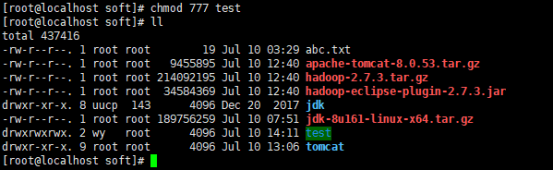
配置权限是
R w x
1 0 1
的用法是转化为二级制。是5
777位三段都是满权限
解压指令:tar -zxvf 文件名 tar -czvf是压缩
解压jdk并且进行重命名

放在profile.d中

输入命令差生脚本文件Vi java.sh
Export是把临时变量变为系统变量。
$$是把包含其中的系统变量内容进行引用,然后在改变系统变量的时候调用以前的加上现在需要增加的,再进行覆盖,就不会丢失之前的系统变量
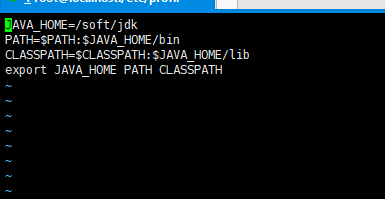
执行脚本文件修改系统变量

显示如下则jdk配置成功

yum install 意思是:下载并安装
yum install -y mysql mysql-server 完全安装后结果如下

启动数据库服务
Service mysqld start

设置mysql的用户名密码

完全关闭防火墙如下操作(前面一句是当时关掉重启会重新打开,第二句是重启后不开启,所以两句都需要输入一遍)

登录mysql

Show tables;

Select
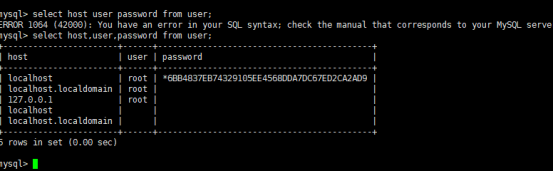
删除无用用户
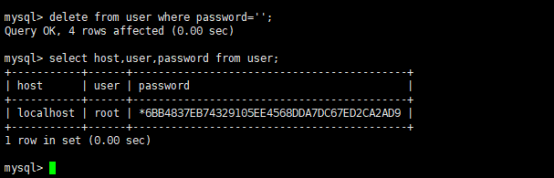
更改用户名通配符
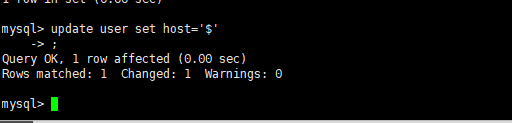
问题:这里还是连接不上,原因是$不是通配符,应该把它换成%这个。就可以成功连接了
刷新权限


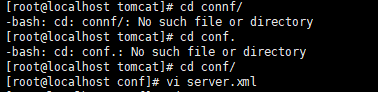
Linux配置tomcat
解压下载的tomcat

进入tomcat文件夹
问题:cd /tomcat进不去,必须输入cd tomcat/才能进入
进入bin开启tomcat

修改端口号(方便以后不用再IP上输入:8080才能显示tomcat官网)
找到这里修改为80即可

对于登录tomcat官网。
可以进行如下配置
在conf中的
添加彩色的这些话

重新关闭开启tomcat服务即可
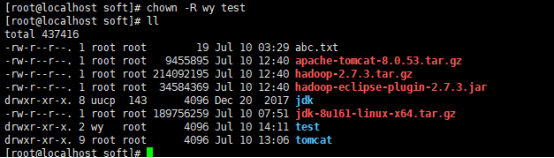
权限分配
重新创建文件夹test

创建用户组wy
将用户wy放入用户组

绝对路径查找

给用户wy设置密码
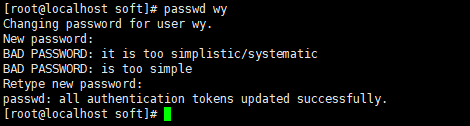
更改权限所属
Test归属wy
权限更改
Ssh安装配置过程
下载安装

