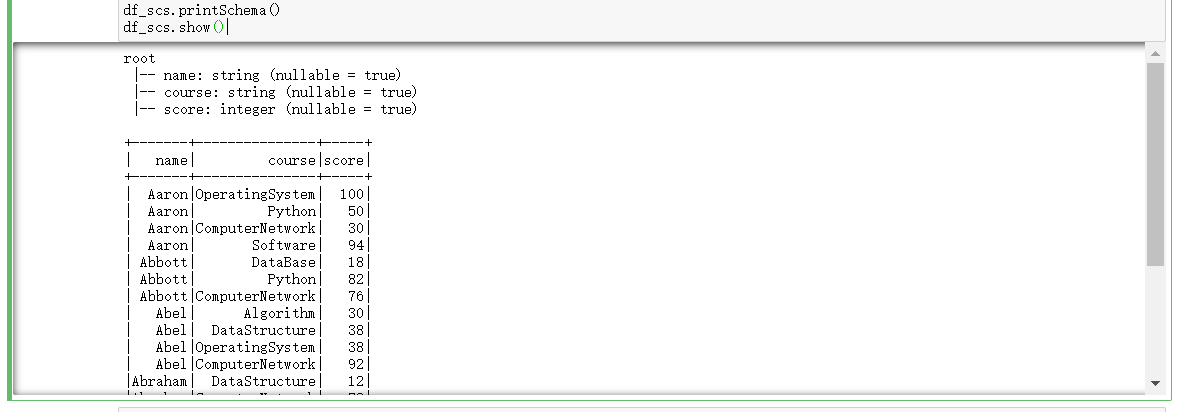
读学生课程分数文件chapter4-data01.txt,创建DataFrame。
url = "file:///D:/chapter4-data01.txt" rdd = spark.sparkContext.textFile(url).map(lambda line:line.split(',')) rdd.take(3) from pyspark.sql.types import IntegerType,StringType,StructField,StructType from pyspark.sql import Row #生成“表头” fields = [StructField('name',StringType(),True),StructField('course',StringType(),True),StructField('score',IntegerType(),True)] schema = StructType(fields) # 生成“表中的记录” data = rdd.map(lambda p:Row(p[0],p[1],int(p[2]))) # 把“表头”和“表中的记录”拼接在一起 df_scs = spark.createDataFrame(data,schema) df_scs.printSchema() df_scs.show()
一:用DataFrame的操作或SQL语句完成以下数据分析要求,并和用RDD操作的实现进行对比:
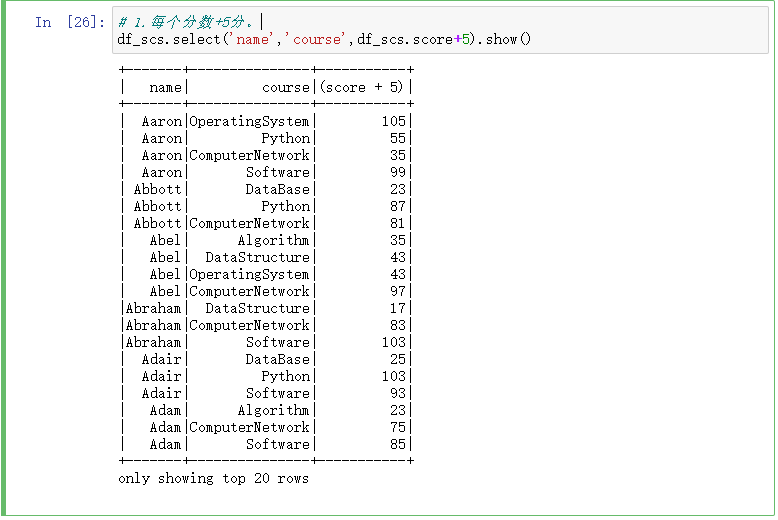
1.每个分数+5分。
# 1.每个分数+5分。 df_scs.select('name','course',df_scs.score+5).show()
2.总共有多少学生?
# 2.总共有多少学生? df_scs.select(df_scs.name).distinct().count() df_scs.select(df_scs['name']).distinct().count() df_scs.select('name').distinct().count()

