1、什么是文档?
程序中大多的实体或对象能够被序列化为包含键值对的JSON对象,键(key)是字段(field)或属性(property)的名字,值(value)可以是字符串、数字、布尔类型、另一个对象、值数组或者其他特殊类型,
比如表示日期的字符串或者表示地理位置的对象。

通常,我们可以认为对象(object)和文档(document)是等价相通的。不过,他们还是有所差别:对象(Object)是一个JSON结构体——类似于哈希、hashmap、字典或者关联数组;
对象(Object)中还可能包含其他对象(Object)。 在Elasticsearch中,文档(document)这个术语有着特殊含义。它特指最顶层结构或者根对象(root object)序列化成的JSON数据(以唯一ID标识并存储于Elasticsearch中)。
2、文档元数据
一个文档不只有数据。它还包含了元数据(metadata)——关于文档的信息。三个必须的元数据节点是:
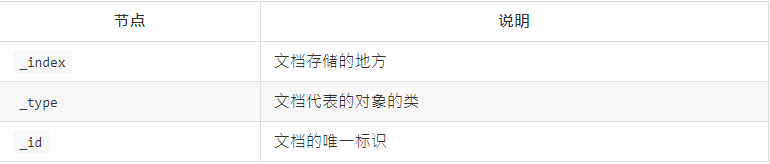
2.1、_index
索引(index)类似于关系型数据库里的“数据库”——它是我们存储和索引关联数据的地方。
事实上,我们的数据被存储和索引在分片(shards)中,索引只是一个把一个或多个分片分组在一起的逻辑空间。然而,这只是一些内部细节——我们的程序完全不用关心分片。
对于我们的程序而言,文档存储在索引(index)中。剩下的细节由Elasticsearch关心既可。
索引名。这个名字必须是全部小写,不能以下划线开头,不能包含逗号。让我们使用website做为索引名。
2.2、type
在应用中,我们使用对象表示一些“事物”,例如一个用户、一篇博客、一个评论,或者一封邮件。每个对象都属于一个类(class),这个类定义了属性或与对象关联的数据。
user类的对象可能包含姓名、性别、年龄和Email地址。
在关系型数据库中,我们经常将相同类的对象存储在一个表里,因为它们有着相同的结构。同理,在Elasticsearch中,我们使用相同类型(type)的文档表示相同的“事物”,因为他们的数据结构也是相同的。
每个类型(type)都有自己的映射(mapping)或者结构定义,就像传统数据库表中的列一样。所有类型下的文档被存储在同一个索引下,但是类型的映射(mapping)会告诉Elasticsearch不同的文档如何被索引。
_type的名字可以是大写或小写,不能包含下划线或逗号。我们将使用blog做为类型名。
2.3、_id
id仅仅是一个字符串,它与_index和_type组合时,就可以在Elasticsearch中唯一标识一个文档。当创建一个文档,你可以自定义_id,也可以让Elasticsearch帮你自动生成。
3、索引一个文档
文档通过index API被索引——使数据可以被存储和搜索。但是首先我们需要决定文档所在。正如我们讨论的,文档通过其_index、_type、_id唯一确定。们可以自己提供一个_id,
或者也使用index API 为我们生成一个。
使用自己的ID
如果你的文档有自然的标识符(例如user_account字段或者其他值表示文档),你就可以提供自己的_id,使用这种形式的index API:

例如我们的索引叫做“mywebsite”,类型叫做“blog”,我们选择的ID是“123456”,那么这个索引请求就像这样:
PUT /mywebsite/blog/123456
{
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
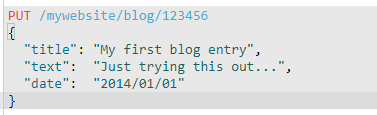
结果:
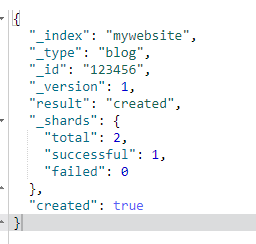
