1、1触发器
6、1触发器 ***触发器有两个指针1、new(更新后的,2、OLD更新前的)
1、若搜索员工信息的时候,需要把领导的名字展现出来,那么需要增加一列冗余。
ALTER TABLE t_emp ADD ceoname VARCHAR(200);
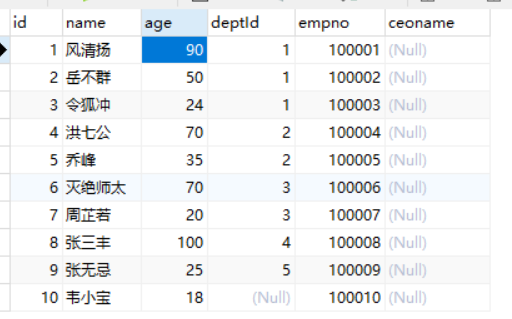
2、需要将相对应的ceo名字对应更新到新增字段中,用到跨表插入。
UPDATE t_emp a
LEFT JOIN t_dept b ON a.deptId=b.id
LEFT JOIN t_emp c ON b.CEO=c.id
SET a.ceoname=c.name;
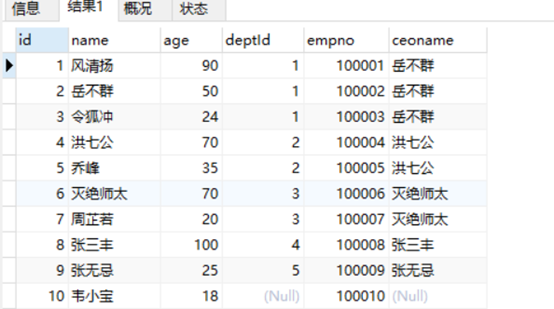
3、假如之前门派的掌门人变了,但是ceoname,则还是之前的掌门人名称,则不能对应上。所以就需要mysql引擎了,让冗余跟着数据的变化而变化。
DELIMITER $

create trigger tri_stuInsert2
after UPDATE ON t_dept
FOR EACH ROW
BEGIN
UPDATE t_emp a
LEFT JOIN t_dept b ON a.deptId=b.id
LEFT JOIN t_emp c ON b.CEO=c.id
SET a.ceoname=c.name
WHERE a.deptId=new.id;
END$
DELIMITER ;
DELIMITER $
create trigger tri_stuInsert2
after UPDATE ON t_dept
FOR EACH ROW
BEGIN
IF new.id<>`OLD.id THEN
UPDATE t_emp a
LEFT JOIN t_dept b ON a.deptId=b.id
LEFT JOIN t_emp c ON b.CEO=c.id
SET a.ceoname=c.name
WHERE a.deptId=new.id;
END IF;
END$
DELIMITER ;
Chuang
弊端:
1、 不利于维护
2、 批量操作的时候,伤性能
3、 写操作很难被java日志追踪。
4、 造成死循环
2、事件
问题描述:在一个表中,很多列都是经过复杂计算得来的,那么请求一次去刷新获取表数据的操作,则需要10秒左右,开发人员该如何优化快速查取到表中数据?
2.1在执行mysql的时候,将搜索到的数据插入到创建的新标当中。
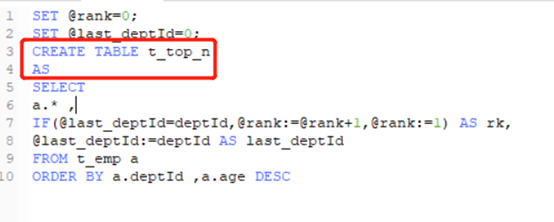
2、根据搜索数据,批量插入,但insert的表要和查的表结构一致。
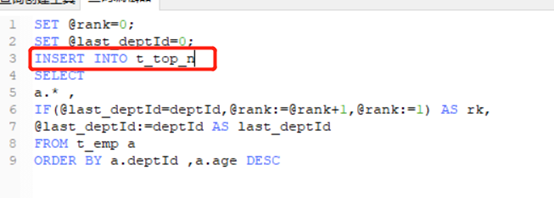
3、把上面两步封装成存储过程。

DELIMITER $$
CREATE PROCEDURE pro_top_n()
BEGIN
TRUNCATE TABLE t_top_n;
SET @rank=0;
SET @last_deptId=0;
INSERT INTO t_top_n
SELECT
a.* ,
IF(@last_deptId=deptId,@rank:=@rank+1,@rank:=1) AS rk,
@last_deptId:=deptId AS last_deptId
FROM t_emp a
ORDER BY a.deptId ,a.age DESC;
END$$
5、 调用存储过程:
CALL pro_top_n();
小结:此存储过程1、将数据表清空,2将新数据更新到数据表中。
2、2完成定时刷新任务
2.2.1定时器默认关闭,需要打开。
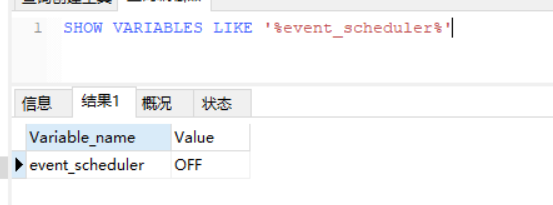
SHOW VARIABLES LIKE '%event_scheduler%';
SET GLOBAL event_scheduler=1;
2.2.2 创建事件,定时去执行存储过程

DELIMITER $$
CREATE EVENT ev_top_flush
ON SCHEDULE
EVERY 1 MINUTE
ON COMPLETION PRESERVE
ENABLE
DO
BEGIN
CALL pro_top_n();
END$$
总结:事件一般用于报表。
3、定时备份
问题:每天凌晨2点备份某个数据库脚本,以年月为目录,年月日为文件名,存到某个目录下。
解决:
1、 备份数据脚本。备份工具mysqldump
2、 存储到指定的目录和文件中。
3、 定时执行。
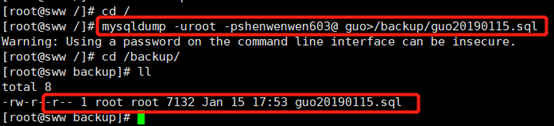
3.1登录mysqldump
格式:mysqldump –u[用户名] –p[密码] [要导出的数据库]>[导出的文件.sql]
例如:mysqldump -uroot -pshenwenwen603@ guo>/backup/guo20190115.sql
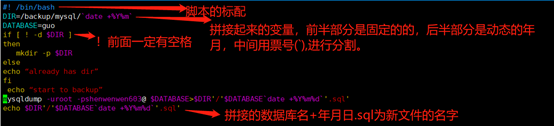
3.2 shell脚本
格式:
#! /bin/bash
DIR=/backup/mysql/`date +%Y%m`
DATABASE=guo
If [ ! -d $DIR ]
then
mkdir -p $DIR
else
echo “already has dir”
fi
echo “start to backup”
mysqldump -uroot -pshenwenwen603@ $DATABASE>$DIR'/'$DATABASE`date +%Y%m%d`'.sql'
echo $DIR'/'$DATABASE`date +%Y%m%d`'.sql'
3.2 linux提供的定时 ——>
Crond[s1] service crond start service crond status

4、主从复制
主机版本不能高于从机版本
主写从读
1、 每个从机只能有一个mast
2、 每个从机只能有一个唯一的服务器id(service_id默认唯一,不能重复)
3、 每个主机可以有多个从机
https://www.cnblogs.com/superfat/p/5267449.html
42
Mycat 1、读写分离 2、数据分片 3、多数据源整合
4、1、1读写分离
关系图
1、 安装
下载、上传、解压缩就可以。(注意:解压缩之后,不能立即启动,需要修改三个配置文件,即:1、schema.xml(最为重要的,路由的规则就配置在这个里面),2、server.xml(配置用户名、密码等的参数配置)3、rule.xml(分表的规则))
2、 schema.xml配置
3、server.xml
3、 启动mycat.
在/user/local/mycat/bin目录下面,执行./mycat console 启动mycat
4、 在linux下面使用mycat登录mysql数据库。
Mysql –uroot –pshenwenwen603@ -h127.0.0.1 –P8066(注意:p必须为大写)
Show databases;
Show tables;
Insert一条数据,名字用@@hostname,最后可以查看是从哪个服务器写进去的,例如:insert into mydb1 values(3,@@hostname);
则证明,是从写库写入的。
4、2分库
数据量很大的情况下需要分库操作
4、2、1 schemer.xml配置
4、2、2数据集市(数据仓库)
问题:若出现不同库之间的表需要进行关联查询,则mycat不支持。
数据集市就是将不同的库中的数据都抽取出来,放在数据集市上进行操作。
当数据达到上百万需要。
5、 分表
根据时间、地区、id(取模)、
5.1.1Rule配置
5.1.2schmer.xml配置
5.2分表之垮裤关联
5.2.1字表根据父表生成
5.2.2全局分表:
全局gloable就是每个表都有,要做一起做。
全局序列号生成规则,以防止两边的表生成的id号是一样的。
mycat三种解决方案
1、 本地文件
2、 数据库方式
3、 时间戳(18位)
公式:NEXT VALUE FOR MYCATSEQ_GLOBAL
4、利用redis的计数器
5.2.3全局分表:
假如一个库中没有需要的表,则关联的时候会报错,需要有一个虚拟的表,则需要在配置中打开引擎。
1、vim /etc/my.cnf
2、
3、创建虚拟表
CREATE TABLE dict_order_type(
id INT AUTO_INCREMENT,
order_type VARCHAR(200),
PRIMARY KEY(id)
)ENGINE=FEDERATED CONNECTION="mysql://root:shenwenwen603@39.106.140.104:3306/orders_0706/customer"
之后再进行关联就没任何问题。