基础数据类型的总结
按存储空间的占用分(从低到高)
数字 字符串 集合:无序,即无序存索引相关信息 元组:有序,需要存索引相关信息,不可变 列表:有序,需要存索引相关信息,可变,需要处理数据的增删改 字典:有序,需要存key与value映射的相关信息,可变,需要处理数据的增删改(3.6之后有序)
按存值个数区分
| 标量/原子类型 | 数字 |
| 容器类型 | 字符串,列表,元组,字典 |
按可变不可变区分
| 可变 | 列表,字典,集合 |
| 不可变 | 数字,字符串,元组,布尔值 |
按访问顺序区分
| 直接访问 | 数字 |
| 顺序访问(序列类型) | 字符串,列表,元组 |
| key值访问(映射类型) | 字典 |
其他,set
四. 编码的进阶
前两天咱们已经讲了编码,我相信大家对编码有一定的了解了,那么,咱们先回顾一下:
首先来说,编码即是密码本,编码记录的就是二进制与文字之间的对应关系,现存的编码本有:
ASCII码:包含英文字母,数字,特殊字符与01010101对应关系。
a 01000001 一个字符一个字节表示。
GBK:只包含本国文字(以及英文字母,数字,特殊字符)与0101010对应关系。
a 01000001 ascii码中的字符:一个字符一个字节表示。
中 01001001 01000010 中文:一个字符两个字节表示。
Unicode:包含全世界所有的文字与二进制0101001的对应关系。
a 01000001 01000010 01000011 00000001
b 01000001 01000010 01100011 00000001
中 01001001 01000010 01100011 00000001
UTF-8:包含全世界所有的文字与二进制0101001的对应关系(最少用8位一个字节表示一个字符)。
a 01000001 ascii码中的字符:一个字符一个字节表示。
To 01000001 01000010 (欧洲文字:葡萄牙,西班牙等)一个字符两个字节表示。
中 01001001 01000010 01100011 亚洲文字;一个字符三个字节表示。
简单回顾完编码之后,再给大家普及一些知识点:
1. 在计算机内存中,统一使用Unicode编码,当需要将数据保存到硬盘或者需要网络传输的时候,就转换为非Unicode编码比如:UTF-8编码。
其实这个不用深入理解,他就是规定,举个例子:用文件编辑器(word,wps,等)编辑文件的时候,从文件将你的数据(此时你的数据是非Unicode(可能是UTF-8,也可能是gbk,这个编码取决于你的编辑器设置))字符被转换为Unicode字符读到内存里,进行相应的编辑,编辑完成后,保存的时候再把Unicode转换为非Unicode(UTF-8,GBK 等)保存
2. 不同编码之间,不能直接互相识别。
比如你的一个数据:‘老铁没毛病’是以utf-8的编码方式编码并发送给一个朋友,那么你发送的肯定是通过utf-8的编码转化成的二进制01010101,那么你的朋友接收到你发的这个数据,他如果想查看这个数据必须将01010101转化成汉字,才可以查看,那么此时那也必须通过utf-8编码反转回去,如果要是通过gbk编码反转,那么这个内容可能会出现乱码或者报错。
那么了解完这两点之后,咱们开始进入编码进阶的最重要的内容。
前提条件:python3x版本(python2x版本与这个不同)。
主要用途:数据的存储或者传输。
刚才咱们也说过了,在计算机内存中,统一使用Unicode编码,当需要将数据保存到硬盘或者需要网络传输的时候,就转换为非Unicode编码比如:UTF-8编码。
咱们就以网络传输为例:
好那么接下来咱们继续讨论,首先先声明一个知识点就是这里所说的'数据',这个数据,其实准确的说是以字符串(特殊的字符串)类型的数据。那么有同学就会问到,python中的数据类型很多,int bool list dict str等等,如果我想将一个列表数据通过网络传输给小明同学,不行么? 确切的说不行,你必须将这个列表转化成一个特殊的字符串类型,然后才可以传输出去,数据的存储也是如此。
那么你就清楚一些了,你想通过存储或者网络传输的数据是一个特殊的字符串类型,那么我就直接将这个字符串传出去不就行了么?比如我这有一个数据:'今晚10点吃鸡,大吉大利' 这不就是字符串类型么?我直接将这个数据通过网络发送给小明不就可以了么?不行。这里你还没有看清一个问题,就是特殊的字符串。为什么?

那么这个解决方式是什么呢?

那么这个bytes类型是个什么类型呢?其实他也是Python基础数据类型之一:bytes类型。
这个bytes类型与字符串类型,几乎一模一样,可以看看bytes类型的源码,bytes类型可以用的操作方法与str相差无几.