请求的索引已经被成功创建,这个索引中包含_index、_type和_id元数据,以及一个新元素:_version。
Elasticsearch中每个文档都有版本号,每当文档变化(包括删除)都会使_version增加。使用_version号确保你程序的一部分不会覆盖掉另一部分所做的更改。
自增ID
如果不指定ID,可以让Elasticsearch自动生成。请求结构发生了变化:
PUT方法——“在这个URL中存储文档”
POST方法——"在这个类型下存储文档"。
原来是把文档存储到某个ID对应的空间,现在是把这个文档添加到某个_type下。
POST /mywebsite/blog/
{
"title": "My second blog entry",
"text": "Still trying this out...",
"date": "2014/01/01"
}

内容与刚才类似,只有_id字段变成了自动生成的值:

4、检索文档
想要从Elasticsearch中获取文档,我们使用同样的_index、_type、_id,但是HTTP方法改为GET:
GET /mywebsite/blog/123456?pretty
响应包含了现在熟悉的元数据节点,增加了_source字段,它包含了在创建索引时我们发送给Elasticsearch的原始文档。
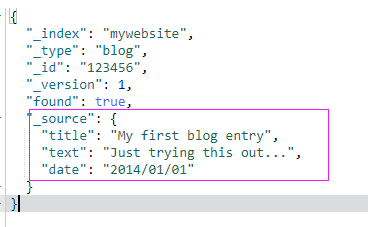
pretty
在任意的查询字符串中增加pretty参数,类似于上面的例子。会让Elasticsearch美化输出(pretty-print)JSON响应以便更加容易阅读。_source字段不会被美化,它的样子与我们输入的一致。
GET请求返回的响应内容包括{"found": true}。这意味着文档已经找到。如果我们请求一个不存在的文档,依旧会得到一个JSON,不过found值变成了false。
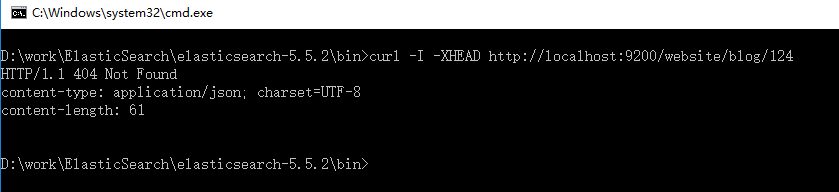
curl -i -XGET http://localhost:9200/website/blog/124?pretty
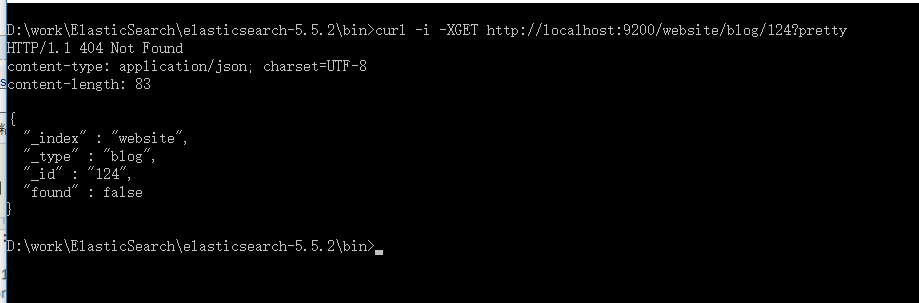
检索文档的一部分
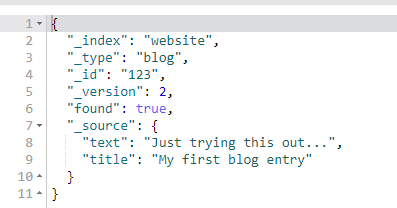
通常,GET请求将返回文档的全部,存储在_source参数中。但是可能你感兴趣的字段只是title。请求个别字段可以使用_source参数。多个字段可以使用逗号分隔:
GET /website/blog/123?_source=title,text
_source字段现在只包含我们请求的字段,而且过滤了date字段:
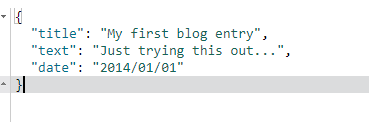
或者你只想得到_source字段而不要其他的元数据,你可以这样请求:
GET /website/blog/123/_source
5、检查文档是否存在
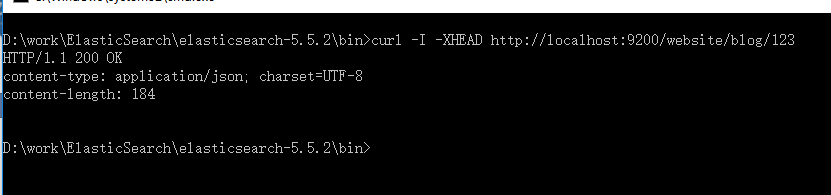
如果你想做的只是检查文档是否存在——你对内容完全不感兴趣——使用HEAD方法来代替GET。HEAD请求不会返回响应体,只有HTTP头:
curl -I -XHEAD http://localhost:9200/website/blog/123
或
HEAD /website/blog/123

如果不存在返回404 Not Found:
curl -I -XHEAD http://localhost:9200/website/blog/124
6、创建新文档
当我们索引一个文档, 怎么确认我们正在创建一个完全新的文档,而不是覆盖现有的呢?
