRU
-
-
LSTM(long short-term memory长短期记忆模型)
-
LSTM拥有三个门(遗忘门,输入门,输出门)
-
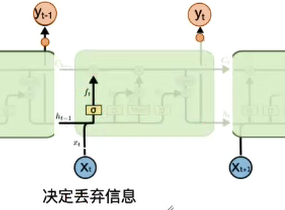
- 遗忘门:(f_t = σ(W_f[h_{t-1},x_t] + b_f)) σ为sigmoid函数
- sigmoid层输出0-1之间的值,描述每个部分有多少量可以通过。0表示“不允许”,1表示“允许量通过”
-
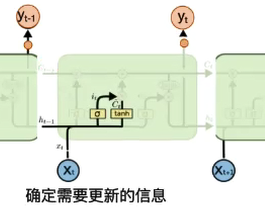
- 输入门:(i_t = σ(W_i[h_{t-1},x_t] + b_i)) $ overline C i = tanh(W_C[h{t-1},x_t] + b_C)$
- 首先经过Sigmoid层决定什么信息需要更新,然后通过tanh层输出备选的需要更新的内容,然后加入新的状态中;0 代表“不更新”,1 就指“完全更新”
-
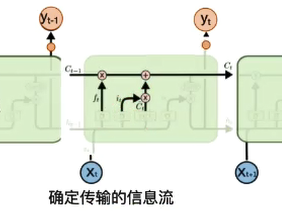
- 得到新的(C_t):(C_t = f_t * C_{t-1} + i_t * overline C_t)
- (f_t * C_{t-1})忘掉不需要的记忆信息;(i_t * overline C_t)加入需要更新的出入信息
-
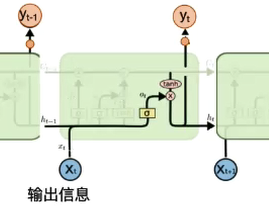
- 输出门:(o_t = σ(W_o[h_{t-1},x_t] + b_o)) $ h_t = o_t * tanh(C_t)$
- 首先,通过sigmoid 来确定细胞状态的哪个部分将输出出去。然后,将细胞状态通过tanh进行处理并将它和sigmoid 门的输出相乘,最终仅仅会输出我们确定输出的那部分;0 代表“不输出”,1 就指“完全输出"
-
RNN的“记忆”在每个时间点都会被新的输入覆盖;但LSTM中“记忆”是与新的输入相加(各自乘上一定的比例),一种线性操作
-
LSTM:如果前边的输入对(c_t)产生了影响,那这个影响会一直存在,除非遗忘门的权重为0
-
-
LSTM变形
-
GRU(Gated Recurrent Unit 门控循环单元)
-

-
GRU只有两个门,分别为重置门和更新门
- 重置门:控制忽略前一时刻的状态信息的程度,重置门越小说明忽略的越多
- 更新门:控制前一时刻的状态信息被带入到当前状态中的程度,更新门值越大表示前一时刻的状态信息带入越多
-

拓展
-
基于attention的RNN
- 受到人类注意力机制的启发,根据需求将注意力集中到图像的特定部分。
-
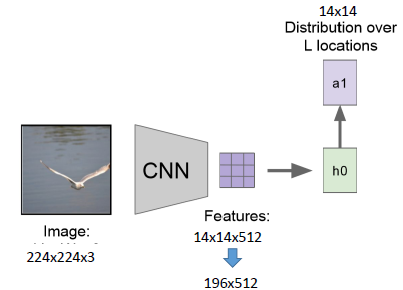
- 首先输入图像通过CNN,得到特征图(14x14x512);
- 然后根据当前记忆学习到一个attention的权重矩阵a1(14x14),并且权重矩阵在每个channel上是共享的
-
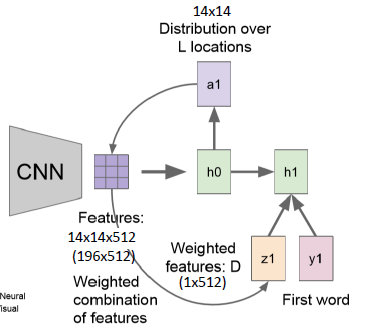
- 然后将权重矩阵a1与每一个feature map做运算,得到一个向量z1(1x512)
- 给出一个学习信号y1
-
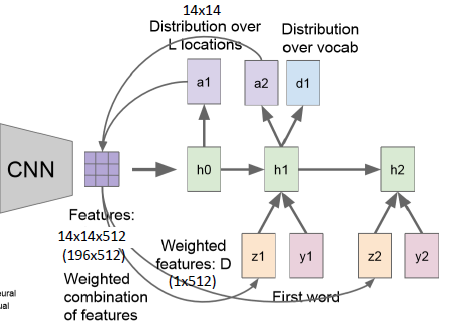
- 经过h1可以得到新的权重矩阵a2和输出d1,通过d1确定输出文字
- 然后权重矩阵a2与feature map运算,得到向量z2
- 通过这种形式一直运算下去,可以得到描述这幅图片的一句话