【论文标题】Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering (24th-IJCAI )
(Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2015) )
【论文作者】Liping Jing, PengWang, Liu Yang (Beijing Key Lab of Traffic Data Analysis and Mining, Beijing Jiaotong University)
【论文链接】Paper (7-pages // Double column)
【摘要】
在推荐系统中,概率矩阵分解(PMF)是一种最先进的协同过滤方法,它通过确定隐含特征来表示用户和项目。 然而,限制其有效性的两个主要问题是稀疏性问题和长尾分布。 稀疏性是指观测到的评级数据稀疏的情况,这导致只有部分隐含特征对描述每个项目/用户是有信息的。 长尾分布意味着大部分物品的评分数据都很少。
在本研究中,我们提出一种稀疏概率矩阵分解方法(SPMF),利用拉普拉斯分布来建模项目/用户因子向量。拉普拉斯分布具有生成稀疏编码的能力,这有助于SPMF区分与每个项目/用户相关和不相关的潜在特征。 同时,拉氏分布的尾部较重,这也为SPMF推荐尾部项目提供了依据。 在此基础上,提出了一种分布式Gibbs采样算法来有效地训练稀疏概率模型。 在Netflix和Movielens数据集上进行的一系列实验表明,SPMF优于现有的PMF及其扩展版本Bayesia PMF (BPMF),尤其是在尾部项目的推荐方面。
【1 介绍】
随着大数据的出现,推荐系统在提供个性化推荐和改善用户体验方面发挥着越来越重要的作用 [Adomavicius and Tuzhilin, 2005]。近十年来,基于矩阵因子分解(MF)的协同过滤(CF)方法[Koren et al., 2009]显示出其建立准确预测模型的能力,并被亚马逊、谷歌、Netflix等商业世界广泛采用[Dror et al., 2012]。MF方法通过确定用户和项目的隐含特征来预测用户的偏好。 MF方法将评价矩阵分解为两个低秩矩阵,一个是隐含用户因子矩阵,另一个是隐含项目因子矩阵。通过将这两个隐含因子矩阵相乘,我们可以完成原始的不完全评分矩阵并进行推荐。
But:
局限性:稀疏且大规模的评分数据。伴随着长尾效应的出现。
虽然与每个尾部项目相关的用户数量在绝对数量上很小,但是总体上它们覆盖了所有用户的很大一部分。此外,用户在电子商务中购买的稀有商品比购买流行商品更能反映他们的品味。
好好利用长尾商品对于预测用户偏好是相当重要的。
[2007] 提出了PMF,基于假设:隐含因子服从高斯分布。不过此假设成立的前提是观测变量是连续的, 然而,当数据在有序尺度上时,它就不那么合理了。
之后,贝叶斯矩阵分解(BPMF) [Salakhutdinov and Mnih, 2008] 通过将 Gaussian- wishart 先验加到因子向量上进行估计,并试图通过两个多变量高斯函数的乘积生成一个非高斯分布。
最近,[Shi et al., 2013]采用了稀疏协方差先验来加强用户和项目因子,使每个隐含特征更恰当地反映语义。
到目前为止,PMF及其变体已成为具有代表性的CF方法,但它们不能保证每个用户都能有效地由最有信息性的隐含特征表示出来。
在实际应用中,获得合适的用户/项表示对于完成稀疏评分矩阵至关重要,特别是对于与尾部项目相对应的单元格值。
—— 因此,我们提出一种稀疏概率矩阵分解方法(SPMF),利用拉普拉斯分布来建模项目/用户因子向量。SPMF 可以看作是PMF的一种变体。
拉普拉斯分布 [Mohamed et al., 2011] 使得每个因子向量的大部分元素接近于零,这样一方面有利于SPMF区分每个用户/项的相关和不相关的隐含特征。同时,由于拉氏分布中的尾部比较重,那么在另一方面,对于识别尾项和部分解决长尾问题是有益的。
由于拉普拉斯分布是不光滑的,所以SPMF的贝叶斯推理在解析上是不可处理的。
本文将其表示为高斯分布与指数密度的比例混合,并利用马尔可夫链蒙特卡罗方法进行贝叶斯推理。我们工作的第二个显著特点是用于训练SPMF模型的分布式Gibbs sampling算法,该算法可以有效地处理1M MovieLens和100M Netflix 等大规模、稀疏和非常不平衡的数据集。
【2 相关工作】
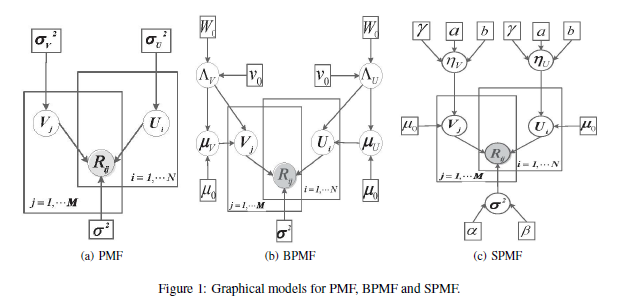
PMF :
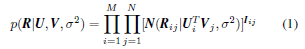
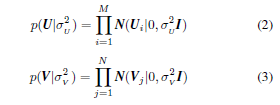
假设:用户因子和项目因子都服从正态分布。
解法:最大化公式(1)的对数后验——通过最小化平方和误差
缺点: [将所有特征限制在相同的正则化级别] 限制了模型的灵活性。此外,寻找正则化参数的适当值在计算上是非常昂贵的。
BPMF:

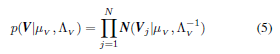
U 和V上的先验分布都服从高斯分布。
超参数 
 服从Gaussian-Wishart 分布。
服从Gaussian-Wishart 分布。
解法:通过最大化模型的对数后验求解参数和超参数。BPMF可以自动控制模型的复杂度。
Shi et al. [Shi et al., 2013]等人提出了稀疏协方差矩阵分解(SCMF),将拉普拉斯先验应用于U和V的协方差矩阵,以考虑特征相关性,防止过拟合。
虽然BPMF和SCMF得到了很好的结果,但它们和PMF一样,都假设因子服从高斯分布,这在数据极其稀疏的情况下是不合理的。
SPMF:
为了实现稀疏性,可以使用prefer偏爱高过剩峰度的sparsity-favoring稀疏性分布,即,有一个尾巴很重的高峰。prefer偏爱稀疏分布的集合包括尖峰-板状分布、Student-t、拉普拉斯分布和伽玛分布[Polson and Scott, 2010]。其中,拉普拉斯分布为对数凹型,导致后验函数的对数密度为凹型函数,具有单一的局部最大值,这对于设计鲁棒且易于使用的算法至关重要[Paninski, 2005]。
……
【4 实验结果和讨论】
4.1 方法论
数据集:两个数据集都是1-5分。
| Dataset | Users | Items | Ratings | Density |
| Movielens | 6040 | 3952 | 1M | 4.26% |
| Netflix | 480,198 | 17,770 | 100M | 1.18% |
【长尾推荐】
在现代的推荐系统中,只有一小部分项目是受欢迎的,而大部分项目的评级信息很少。然而,这些不受欢迎的项目,也被称为长尾项目[Anderson, 2006],往往在推荐中发挥着重要的作用,特别是在商业世界。例如,亚马逊成功地从长尾产品而不是畅销产品中获得大部分利润。
为了研究我们提出的SPMF方法是如何处理长尾项目的,我们首先根据项目的评分频率进行排序,然后几乎均匀地将它们分成10组。图5(a)展示了MovieLens数据集在10个item组中的评分数量,其中x轴为每组评分频率的边界。显然,它们遵循长尾分布。图5(b)和(c)分别给出MovieLens和Netflix的每个item组的平均RMSE,它们是通过分别设置SPMF、BPMF和PMF的D = 50的推荐结果得到的。正如预期的那样,所提出的SPMF模型优于两条基线,特别是对于长尾部分的项目(是指x 轴靠左部分)。
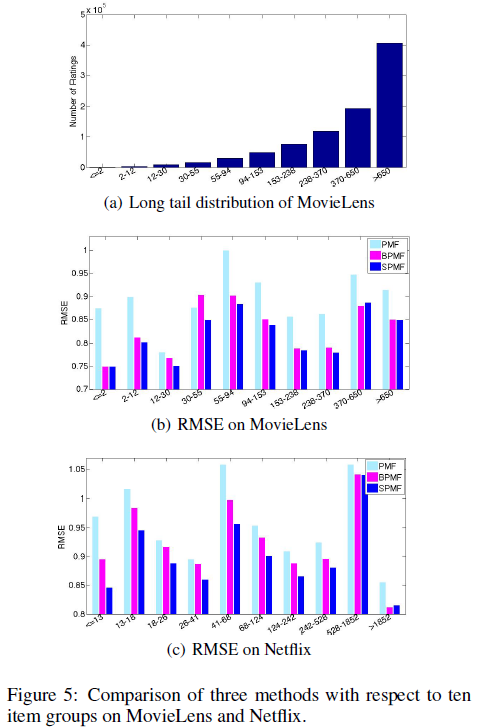
——补充~~start
图5(a) ,
x轴表示项目的评分频率,( 根据项目的评分频率进行排序,然后几乎均匀地将它们分成10组)
y轴表示rating评分的数目。
长尾的解释为:热门商品(被评的多的)其实很少,而冷门商品(很少被评到的)反而占绝大部分。 ——>> 关于推荐系统中的长尾商品
最后面的一组(>650)表示 item被评超过650次的总的rating数目,(热门商品收到的rating当然多了。)
图5(b) ,“正如预期的那样,所提出的SPMF模型优于两条基线,特别是对于长尾部分的项目。”
长尾部分的项目对应于x轴左半部分。推荐了很多长尾商品,那么与groundtruth相比,RMSE降低了。√
——补充~~end
这一结果进一步验证了SPMF与隐含因子上的sparsity-favoring分布(拉普拉斯分布)相结合,具有处理稀疏评分数据的能力。主要原因是BPMF对V施加高斯先验,而SPMF假设V是由拉普拉斯分布生成的。这种稀疏先验可以有效地将每个因子向量中的元素划分为一个概率高、接近于零的大集合和一个在大值上具有显著质量的小集合。因此,SPMF可以很好地对长尾项目进行建模,特别是对不受欢迎的项目,可以显著提高推荐性能。
【5 结论和未来工作】
本文提出了一种稀疏概率矩阵分解模型和一种分布式吉布斯采样算法来推导模型。实验结果表明,与现有的基于mf的CF方法相比,该模型可以有效地训练和成功地应用于稀疏和大规模数据。我们模型的一个显著特征是它能够处理长尾项。这使得SPMF具有潜在的商业价值,例如可以用来开拓长尾市场,提高一站式购物的便利性。
该模型得益于拉普拉斯分布对隐含因子的建模,但我们必须对隐含特征的大小进行经验调整。如果能自动找到合适的D那更好。另外,对数线性模型的Gibbs sampling需要消耗大量的内存,因此,我们将其转化为鲁棒MF问题[Wang et al., 2012]来降低空间复杂度。另一个可能的方向是扩展模型,使其能够冷启动推荐,这是一个具有挑战性的问题[Houlsby et al., 2014]。最后但并非最不重要的是,将该模型应用于具有大规模在线数据的电子商务等领域将很有趣。