3.总共开设了哪些课程?
# 3.总共开设了哪些课程? df_scs.select('course').distinct().show()

4.每个学生选修了多少门课?
# 4.每个学生选修了多少门课? df_scs.groupBy('name').count().show()

5.每门课程有多少个学生选?
# 5.每门课程有多少个学生选? df_scs.groupBy('course').count().show()

6.每门课程大于95分的学生人数?
# 6.每门课程大于95分的学生人数? df_scs.filter(df_scs.score>95).groupBy('course').count().show()

7.Tom选修了几门课?每门课多少分?
# 7.Tom选修了几门课?每门课多少分? df_scs.filter(df_scs.name=='Tom').show()

8.Tom的成绩按分数大小排序。
# 8.Tom的成绩按分数大小排序。 df_scs.filter(df_scs.name=='Tom').orderBy(df_scs.score).show()

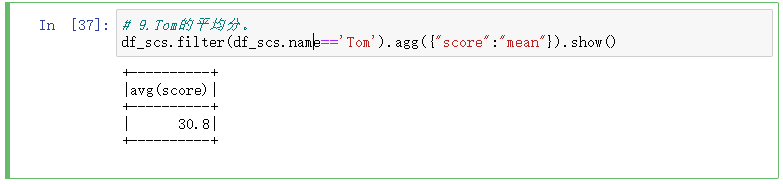
9.Tom的平均分。
# 9.Tom的平均分。 df_scs.filter(df_scs.name=='Tom').agg({"score":"mean"}).show()
10.求每门课的平均分,最高分,最低分。
# 10.求每门课的平均分,最高分,最低分。 df_scs.groupBy("course").agg({"score": "mean"}).show() df_scs.groupBy("course").agg({"score": "max"}).show() df_scs.groupBy("course").agg({"score": "min"}).show()

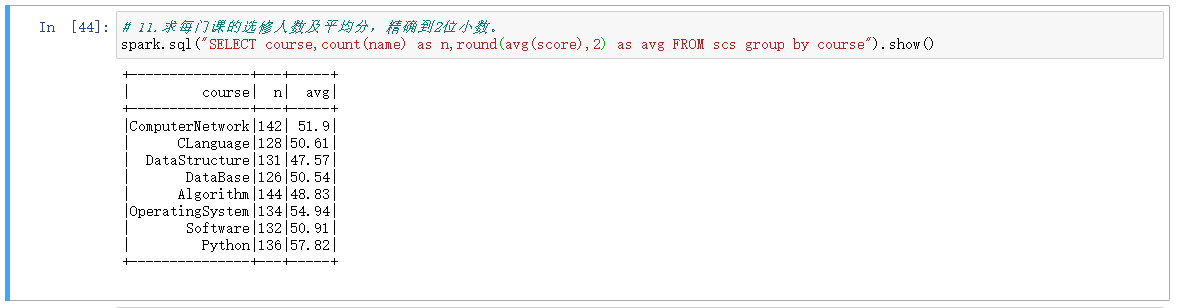
11.求每门课的选修人数及平均分,精确到2位小数。
# 11.求每门课的选修人数及平均分,精确到2位小数。 df_scs.select(countDistinct('name').alias('学生人数'),countDistinct('course').alias('课程数'),round(mean('score'),2).alias('所有课的平均分')).show()

12.每门课的不及格人数,通过率
# 12.每门课的不及格人数,通过率 df_scs.filter(df_scs.score<60).groupBy('course').count().show()

