目录
(一)起因 (二)混合自旋锁 (三)q3.h 与 RingBuffer
(四)RingQueue(上) 自旋锁 (五)RingQueue(中) 休眠的艺术
开篇
这两天状态不是很好,我甚至把最新的《鹿鼎记》(梁栋版)快看完了,基本上是躺床上看的,其实不算好看,可能是太无聊了。不过我还是把 disruptor 大致看明白了,也修改了 disruptor 的测试代码,基本接近 RingQueue 的测试了。不过目前的测试结果跟 RingQueue 比还有点差距,不过也不算大。反正 disruptor 没有想像中的那么快,不知道是什么原因造成的,语言本身的问题?也许我应该找 disruptor 的 C++ 版本试试。而且 disruptor 在生产者和消费者越多的时候越慢,反正有点匪夷所思。同时也更新了一下 RingQueue ,也把类似 disruptor 的 ops/sec 这样的吞吐率加上去了。
disruptor 的 测试代码在:https://github.com/shines77/RingQueue/blob/master/disruptor/RingBufferPerfTest.java
后面我会写一篇关于 disruptor 的详细分析(主要分析多生产者和多消费者,能力有限,不过新版的跟网上看到的文章有些变化),有经验的也可以先帮我测测,帮我找一下问题,除了 disruptor 的休眠策略不如我的以外,其他看起来都还不错的。同时,我在 korall 提供的那个 wikipedia 的地址里也找到了两篇关于 多生产者和多消费者 的 wait-free 算法论文,研究了一会,不知道是否是正确的,即使是正确的,实现后是否一定更快?
lock-free
根据第三篇评论里网友 korall 的提醒,我们讨论一下 lock-free(无锁) 的定义,我们这么定义它:
如果一个方法是 lock-free 的,那么它将保证线程无限次调用这个方法都能够在有限步内完成,而不会因为其他线程被阻塞而导致本线程无法在有限步内完成,即“无锁”。
lock-free 的反义词是 lock(有锁的)、blocking(阻塞),同义词是:non-blocking(非阻塞)。
参考自:http://ifeve.com/lock-free-and-wait-free/
wait-free
wait-free(无等待) 的定义:
如果一个方法是 wait-free 的,那么它将保证每一次调用都可以在有限的步骤内结束,也可以理解为“无循环”,或“循环次数”为常数次或有限次。
参考自:http://ifeve.com/lock-free-and-wait-free/
q3.h分析
上一篇分析了 Sinclair 的 q3.h 的原理,以及根据网友 korall 的提醒,我们可以看到,q3.h 的 push() 前半部分领号的过程是 lock-free 的,这里 lock-free(无锁) 的定义是指假如有一个线程在领号的过程中被无限休眠或崩溃(假设存在崩溃的可能性),也不会造成别的线程在领号的过程中因此而被阻塞。而 push() 的后半部分,即提交成功的确认过程,不是 lock-free 的,而是阻塞的,因为假设在线程A里,在领号完成之后到 q->head.second = next; 这句生效之前的任何地方,如果线程A被无限休眠或崩溃,那么其他线程在确认提交的过程是会被阻塞的,因为前面一个序号没提交成功,后面的线程都必须“死等”,从而造成“死锁”,所以这个过程的确是一个“锁”。同理,pop() 也一样,前半部分是 lock-free(),后面的确认过程是一个“锁”。
