有水印视频
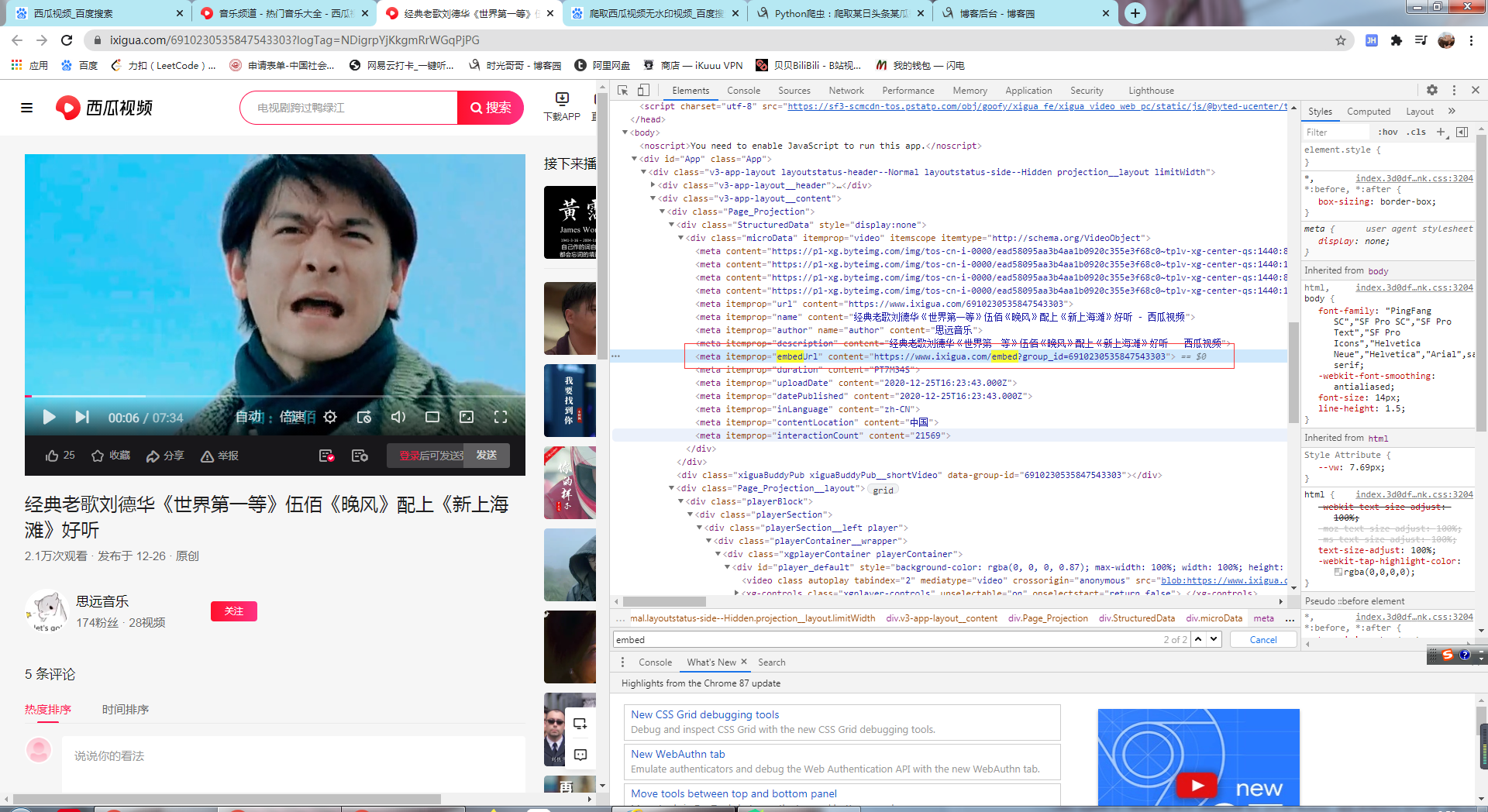
上面那个链接在浏览器打开就是播放地址 ,可以直接请求并保存视频
无水印视频
没有水印的视频是音频和视频分离的,在network下选择xhr
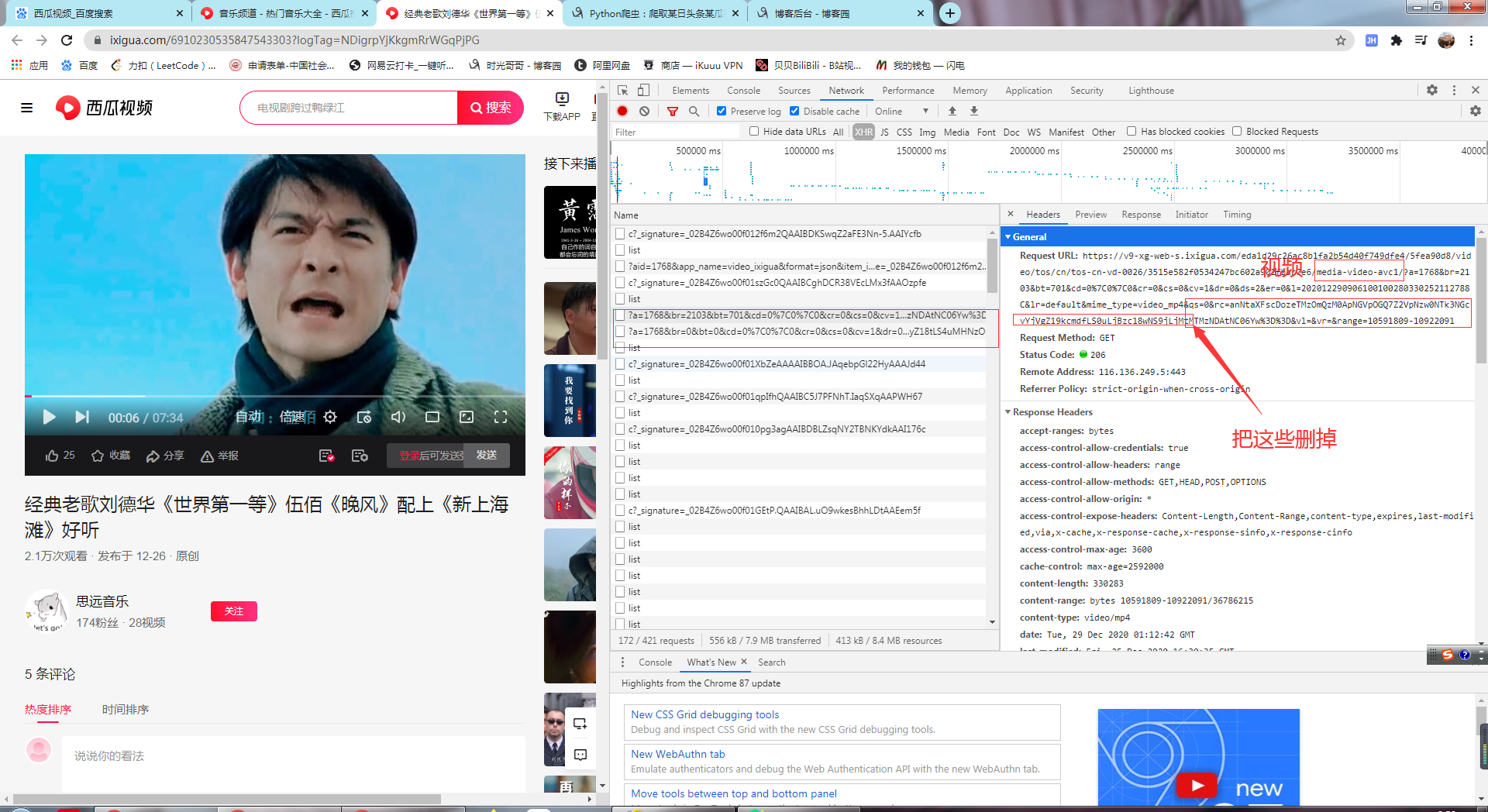
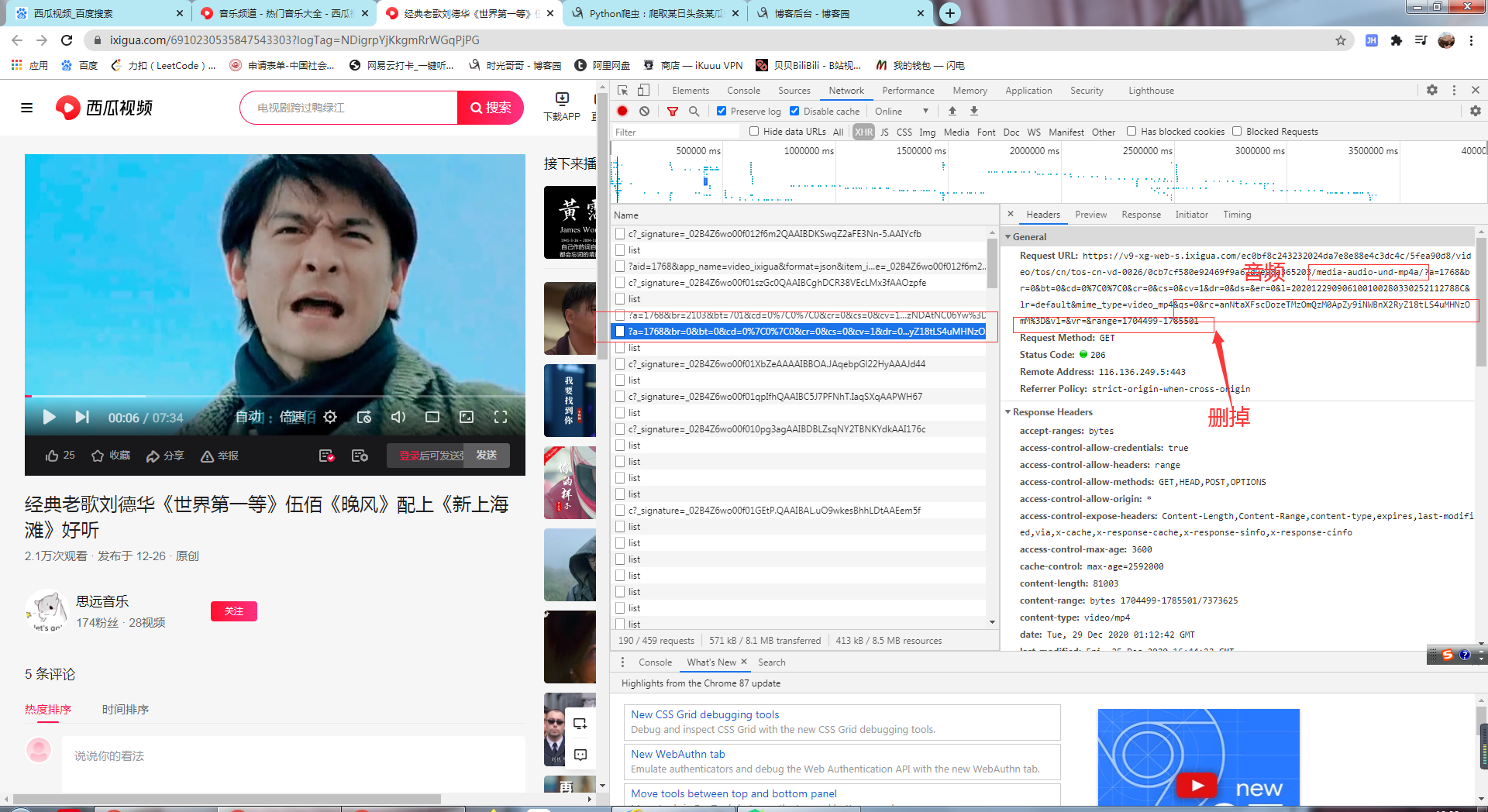
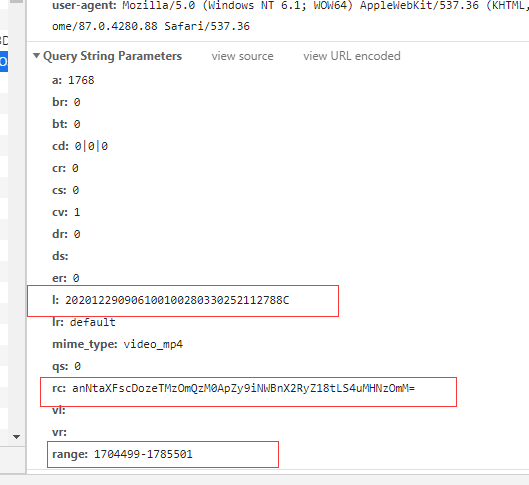
无水印的有一些加密参数暂时没有找到是怎么加密的
有水印的视频还有一种下载方式 代码如下
# -*- coding: utf-8 -*- # __author__ = "maple" from base64 import b64decode from lxml import etree import requests import json import re import os class XiGuaSpider: def __init__(self): self.headers = { 'Referer': 'https://www.ixigua.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', 'cookie': 'wafid=8b91d940-81ec-4620-af0f-f45d479a62c2; wafid.sig=BZgx1eD0aFGn25mL-y-SEh17cng; ttwid=6841106955945346564; ttwid.sig=glkPgElc0Yh0OEDyNL0P91fmbZg; xiguavideopcwebid=6841106955945346564; xiguavideopcwebid.sig=avM_v_QTwC7VqM26Yqde