13.结果可视化。
二、用SQL语句完成以上数据分析要求
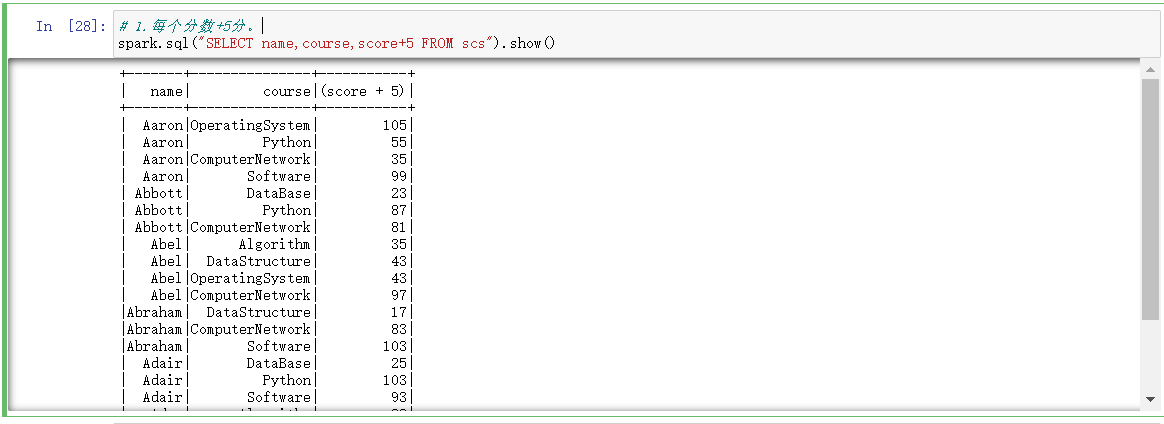
1.每个分数+5分。
# 1.每个分数+5分。 spark.sql("SELECT name,course,score+5 FROM scs").show()
2.总共有多少学生?
# 2.总共有多少学生? spark.sql("SELECT course,count(name) as n FROM scs group by course").show()

3.总共开设了哪些课程?
# 3.总共开设了哪些课程? spark.sql("SELECT course FROM scs group by course").show()

4.每个学生选修了多少门课?
# 4.每个学生选修了多少门课? spark.sql("SELECT name,count(course) FROM scs group by name").show()

5.每门课程有多少个学生选?
# 5.每门课程有多少个学生选? spark.sql("SELECT course,count(name) FROM scs group by course").show()

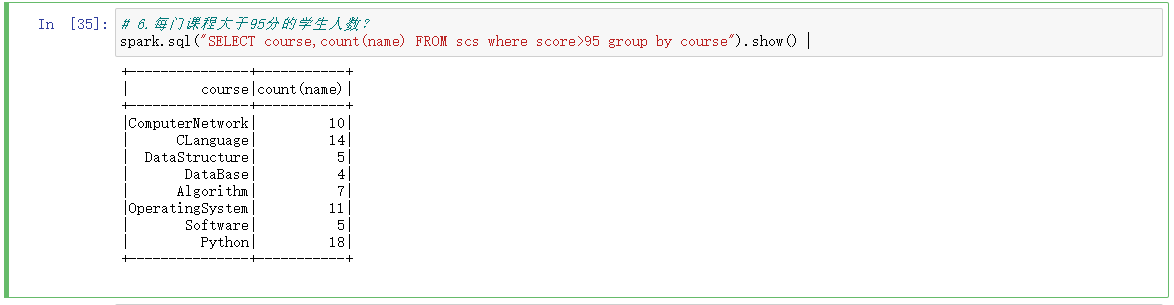
6.每门课程大于95分的学生人数?
# 6.每门课程大于95分的学生人数? spark.sql("SELECT course,count(name) FROM scs where score>95 group by course").show()
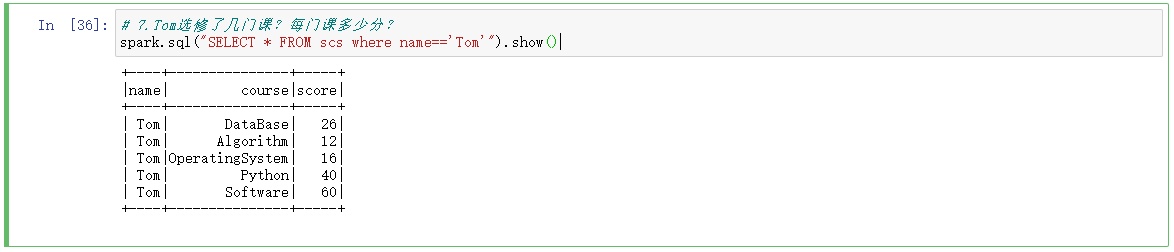
7.Tom选修了几门课?每门课多少分?
# 7.Tom选修了几门课?每门课多少分? spark.sql("SELECT * FROM scs where name=='Tom'").show()
8.Tom的成绩按分数大小排序。
# 8.Tom的成绩按分数大小排序。 spark.sql("SELECT * FROM scs where name=='Tom' order by score desc").show()