请记住, _index 、 _type 和 _id 的组合可以唯一标识一个文档。所以,确保创建一个新文档的最简单办法是,使用索引请求的 POST 形式让 Elasticsearch 自动生成唯一 _id :
POST /website/blog/
{ ... }
然而,如果已经有自己的 _id ,那么我们必须告诉 Elasticsearch ,只有在相同的 _index 、 _type 和 _id 不存在时才接受我们的索引请求。这里有两种方式,他们做的实际是相同的事情。
使用哪种,取决于哪种使用起来更方便。
PUT /website/blog/123?op_type=create
{ ... }
第二种方法是在 URL 末端使用 /_create :
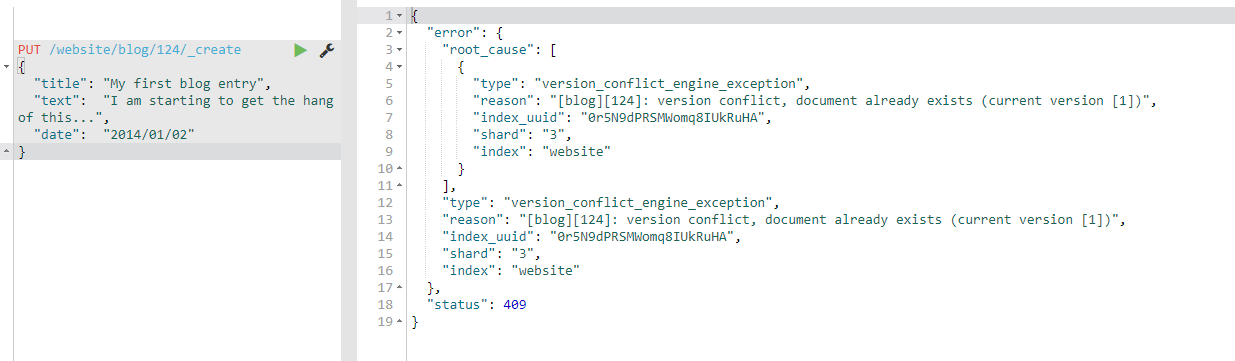
PUT /website/blog/123/_create
{ ... }
如果创建新文档的请求成功执行,Elasticsearch 会返回元数据和一个 201 Created 的 HTTP 响应码。
另一方面,如果具有相同的 _index 、 _type 和 _id 的文档已经存在,Elasticsearch 将会返回 409 Conflict 响应码,以及如下的错误信息:
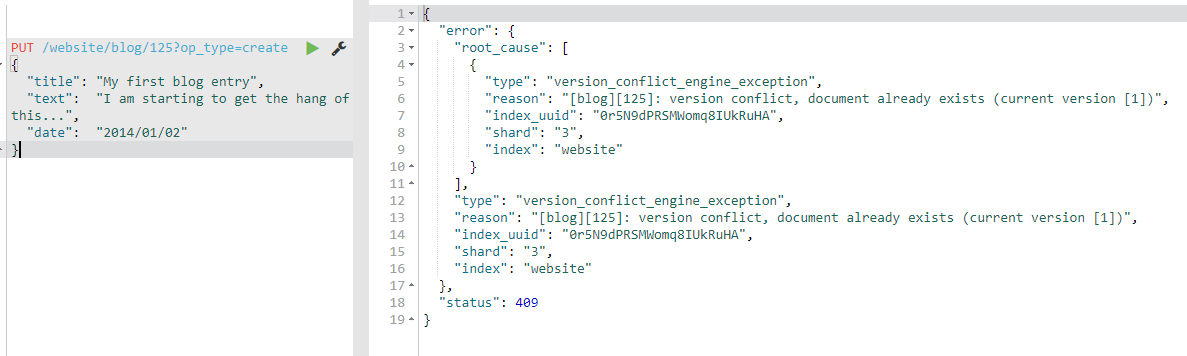
7、删除文档
删除文档 的语法和我们所知道的规则相同,只是 使用 DELETE 方法:
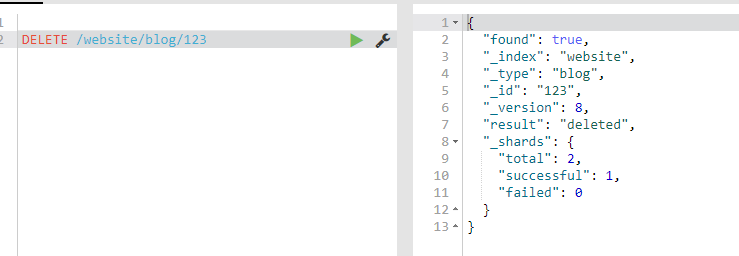
DELETE /website/blog/123
如果找到该文档,Elasticsearch 将要返回一个 200 ok 的 HTTP 响应码,和一个类似以下结构的响应体。注意,字段 _version 值已经增加:
