在报表开发早期,报表连接的数据源基本只有关系数据库,而且经常只有一种或者只有一个数据库。
但今天就不一样了,数据源种类繁多,除了 RDBMS 还有
1.MongoDB、Cassandra、HBase、Redis 这些 NoSQL 数据库;
2.TXT/CSV、Excel、JSON/XML 等文件;
3.HDFS 等分布式文件系统;
4.webService;
5.ES、Kafka 等其他数据源形式
……

当这些都成为报表数据源,报表需要从这些数据源分别或混合取数运算进行报表呈现时,报表就出现了多样性数据源问题。
具体是什么样的问题呢?
主要是两个问题,复杂计算和多源关联计算。
1. 复杂计算
我们知道,报表中的计算主要集中在两处:
一处是数据准备阶段。
通过 SQL/ 存储过程 /Java 程序为报表准备数据,这个阶段可能涉及非常复杂的数据处理逻辑。这样, 计算能力尤其是集合计算能力较强的 SQL 就比较擅长了,通过 SQL、复杂 SQL 可以完成大部分的报表数据准备任务,有些涉及较多业务逻辑的计算还可以使用存储过程,万不得已时用 JAVA 自定义数据源完成。
这是早期基于单一 RDBMS 开发报表时数据准备的常用手段,主要依靠 RDBMS(SQL)的计算能力来实现。
但这种方式在多样性数据源的场景下就行不通了,因为有的数据源根本就不支持 SQL,甚至计算能力都比较弱(如 NoSQL),或者根本就没有计算能力(如文本),这样,数据准备计算计算无法在这个阶段实现,就要看另外一处是否可以完成了?
二处是报表呈现阶段
根据第一阶段已准备的数据,在报表模板中填入绑定格子的报表表达式或图形来呈现报表是使用报表工具开发报表的常用方式。这说明报表工具具备一定的计算能力,通过表达式可以实现分组汇总、过滤、排序,复杂一些的同比环比等计算。
但是,报表工具的计算能力是有限的。不考虑性能的情况下,单纯从数据源中读取数据到报表呈现阶段完成数据组织和报表呈现很多时候是做不到的,这也是为什么我们会在数据准备阶段进行复杂数据处理的原因了。
2. 多源关联计算
与基于单一的某个数据源进行的复杂计算不同,有时一个报表会同时连接多个数据源,多个数据源之间要混合计算,比如 MongoDB 的数据和 RDBMS 的数据关联运算,文本和 Excel 关联运算等。
这种跨异构数据源的关联无法直接通过数据源自身的能力实现,只能借助其他方法。
那报表的多样性数据源问题如何解决呢?
方法总比问题多。目前大家普遍采用两种方式来解决报表多样性数据源的问题。
借助 RDBMS
曲线救国。将多样性数据源的数据通过 ETL 灌到关系库中,再基于关系库出报表,这样就可以避免多样性数据源的问题,转而使用最熟悉的手段来解决。
不过,这种方式的局限性很大。因为之所以出现多样性数据源,是因为各种数据源有各自适用的场景,换句话说很多是关系库搞不定的,所以才会用这些数据源,比如 NoSQL 的 IO 吞吐能力很强,但计算能力较弱;文本 /Excel 文件适合做临时存储且不需要持久化到 DB;Webservice 则非常灵活,入库的动作就显得过于笨重,…
且不说多样性数据源的数据是否能转换到关系库中,由于要经过 ETL 的过程,数据的实时性如何保证?数据量较大时除了 ETL 慢,RDBMS 的容量是否够用?查询性能是否满足报表查询要求?等等这些问题都是这种方式要面对的。
采用这种方式经常是“不得已”,因为解决某类问题上了其他数据源,结果因为出报表又要用回关系库,也不知道隐含了多少辛酸。
JAVA 硬编码
通过 RDBMS 来解决报表多样性数据源的问题有这样那样的问题,那直接硬编码怎么样?通过 JAVA 硬编码对接多样性数据源为报表准备数据,毕竟硬编码想干啥就干啥。
这种方式我们之前有分析过,除了编码难、维护难的问题(报表开发人员基本搞不定),还存在无法热切换(JAVA 是编译型语言)和与业务应用紧耦合(代码要跟业务应用主程序一起打包部署)这些问题。这是我们之前聊过的: 用存储过程和 JAVA 写报表数据源有什么弊端?
硬编码似乎也不理想。
事实上,我们只需要增强报表工具的计算能力就能解决这个问题。
1. 首先,提供多样性数据源的支持,通过报表工具可以连接这些数据源,要实现这一步相对简单;
2. 其次,提供复杂计算支持,让所有的复杂计算都能在报表中完成。实现手段可以是强化呈现端的计算能力,通过报表格子表达式就能完成这些复杂计算。不过,对于绑定格子的计算(状态式计算)想要支持复杂计算并不容易,在呈现端要兼顾数据处理和数据呈现很多计算就做不了了,而且呈现格会带有很多呈现属性(字体、颜色、边框等等),带着这些属性计算会占用过多内存,严重影响计算性能。
很难在报表呈现格表达式中完成复杂计算(功能和性能都不满足)
可以想到的另外一种方式是在报表中增加计算模块用来专门做多样性数据源混合计算,其位置与原来为报表准备数据的 SQL 和 JAVA 相当,只不过是内嵌在报表中,属于报表自身的能力,结构大概是这样

在原有的基础上增加了计算模块,计算模块可以通过可编程计算脚本实现,但对这个脚本能力有要求:
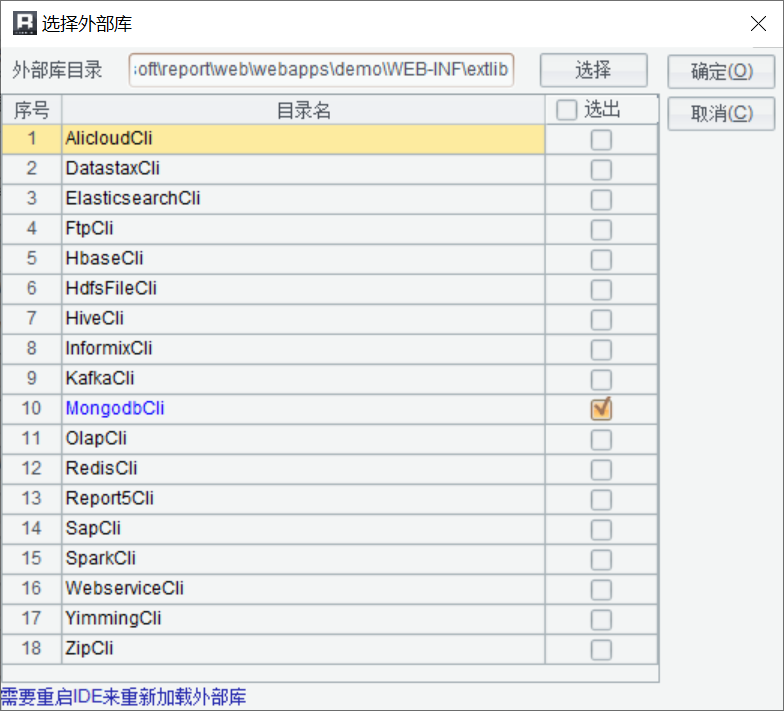
1. 提供多样性数据源访问接口
能直接对接多样性数据源是基础,种类越丰富对多样性数据源问题解决得越充分;
2. 支持复杂计算
当数据源自身不具备强计算能力时,通过脚本可以完成报表数据准备阶段的复杂计算逻辑,脚本提供丰富的计算类库,可以很方便地实现这类计算,最好比 SQL 和 JAVA 都简单;
3. 支持多源关联
可以跨异构数据源关联计算,这是也解决报表多样性数据源问题需要具备的重要能力;
4. 支持热切换
脚本修改后可以实时生效,而不会像 JAVA 一样需要重启应用。
当我们遇到报表多样性数据源问题需要选择报表开发技术时不妨沿着这个方向考量一下。