9.Tom的平均分。
# 9.Tom的平均分。 spark.sql("SELECT avg(score) as avg FROM scs where name=='Tom'").show()

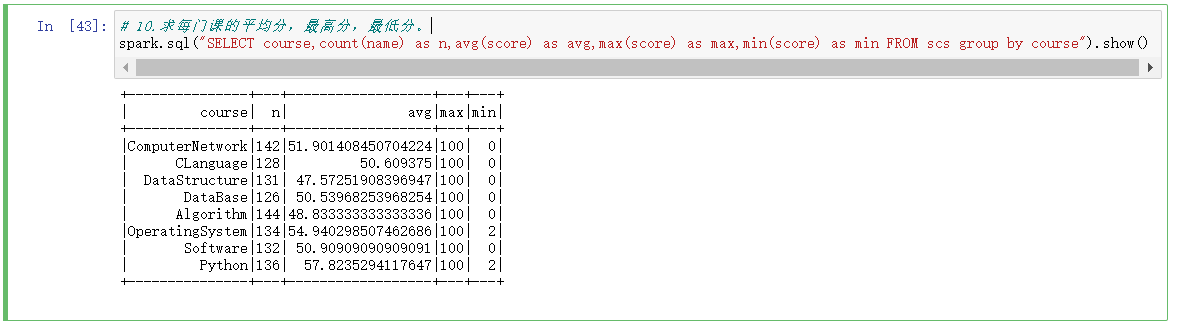
10.求每门课的平均分,最高分,最低分。
# 10.求每门课的平均分,最高分,最低分。 spark.sql("SELECT course,count(name) as n,avg(score) as avg,max(score) as max,min(score) as min FROM scs group by course").show()
11.求每门课的选修人数及平均分,精确到2位小数。
# 11.求每门课的选修人数及平均分,精确到2位小数。 spark.sql("SELECT course,count(name) as n,round(avg(score),2) as avg FROM scs group by course").show()

12.每门课的不及格人数,通过率
# 12.每门课的不及格人数,通过率 spark.sql("SELECT course,count(name) as n,avg(score) as avg FROM scs group by course").createOrReplaceTempView("a") spark.sql("SELECT course,count(score) as notPass FROM scs where score<60 group by course").createOrReplaceTempView("b") spark.sql("SELECT * from a left join b on a.course=b.course").show() spark.sql("select a.course,round(a.avg,2),b.notPass,round((a.n-b.notPass)/a.n,2) as passRat from a left join b on a.course=b.course").show()

三、对比分别用RDD操作实现、用DataFrame操作实现和用SQL语句实现的异同。(比较两个以上问题)
例如:每门课的选修人数与平均分
1.RDD实现
# 方法一 combineByKey() course = words.combineByKey(lambda v:(int(v),1),lambda c,v:(c[0]+int(v),c[1]+1),lambda c1,c2:(c1[0]+c2[0],c1[1]+c2[1])) #每门课的选修人数及所有人的总分。combineByKey() course.map(lambda x:(x[0],x[1][1],round(x[1][0]/x[1][1],2))).collect() #每门课的选修人数及平均分,精确到2位小数。 #方法二 reduceByKey() lines.map(lambda line:line.split(',')).map(lambda x:(x[1],(int(x[2]),1))).reduceByKey(lambda a,b:(a[0]+b[0],a[1]+b[1])).collect()

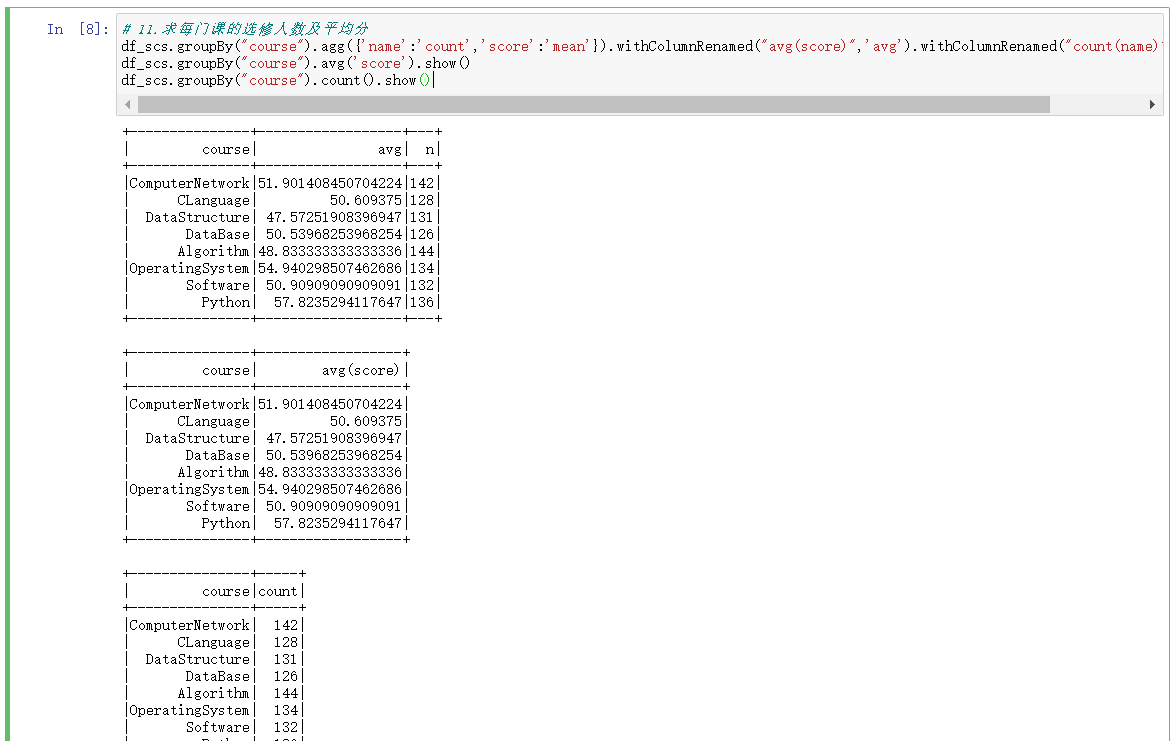
2.DataFrame实现
df_scs.groupBy("course").agg({'name':'count','score':'mean'}).withColumnRenamed("avg(score)",'avg').withColumnRenamed("count(name)",'n').show() df_scs.groupBy("course").avg('score').show() df_scs.groupBy("course").count().show()
3.SQL语句
spark.sql("SELECT course,count(name) as n,avg(score) as avg FROM scs group by course").show()
四、结果可视化。
函数:http://spark.apache.org/docs/2.2.0/api/python/pyspark.sql.html#module-pyspark.sql.functions