{
"found" : true,
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 3
}
如果文档没有 找到,我们将得到 404 Not Found 的响应码和类似这样的响应体:
{
"found" : false,
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 4
}
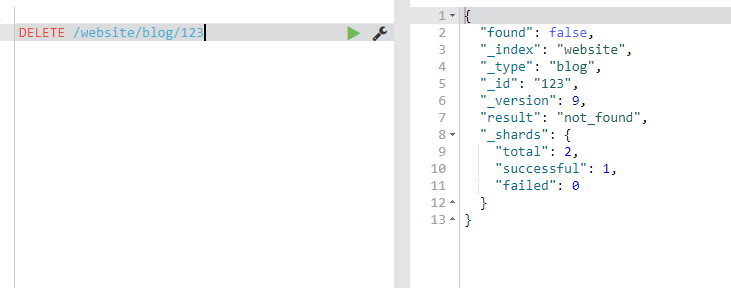
即使文档不存在( Found 是 false ), _version 值仍然会增加。这是 Elasticsearch 内部记录本的一部分,用来确保这些改变在跨多节点时以正确的顺序执行。
注意:删除文档不会立即将文档从磁盘中删除,只是将文档标记为已删除状态。随着你不断的索引更多的数据,Elasticsearch 将会在后台清理标记为已删除的文档。
8、文档的部分更新
使用 update API 可以部分更新文档,例如在某个请求时对计数器进行累加。
我们也介绍过文档是不可变的:他们不能被修改,只能被替换。 update API 必须遵循同样的规则。 从外部来看,我们在一个文档的某个位置进行部分更新。然而在内部,
update API 简单使用与之前描述相同的 检索-修改-重建索引 的处理过程。 区别在于这个过程发生在分片内部,这样就避免了多次请求的网络开销。通过减少检索和重建索引步骤之间的时间,
我们也减少了其他进程的变更带来冲突的可能性。
update 请求最简单的一种形式是接收文档的一部分作为 doc 的参数, 它只是与现有的文档进行合并。对象被合并到一起,覆盖现有的字段,增加新的字段。