由此可知,q3.h 的整个 push() 和 pop() 是由两个 lock-free 结构和两个 “锁” 构成的,虽然这两个"锁"是 push() 和 pop() 各自独立的,即 push() 的 “锁” 竞争只会发生在 push() 线程之间,pop() 的 “锁” 竞争也只会发生在 pop() 线程之间,lock-free 部分也类似。但是两个 “锁” + 两个 lock-free 结构,总体来看,竞争似乎也不算小。
所以,我们为什么不干脆直接用一个 “锁” 来解决?至少这是一个值得尝试的方案,这就是后来混合自旋锁 RingQueue::spin2_push() 诞生的原因。
失败的尝试
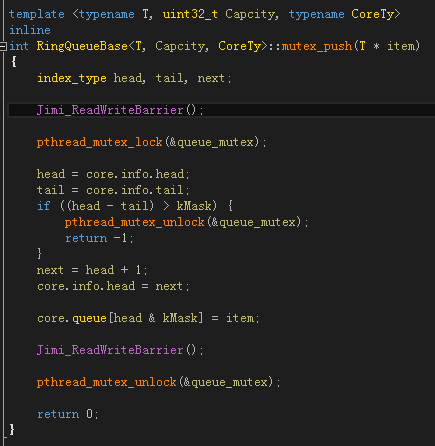
不过一开始我并没有这么想,起初,是先根据 q3.h 的大致思路,尽量考虑 CAS 来实现,即所谓的 lock-free,这个代码就是 includeRingQueueRingQueue.h 里 RingQueue::push(),RingQueue::pop(),代码截图如下:

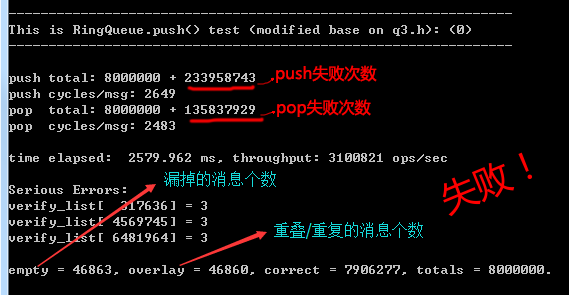
很快,我们发现有问题,如上图,因为CAS完成后,线程是有可能被休眠的,一旦休眠就有可能出现上面提到的问题。主要的原因是,虽然CAS保证了领到的 head 是唯一的,但是不能同时把 core.queue[head & kMask] = item; 也一起更新了,如果可以的话,就完美了。后来我想到了使用Double CAS,使用Double CAS更新 core.info.head 的同时一起更新 core.queue[head & kMask] 不就好了吗。可是,很快,我也发现,x86 上的Double CAS要求更新的内存地址必须是连续的,也就是说 core.info.head 和 core.queue[head & kMask] 在内存上不是连续的话,是无法使用Double CAS的,至少在目前的 x86 CPU 上不行,而由于逻辑上的问题,我们没办法让它们变成连续的内存。除非 Intel 将来实现我们想要的增强型 Double CAS……
所以这个方法是不行的。这个方法虽然简单,但冲突次数很多,所以速度不算很快,而且通过合理性验证也能证明是有bug的,截图如下。有兴趣的朋友可以在main()里把这一句://RingQueue_Test(0, true); 的注释去掉试试,同时还要把 test.h 里的#define TEST_FUNC_TYPE 定义为 0。
自旋锁
于是我开始写“锁”,想当然的,我们构造了这么一个结构体spin_mutex_t,之所以叫 spin_mutex 是因为 tbb 里就管自旋锁叫 spin_mutex,因为其逻辑上确是一个“互斥量”,所以叫 mutex 也贴切,不过一般习惯叫spin_lock。
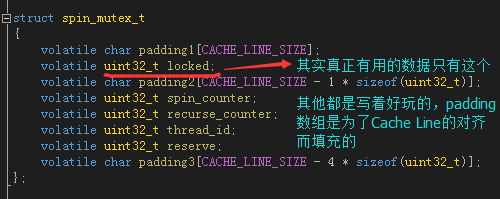
其实真正有用的数据只有一个uint32_t locked,为1时是“锁”状态,为0时是“未锁”状态。padding1, padding2, padding3是为了对齐而填充的,因为我们并没有对结构体本身声明字节对齐(我懒得弄了),所以开头只好加个padding1这么弄了,浪费那么一点内存没关系。后面那些spin_counter,recurse_counter,thread_id什么是用来扩展的,这里没有用到,写着好玩的。