安装完成
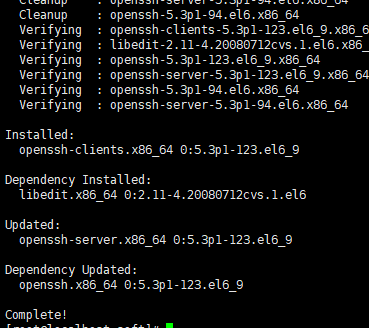
输入ssh+IP地址
进行秘钥连接,连接成功如下
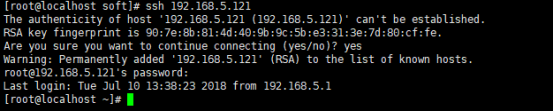
会生成ssh隐藏目录
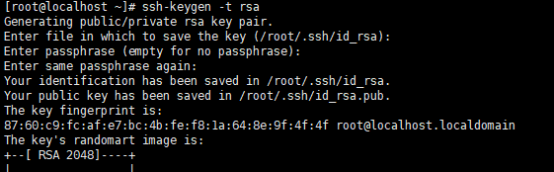

免秘钥登录
通过复制id_rsa.pub文件 为一个authorized_keys
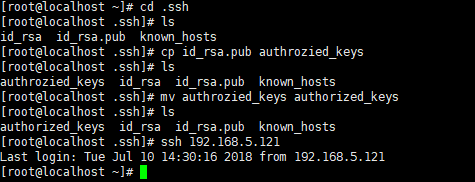
将一台IP的root - .ssh - 中的authorized_keys复制到另外一台中,即可实现
问题(复制过去的时候记得另起一行)
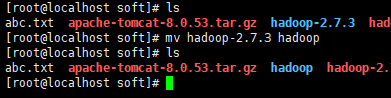
Hadoop安装配置过程
解压文件
。
进入cd /etc/profile.d/
编写脚本文件 vi hadoop.sh
内容如下

Source hadoop.sh执行脚本文件进行更改系统变
验证hadoop是否配置成功
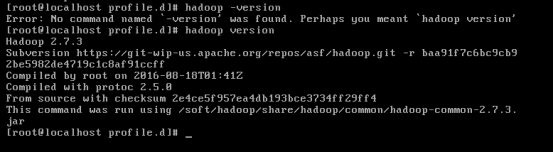
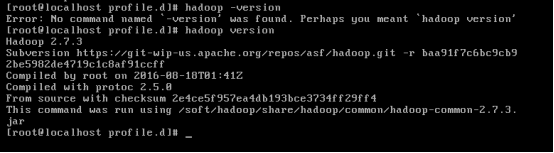
问题:在编写hadoop.sh时候,一不小心把PATH变量覆盖了,导致PATH出现错误,ls等指令无法使用。通过别人的初始环境PATH以及指令export PATH=********进行还原,再运行正确的java.sh 以及 hadoop.sh脚本文件完成对PATH的修复
技巧:虚拟机提前快照。之后可以进行回复到原先没有错误的情况
配置hdfs

Core-site配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.5.121:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmp</value>
</property>
</configuration>
Hdfs-site配置
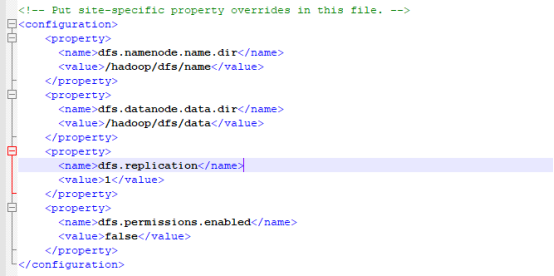
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
创建三个临时文件

Namenode格式化

进入sbin
开启hadoop
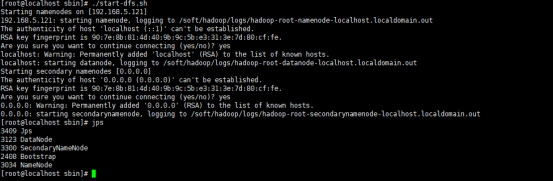
浏览器输入192.168.5.121:50070
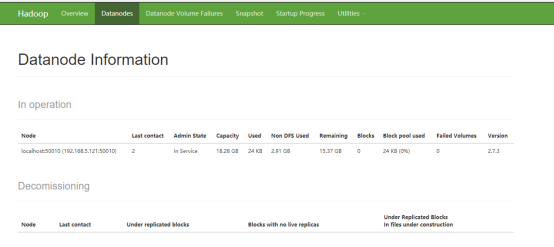
Hdfs创建一个文件

存进一个文件