例如,我们增加字段 tags 和 views 到我们的博客文章,如下所示:
首先建一个文档
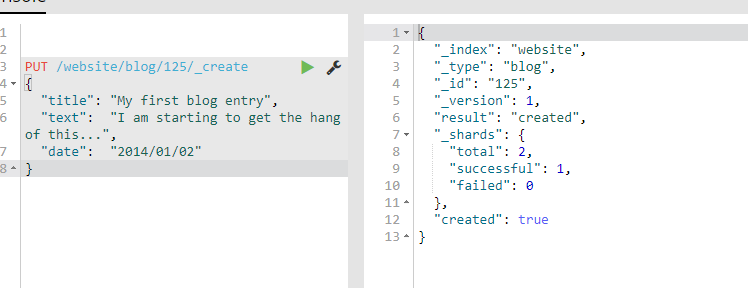
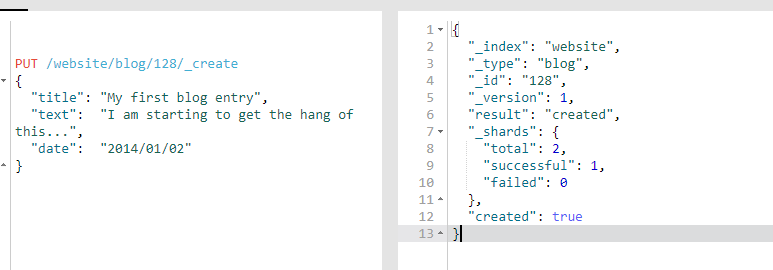
PUT /website/blog/128/_create
{
"title": "My first blog entry",
"text": "I am starting to get the hang of this...",
"date": "2014/01/02"
}
然后更新文档
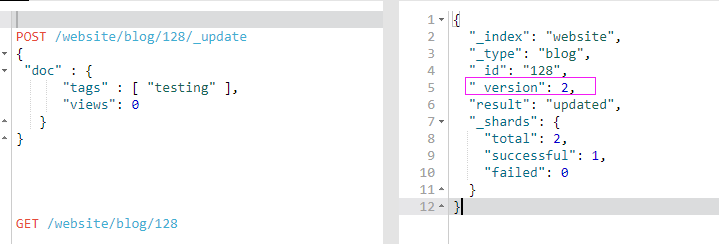
POST /website/blog/128/_update
{
"doc" : {
"tags" : [ "testing" ],
"views": 0
}
}
检索更新后的文档:
GET /website/blog/128

9、取回多个文档
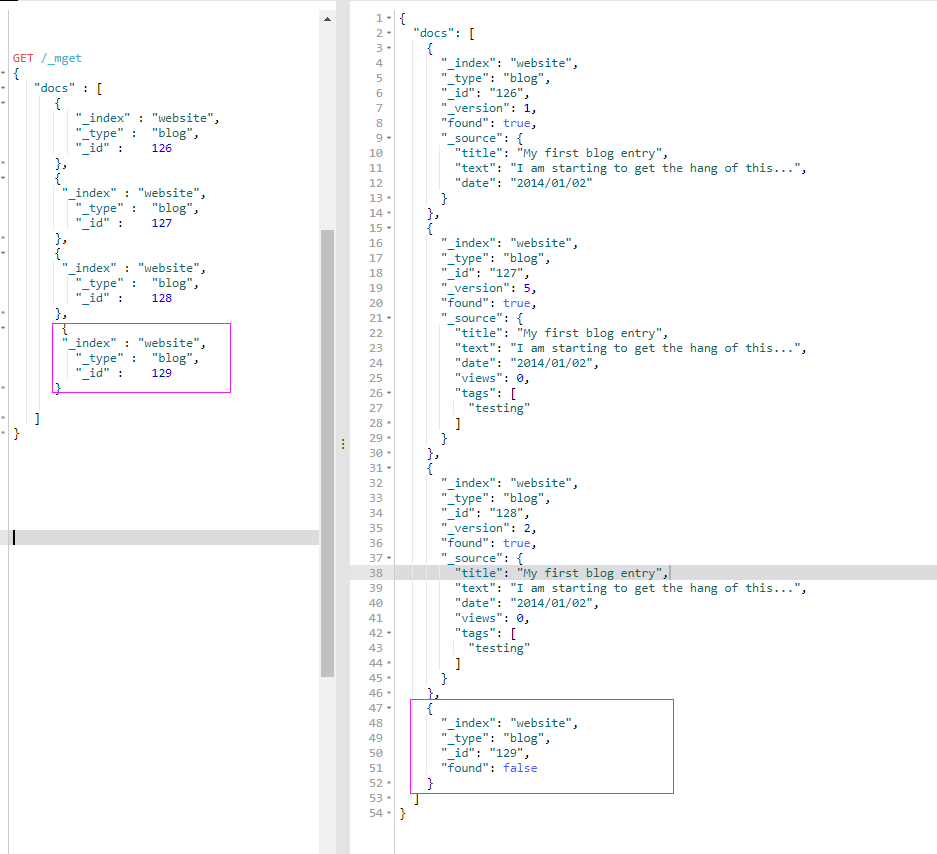
如果你需要从 Elasticsearch 检索很多文档,那么使用 multi-get 或者 mget API 来将这些检索请求放在一个请求中,将比逐个文档请求更快地检索到全部文档。
mget API 要求有一个 docs 数组作为参数,每个 元素包含需要检索文档的元数据, 包括 _index 、 _type和 _id 。如果你想检索一个或者多个特定的字段,那么你可以通过 _source 参数来指定这些字段的名字
_id为129的文档没有找到并不妨碍第一个文档被检索到。每个文档都是单独检索和报告的.