之所以说想当然,是因为我从来也没写过自旋锁,于是写成了这样:
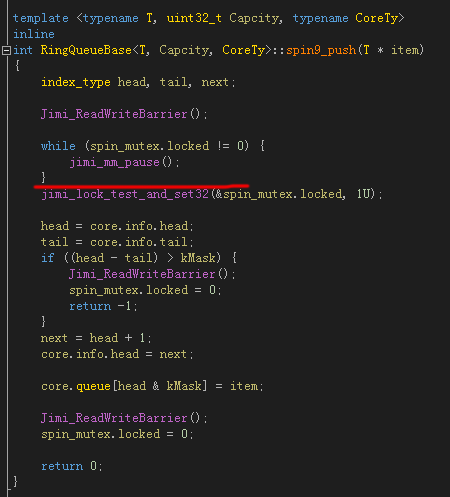
jimi_lock_test_and_set32() 其实就是 InterlockedExchange() 或者 __sync_lock_test_and_set(),一开始用 while (spin_mutex.locked != 0) 判断是否为 0 (未锁)状态,如果是 0 才进入锁区域,然后用原子操作把 “锁” 状态更新为 1 (锁)状态,最后出了锁区域,再把锁状态置为 0 (未锁)。一切看起来很正常,可是运行起来会活锁 (livelock),也许偶尔会放一个消息进来,但非常非常慢,甚至可能变成死锁 (deadlock),反正状态几乎是未知的。分析原因,注意上图中的划红线的地方,虽然前面可能检测的锁状态的确是 0 (未锁)状态,但是如果线程在红线的地方被休眠了,那么因为锁状态依然是 0,那么其他线程也可以进入锁区域,然后把锁状态设为了 1,等该线程被重新唤醒以后,它不知道锁已经是 1 (锁)状态,它也处于锁保护的区域,并且把锁状态也重新设置为 1,这将导致两个线程同时处在锁区域内,这将导致共享的资源出现同步的问题。另一方面,jimi_lock_test_and_set32()是有可能因缓存行(Cache Line)被其他线程锁住而失败的,因此有时候并不能成功写入状态1,这将使多个线程同时进入锁区域的问题更加频繁。当队列满了或空了的时候,状态就变得不可预测了。
这个代码也保留在了 RingQueue::spin9_push() RingQueue::spin9_pop() 里,也可以看整理过后的版本 RingQueue::spin8_push() RingQueue::spin8_pop(),两者是一样的。
Compare-And-Swap
不过,很快的,我们用 CAS (Compare-And-Swap) 改进了前面错误的代码。CAS 的说明可参考 第三篇 里的相关介绍。
int val_compare_and_swap(volatile int *dest_ptr, int old_value, int new_value) { int orig_value = *dest_ptr; if (*dest_ptr == old_value) *dest_ptr = new_value; return orig_value; }
我们需要的是判断锁状态为 0 的同时把锁状态置为 1,CAS 刚好能够实现我们的效果,因为 CAS 操作是原子性的,所以不会出现我们前面所遇到的多于一个线程同时进入锁区域的问题。
RingQueue::spin_push()
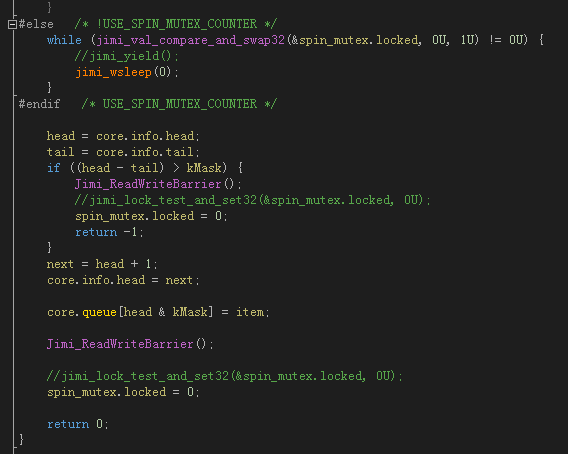
这是自旋锁的第一个版本,RingQueue::spin_push(),你可以看到,其实它并没有自旋,而是jimi_wsleep(0)了一下,jimi_wsleep(0)在Windows下等价于Sleep(0),在Linux下等价于sched_yield()。这里并没有休眠,而是切换到了别的线程。
还有一个问题,就是上图中两个 “spin_mutex.locked = 0;“ 语句的前面一行,我都注释掉了一行原子写操作的代码。那是我原来写的,可是后来仔细分析,进锁的时候用 CAS 把门关上了,最后 “解锁” 的时候是没必要用原子操作来更新锁状态的,置 0 的瞬间就代表了解锁。这样效率会好很一些,为什么呢,你仔细想想就会明白,唯一需要的就是在更新锁状态之前要加一个内存屏障/编译器内存屏障,如代码中的Jimi_ReadWriteBarrier()。这个也是后来看了很多其他代码所证实的,其实也没什么稀奇的,不过如果你不明白,还是要提一下。