9eer3xA; _ga=GA1.2.1235075053.1592819342; SLARDAR_WEB_ID=fa1eb835-d608-4ade-850d-bc0409bd541f; _gid=GA1.2.303152420.1593089518; ixigua-a-s=1; Hm_lvt_db8ae92f7b33b6596893cdf8c004a1a2=1593094562,1593095154,1593098009,1593147688; Hm_lpvt_db8ae92f7b33b6596893cdf8c004a1a2=1593153331', } self.video_dirs = './video' def download_file(self, file_path, download_url): print('*' * 100) print(f"保存路径:{file_path}") print(f'下载URL:{download_url}') response = requests.get(url=download_url, headers=self.headers, stream=True) content_size = int(response.headers["content-length"]) # 视频内容的总大小 size = 0 with open(file_path, "wb") as file: # 非纯文本都以字节的方式写入 for data in response.iter_content(chunk_size=1024): # 循环写入 file.write(data) # 写入视频文件 file.flush() # 刷新缓存 size += len(data) # 叠加每次写入的大小 # 打印下载进度 print(" 文件下载进度:%d%%(%0.2fMB/%0.2fMB)" % ( float(size / content_size * 100), (size / 1024 / 1024), (content_size / 1024 / 1024)), end=" ") print() def get_response(self, url): response = None try: response = requests.get(url, headers=self.headers) except Exception as e: print(e) return response def parse_detail(self, url): response = self.get_response(url) if not response: return html = response.text document = etree.HTML(html) title = ''.join(document.xpath('//*[@class="hasSource"]/text()')) if not title: title = ''.join(document.xpath('//*[@class="teleplayPage__Description__header"]/h1/text()')) title = re.sub(u"([^u4e00-u9fa5u0030-u0039u0041-u005au0061-u007a])", "-", title) pattern = r'<script.*?>window._SSR_HYDRATED_DATA=(.*?)</script>' result = re.findall(pattern, html) if len(result) < 1: print('没有找到下载链接。。。') return None result = result[0] data = json.loads(result) with open('video.json', 'w', encoding='utf-8') as f: json.dump(data, f) try: video_list = data['Projection']['video']['videoResource']['normal']['video_list'] except Exception as e: print('异常信息:', e) video_list = data['Teleplay']['videoResource']['normal']['video_list'] video_3 = video_list.get('video_3') if not video_3: video_3 = video_list.get('video_2') video_url = video_3['main_url'] video_url = b64decode(video_url).decode('utf-8') if not os.path.exists(self.video_dirs): os.mkdir(self.video_dirs) file_path = f"{self.video_dirs}/{title}.mp4" self.download_file(file_path, video_url) def start_requests(self): url = 'https://www.ixigua.com/i6618828724525597192' self.parse_detail(url) def run(self): self.start_requests() if __name__ == '__main__': XiGuaSpider().run()