如果想检索的数据都在相同的 _index 中(甚至相同的 _type 中),则可以在 URL 中指定默认的 /_index或者默认的 /_index/_type 。
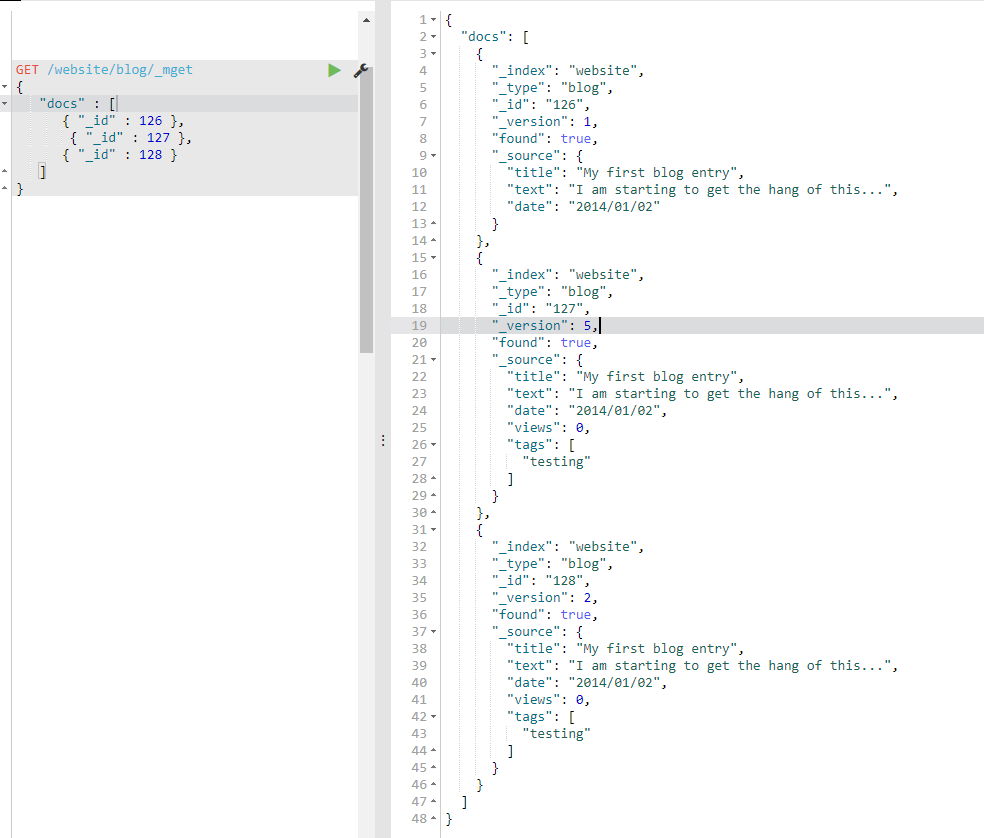
事实上,如果所有文档的 _index 和 _type 都是相同的,你可以只传一个 ids 数组,而不是整个 docs 数组:

10、代价较小的批量操作
bulk API 允许在单个步骤中进行多次 create 、 index 、 update 或 delete 请求。 如果你需要索引一个数据流比如日志事件,它可以排队和索引数百或数千批次。
bulk 与其他的请求体格式稍有不同,如下所示:
{ action: { metadata }}
{ request body }
{ action: { metadata }}
{ request body }
...