不过我也写了自旋的版本,具体可以参看 RingQueue::spin_push() 的代码,需要在 test.h 里面把宏 USE_SPIN_MUTEX_COUNTER 定义为 1才能打开自旋的版本,自旋循环控制参数为宏 MUTEX_MAX_SPIN_COUNT (默认设置为1)。
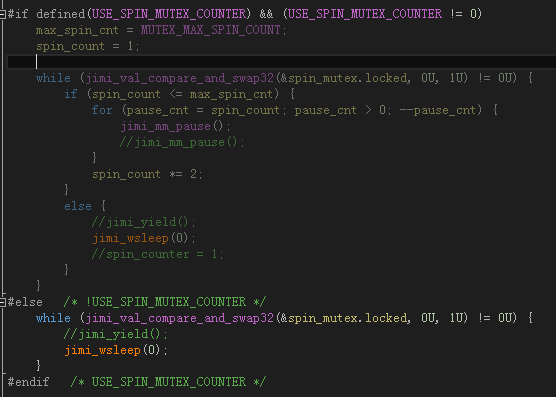
这个策略是跟 Intel 多线程库 tbb 的 spin_mutex 学的。
测试结果
就是这么小的一个改进,速度已经不错了,不过缺点是不够稳定。
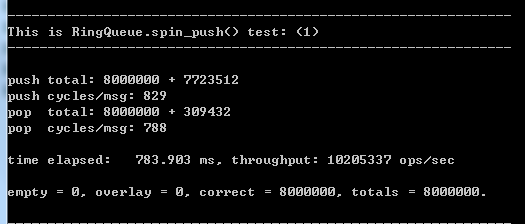
有时候是这样的:
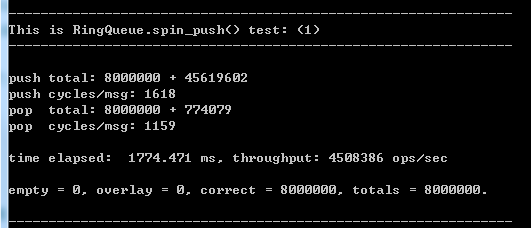
测试环境
这里说一下我的测试环境:
CPU: Intel Q8200 2.4G / 4核
系统: Windows 7 sp1 / 64bit
内存: 4G / DDR2 1066 (双通道)
编译平台: Visual Studio 2013 Ultimate update 2 (自带的 cl.exe)
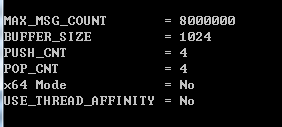
使用的是 4 个 push() 线程(生产者),4个 pop() 线程(消费者),消息总数为 8000000 条(八百万),队列的容量为 1024 (buffer_size),x86模式,不开启CPU亲缘性。
系统互斥锁
如果你对这个速度没有概念,我们找一个东西来作为基准,用 mutex (互斥锁) 再合适不过了,Windows下它叫临界区(CriticalSection),Linux下它叫pthread_mutex_t:
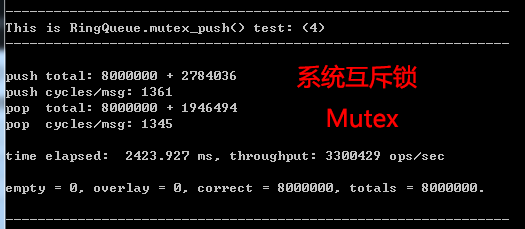
这个是 PUSH_CNT = 2, POP_CNT = 2 下得到的结果,不过对于系统的互斥锁,这个值是多少差别不大。
系统互斥锁的版本是:RingQueue::mutex_push()。
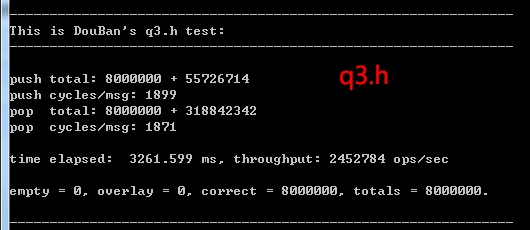
q3.h 的测试结果
下面是 豆瓣 Sinclair 的 q3.h 的测试结果,可以看到,并不是很快,甚至比系统互斥锁(Mutex)还要慢一点,由于其只有当 (PUSH_CNT + POP_CNT) <= CPU核心数 时才能正常工作,否则会很慢很慢,所以下面的数据也是在 PUSH_CNT = 2, POP_CNT = 2 下得到的:
Thread.Yield()
说句实话,RingQueue::spin_push() 依然还是太简单了一点,即使是模仿 tbb 的自旋版本也谈不上有多复杂,感觉哪里还不是太够。
我在 c++1y boost 交流群(QQ群:296561497)里曾经看 DengHe.Net 贴过一个 C# 用反射工具反编译的关于 Thread.Yield() 的源码(发到群里的是图片),其实类似的东西在哪里好像也看过,只是你不到真正要用的时候,是不会发现它的问题的。我后来在两个群里翻聊天记录找了一个多小时,结果还是没找到,其实我知道网上能搜到,不过还是觉得好像 DengHe 贴的那个好像有点特别,后来他告诉我就是反编译的 SpinWait.cs,其实那个时候我也找到 SpinWait.cs,由于我对 C# 也不是很熟,没想到用反射工具。
其实 Thread.Yield() 是怎么回事还是大致知道的,不过的确有个确定的版本会更加有参考性一点,C#的 Thread.Yield() 除了参数是固定不能修改的以外,其他的设置还是比较合理的,这也是 RingQueue::spin2_push() 的雏形。当然我还是做了一些小调整,因为混合自旋锁要想效率高,就看你怎么调整这些参数,这是一个休眠的策略。或者说是一门休眠的艺术,再后面一点我会详细描述。今天就先卖个关子。。。
关于RingQueue的使用
RingQueue的源码最关键的地方就在 includeRingQueue est.h 里面了,这里的宏定义是各个部分的编译开关,我基本都写了注释,如果有不懂的可以自己研究,或者问我,基本上我考虑的东西算比较多了,里面最重要的就是 PUSH_CNT 和 POP_CNT 的定义,顾名思义,PUSH_CNT 就是 push() 的线程数,POP_CNT 就是 pop() 的线程数,分别对应着生产者(producer)和消费者(consumer)的个数。如果你想测试 q3.h,那么你的 (PUSH_CNT + POP_CNT) 必须小于等于你的CPU核心数,否则会慢得出奇。例如你的 CPU 是双核的,就知道定义为 PUSH_CNT = 1, POP_CNT = 1 了,如果你不测 q3.h,那么建议你把 PUSH_CNT 和 PUSH_CNT 设置成跟你的 CPU 核心数一样,即 PUSH_CNT = 2, POP_CNT = 2。因为一般来讲,把总线程数设置为 CPU 核心数的两倍是比较能够提高 CPU 的利用率的,这是一组较优解,虽然不一定是最优解,其他设置请自行看 test.h。
休眠
今天就写到这里吧,本来想一口气写完的,如果可以的话,以后再合并在一起。
其实还有个问题耽搁了写文章,就是我也不知道哪根筋不对,在 REDUI 群里宣传我的博文,还跟某些人有点小吵起来,经过两天时间,虽然有些摩擦,最终他们还是接受了我关于 RingQueue 的一些思路和想法,最后还讨论到了一起去,也算是有点小开心吧,至少比 SkyNet 群好多了。其实说白了也没多少东西要讲,不过细节不少,我还自己发现了一些奇怪的问题,其实我是想把那些细节讲好,但我发现现在的确控制得不是很好,也许我应该憋长一点再发(文章),或者你直接看源码比较快。
RingQueue
RingQueue 的GitHub地址是:https://github.com/shines77/RingQueue,也可以下载UTF-8编码版:https://github.com/shines77/RingQueue-utf8。 我敢说是一个不错的混合自旋锁,你可以自己去下载回来看看,支持Makefile,支持CodeBlocks, 支持Visual Studio 2008, 2010, 2013等,还支持CMake,支持Windows, MinGW, cygwin, Linux, Mac OSX等等,当然可能不支持ARM。
目录
(一)起因 (二)混合自旋锁 (三)q3.h 与 RingBuffer
(四)RingQueue(上) 自旋锁 (五)RingQueue(中) 休眠的艺术
上一篇:一个无锁消息队列引发的血案(三)——地:q3.h 与 RingBuffer
下一篇:一个无锁消息队列引发的血案(五)——RingQueue(中) 休眠的艺术
.