那么str与bytes类型到底有什么区别和联系呢,接下来咱们以表格的形式给你做对比。
| 类名 | str类型 | bytes类型 | 标注 |
| 名称 | str,字符串,文本文字 | bytes,字节文字 | 不同,可以通过文本文字或者字节文字加以区分 |
| 组成单位 | 字符 | 字节 | 不同 |
| 组成形式 | '' 或者 "" 或者 ''' ''' 或者 """ """ | b'' 或者 b"" 或者 b''' ''' 或者 b""" """ | 不同,bytes类型就是在引号前面+b(B)大小写都可以 |
| 表现形式 |
英文: 'alex' 中文: '中国' |
英文:b'alex' 中文:b'xe4xb8xadxe5x9bxbd' |
字节文字对于ascii中的元素是可以直接显示的, 但是非ascii码中的元素是以十六进制的形式表示的,不易看出。 |
| 编码方式 | Unicode | 可指定编码(除Unicode之外)比如UTF-8,GBK 等 | 不同 |
| 相应功能 | upper lower spllit 等等 | upper lower spllit 等等 | 几乎相同 |
| 转译 | 可在最前面加r进行转译 | 可在最前面加r进行转译 | 相同 |
| 重要用途 | python基础数据类型,用于存储少量的常用的数据 |
负责以二进制字节序列的形式记录所需记录的对象, 至于该对象到底表示什么(比如到底是什么字符) 则由相应的编码格式解码所决定。 Python3中,bytes通常用于网络数据传输、 二进制图片和文件的保存等等 |
bytes就是用于数据存储和网络传输数据 |
| 更多 | ...... | ...... |
那么上面写了这么多,咱们不用全部记住,对于某些知识点了解一下即可,但是对于有些知识点是需要大家理解的:
bytes类型也称作字节文本,他的主要用途就是网络的数据传输,与数据存储。那么有些同学肯定问,bytes类型既然与str差不多,而且操作方法也很相似,就是在字符串前面加个b不就行了,python为什么还要这两个数据类型呢?我只用bytes不行么?
如果你只用bytes开发,不方便。因为对于非ascii码里面的文字来说,bytes只是显示的是16进制。很不方便。
s1 = '中国' b1 = b'xe4xb8xadxe5x9bxbd' # utf-8 的编码
好,上面咱们对于bytes类型应该有了一个大致的了解,对str 与 bytes的对比也是有了对比的了解,那么咱们最终要解决的问题,现在可以解决了,那就是str与bytes类型的转换的问题。
如果你的str数据想要存储到文件或者传输出去,那么直接是不可以的,上面我们已经图示了,我们要将str数据转化成bytes数据就可以了。
str ----> bytes
# encode称作编码:将 str 转化成 bytes类型
s1 = '中国'
b1 = s1.encode('utf-8') # 转化成utf-8的bytes类型
print(s1) # 中国
print(b1) # b'xe4xb8xadxe5x9bxbd'
s1 = '中国'
b1 = s1.encode('gbk') # 转化成gbk的bytes类型
print(s1) # 中国
print(b1) # b'xd6xd0xb9xfa'
bytes ---> str
# decode称作解码, 将 bytes 转化成 str类型
b1 = b'xe4xb8xadxe5x9bxbd'
s1 = b1.decode('utf-8')
print(s1) # 中国
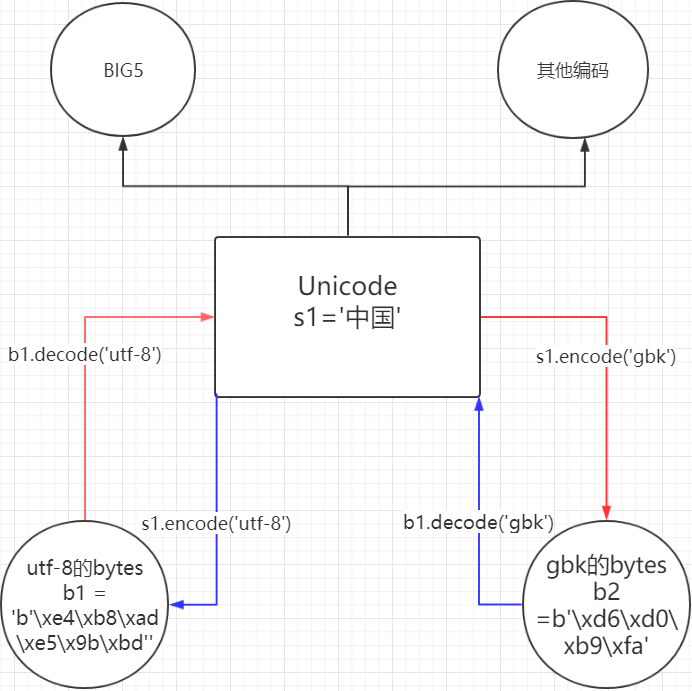
那么这里还有一个最重要的,也是你们以后工作中经常遇到的让人头疼的问题,就是gbk编码的数据,转化成utf-8编码的数据。有人说老师,我怎么有点蒙呢?这是什么? 来,捋一下,bytes类型他叫字节文本,他的编码方式是非Unicode的编码,非Unicode即可以是gbk,可以是UTF-8,可以是GB2312.....
b1 = b'xe4xb8xadxe5x9bxbd' # 这是utf-8编码bytes类型的中国 b2 = b'xd6xd0xb9xfa' # 这是gbk编码bytes类型的中国
那么gbk编码的bytes如何转化成utf-8编码的bytes呢?
不同编码之间,不能直接互相识别。
上面我说了,不同编码之间是不能直接互相是别的,这里说了不能直接,那就可以间接,如何间接呢? 现存世上的所有的编码都和谁有关系呢? 都和万国码Unicode有关系,所以需要借助Unicode进行转换。
看下面的图就行了!