这种格式类似一个有效的单行 JSON 文档 流 ,它通过换行符(
)连接到一起。注意两个要点:
1、每行一定要以换行符(
)结尾, 包括最后一行 。这些换行符被用作一个标记,可以有效分隔行。
2、这些行不能包含未转义的换行符,因为他们将会对解析造成干扰。这意味着这个 JSON 不 能使用 pretty 参数打印。
action/metadata 行指定 哪一个文档 做 什么操作 。
metadata 应该 指定被索引、创建、更新或者删除的文档的 _index 、 _type 和 _id 。
例如,一个 delete 请求看起来是这样的:
{ "delete": { "_index": "website", "_type": "blog", "_id": "128" }}
request body 行由文档的 _source 本身组成--文档包含的字段和值。它是 index 和 create 操作所必需的,这是有道理的:你必须提供文档以索引。
它也是 update 操作所必需的,并且应该包含你传递给 update API 的相同请求体: doc 、 upsert 、 script 等等。 删除操作不需要 request body 行。
POST /_bulk { "delete": { "_index": "website", "_type": "blog", "_id": "126" }} { "create": { "_index": "website", "_type": "blog", "_id": "126" }} { "title": "My first blog post1" } { "index": { "_index": "website", "_type": "blog" }} { "title": "My second blog post1" } { "update": { "_index": "website", "_type": "blog", "_id": "128", "_retry_on_conflict" : 3} } { "doc" : {"title" : "My updated blog post"} }
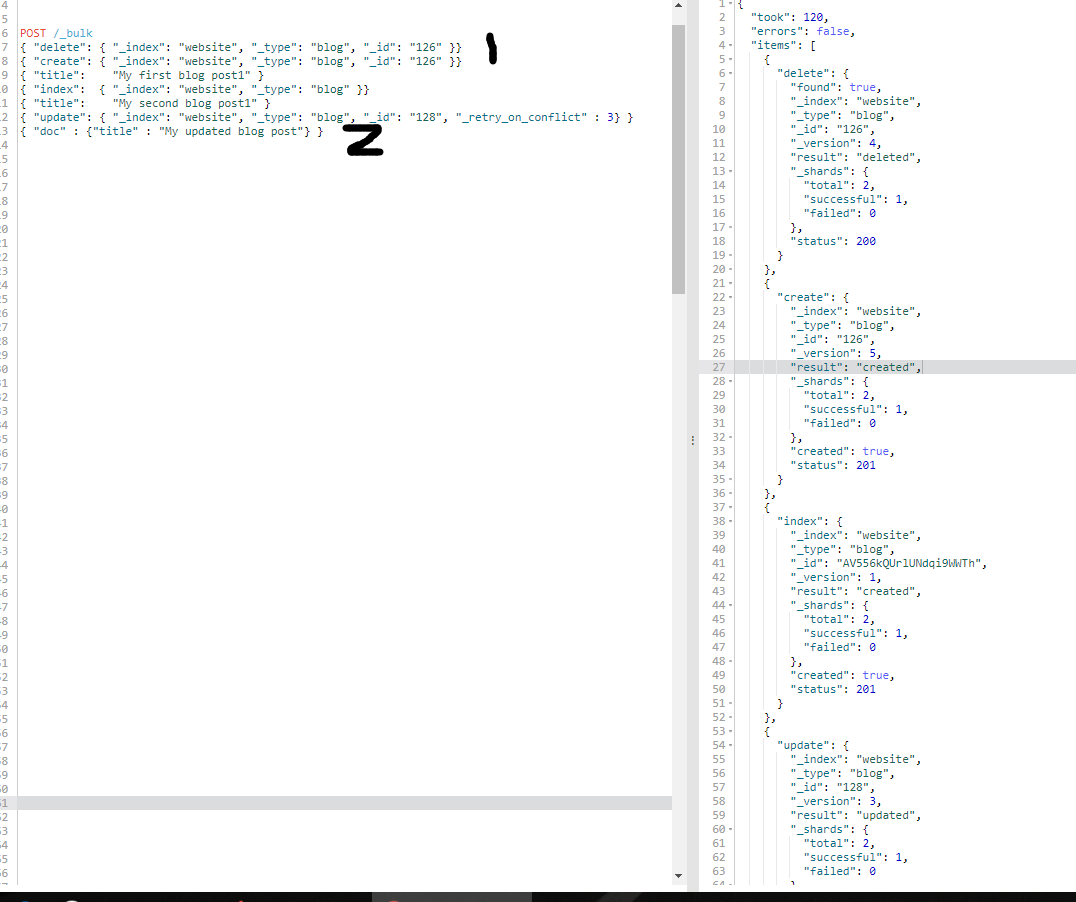
请注意 :1、delete 动作不能有请求体,它后面跟着的是另外一个操作。
2、谨记最后一个换行符不要落下。
3、 bulk 请求不是原子的, 不能用它来实现事务控制。每个请求是单独处理的,因此一个请求的成功或失败不会影响其他的请求。
这个 Elasticsearch 响应包含 items 数组, 这个数组的内容是以请求的顺序列出来的每个请求的结果。

'404 Not Found'代替'200 OK'。我们可以在curl后加-i参数得到响应头: