1. Spark 基本概念
1.1 简介
Spark 是用于大规模数据处理的快如闪电的统一分析引擎。
1.2 速度
Spark 可以获得更高的性能,针对 batch 计算和流计算都可以。
用到了 DAG scheduler (有向无环图调度器)、查询优化器、物理执行引擎
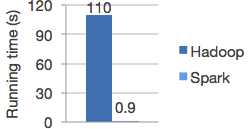
同 Hadoop 进行逻辑回归测试,Spark 速度超过 Hadoop 100x 倍。
1.3 易用性
Spark 提供了 80+ 个高级算子,可以轻松构建并行 app
支持多种语言,Java、Scala、Python、R 和 SQL shell
1.4 通用性
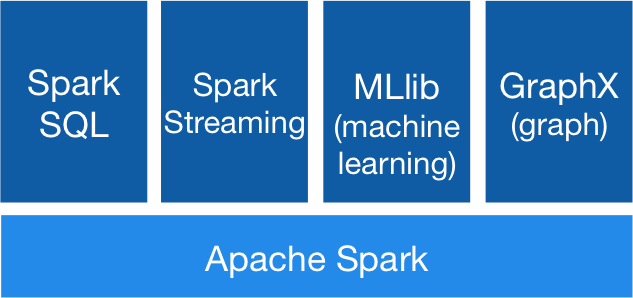
Spark 有5大模块,Core 、SQL 、Streaming 、MLlib 、GraphX
可以对 SQL 和 Streaming 以及复杂分析进行组合应用。
1.5 执行场景
spark可以运行在 Hadoop 、Mesos 、standalone 、云上。
可以访问多种数据源。

2. 安装 Spark
2.1 解压
tar -xzvf spark-2.1.0-bin-hadoop2.7.tgz -C /soft/
2.2 创建符号链接
ln -s /soft/spark-2.1.0-bin-hadoop2.7 /soft/spark
2.3 配置环境变量
# 编辑环境变量配置文件
sudo vi /etc/profile
# spark 环境变量 export SPARK_HOME=/soft/spark export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
2.4 生效环境变量
source /etc/profile
2.5 启动 spark shell
【启动前提】
# 启动 ZooKeeper 集群 xzk.sh start # 启动 HDFS start-dfs.sh # 启动 Spark 服务,在 spark/sbin 目录下执行 ./start-all.sh
【启动】
[centos@s101 /soft/spark/bin]$ spark-shell