最近在公司内部的分享交流会上,有幸听到了鸟哥的关于php底层的一些算法的分享,虽然当时有些问题没有特别的明白,但是会后,查阅了各种各样的相关资料,对php的一些核心的hash算法有了进一步的理解和认识,下面就是总结下自己梳理的一些hash算法的点。
首先,大致的了解下php中的hash算法的应用,引用一些鸟哥博客中的话:
HashTable是php的核心,这话一点也不假。 PHP的Hash采用的是目前最为普遍的DJBX33A (Daniel J. Bernstein, Times 33 with Addition), 这个算法被广泛运用与多个软件项目,Apache, Perl和Berkeley DB等. 对于字符串而言这是目前所知道的最好的哈希算法,原因在于该算法的速度非常快,而且分类非常好(冲突小,分布均匀). 主要的核心思想是: hash(i) = hash(i-1)*33 + str[i] 并且这个算法的初始值是5381,而其他的算法(apache的times算法以及perl的hash算法,初始值都是0),但为啥是这个值,鸟哥的说法是: Magic Constant 5381: 1. odd number 2. prime number 3. deficient number 4. 001/010/100/000/101 b 对第3,4点理解还是不够透彻,希望可以在研究下。 至于说, 为什么是Times 33而不是Times 其他数字, 在PHP Hash算法的注释中也有一些说明, 希望对有兴趣的同学有用: DJBX33A (Daniel J. Bernstein, Times 33 with Addition) This is Daniel J. Bernstein's popular `times 33' hash function as posted by him years ago on comp.lang.c. It basically uses a function like ``hash(i) = hash(i-1) * 33 + str[i]''. This is one of the best known hash functions for strings. Because it is both computed very fast and distributes very well. The magic of number 33, i.e. why it works better than many other constants, prime or not, has never been adequately explained by anyone. So I try an explanation: if one experimentally tests all multipliers between 1 and 256 (as RSE did now) one detects that even numbers are not useable at all. The remaining 128 odd numbers (except for the number 1) work more or less all equally well. They all distribute in an acceptable way and this way fill a hash table with an average percent of approx. 86%. If one compares the Chi^2 values of the variants, the number 33 not even has the best value. But the number 33 and a few other equally good numbers like 17, 31, 63, 127 and 129 have nevertheless a great advantage to the remaining numbers in the large set of possible multipliers: their multiply operation can be replaced by a faster operation based on just one shift plus either a single addition or subtraction operation. And because a hash function has to both distribute good _and_ has to be very fast to compute, those few numbers should be preferred and seems to be the reason why Daniel J. Bernstein also preferred it. -- Ralf S. Engelschall <rse@engelschall.com>
其次,总结下什么情况下会出现hash的碰撞以及出现的原因:
因为php的数组以及各种对象类型底层都是转换成hash,来进行处理的,因此可以模拟数组的构造,来制造冲突的实例:
1 <?php 2 $size = pow(2, 16); 3 4 $startTime = microtime(true); 5 $array = array(); 6 for ($key = 0, $maxKey = ($size - 1) * $size; $key <= $maxKey; $key += $size) { 7 $array[$key] = 0; 8 } 9 $endTime = microtime(true); 10 echo '插入 ', $size, ' 个恶意的元素需要 ', $endTime - $startTime, ' 秒', " "; 11 12 $startTime = microtime(true); 13 $array = array(); 14 for ($key = 0, $maxKey = $size - 1; $key <= $maxKey; ++$key) { 15 $array[$key] = 0; 16 } 17 $endTime = microtime(true); 18 echo '插入 ', $size, ' 个普通元素需要 ', $endTime - $startTime, ' 秒', " ";
最终的结果是:
插入 65536 个恶意的元素需要 43.1438360214 秒
插入 65536 个普通元素需要 0.0210378170013 秒
从上个例子中,可以看出,对数组的键值进行特殊的构造,使得php的每一次插入都造成了hash冲突,从而使php的array的hash迅速的退化成为链表。这就造成了hash的碰撞冲突。下面是鸟哥博客中的一个图片:
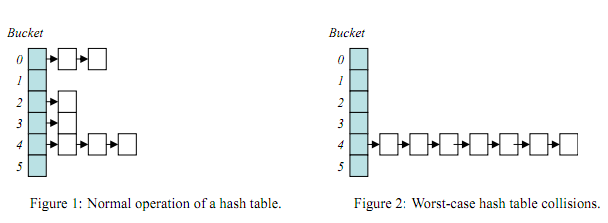
hash collison
1 那么, 这个键值是怎么构造的呢? 2 3 在PHP中,如果键值是数字, 那么Hash的时候就是数字本身, 一般的时候都是, index & tableMask. 而tableMask是用来保证数字索引不会超出数组可容纳的元素个数值, 也就是数组个数-1. 4 5 PHP的Hashtable的大小都是2的指数, 比如如果你存入10个元素的数组, 那么数组实际大小是16, 如果存入20个, 则实际大小为32, 而63个话, 实际大小为64. 当你的存入的元素个数大于了数组目前的最多元素个数的时候, PHP会对这个数组进行扩容, 并且从新Hash. 6 7 现在, 我们假设要存入64个元素(中间可能会经过扩容, 但是我们只需要知道, 最后的数组大小是64, 并且对应的tableMask为63:0111111), 那么如果第一次我们存入的元素的键值为0, 则hash后的值为0, 第二次我们存入64, hash(1000000 & 0111111)的值也为0, 第三次我们用128, 第四次用192… 就可以使得底层的PHP数组把所有的元素都Hash到0号bucket上, 从而使得Hash表退化成链表了.
上述的这种情况就造成了hash 的碰撞冲突。那么黑客可以利用这些语言上的这个hash漏洞来进行构造出一些特别的键值对,对服务器进行攻击,导致服务器的带宽占满,服务器的cpu剧增,从而导致网站瘫痪。
那怎样,避免这种情况的发生,以及哪种语言版本是可以避免攻击的?
先说下php,php >= 5.3.9, >= 5.4.0RC4的版本是不受影响的,其余皆受影响。在不受影响的版本中,只是多增加了一个max_input_vars这个参数来进行防止的,简单的来说就是限制客户端post过来的数据,这是一种治标不治本的方法。
以上的都是一些自己从大牛博客上的一些总结,以及自己的一些理解!