【groupByKey & reduceBykey 的区别】
在都能实现相同功能的情况下优先使用 reduceBykey
Combine 是为了减少网络负载
1. groupByKey 是没有 Combine 过程,可以改变 V 的类型
List[]
combineByKeyWithClassTag[CompactBuffer[V]](createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
2. reduceByKey 有 Combine 过程,不能改变 V 的类型
List[]
combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
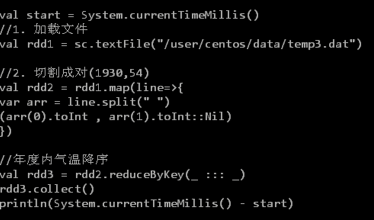
【通过测试气温数据的双排序考察 reduceByKey 和 groupByKey() 的不同】
1.启动 Hadoop 和 Spark 集群
2.上传 temp.txt 数据到 HDFS
3.启动 Shell 进行以下操作
【启动 Shell】
spark-shell --master spark://s101:7077 --deploy-mode client
【test_1】

【test_2】