
下一步进行osd磁盘更换,更换步骤:
1. 移除故障的osd
注:如果有多个osd故障,建议每次只踢一个osd,等待数据平衡完成再踢下一个,保证数据不丢失。依次将故障osd踢出ceph集群。
1.1 检查ceph集群状态及副本数,集群状态正常后再执行步骤1.2。
#ceph -s (集群状态为OK)
#ceph osd dump | grep "replicated size" (检查所有pool是否为3副本)
1.2 执行以下命令移除故障OSD,其中{$X}为osd id。(命令执行时确认成功后再执行下一条)
ceph osd out {$X}
systemctl stop ceph-osd@{$X} #把 OSD 踢出集群后,它可能仍在运行,就是说其状态为 up 且 out 。删除前要先停止 OSD 进程
ceph osd crush rm osd.{$X}
ceph auth del osd.{$X}
ceph osd rm {$X}
2.检查ceph集群状态
2.1 故障OSD移除后执行ceph -s检查集群状态是否ok;正常后再进行后续操作。
2.2 卸载原OSD挂载点信息。
#df -h #确认osd挂载点
#umount /var/lib/ceph/osd/ceph-{$X}
3.(可选:如果umount操作hang死,则需要重启服务器,一般不需要重启,根据实际情况判断)
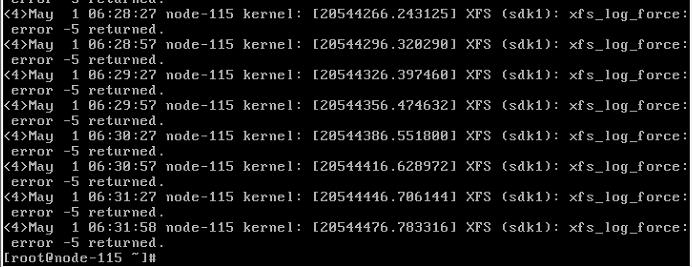
注:对于fault硬盘,执行umount后进程会hang死,需重启服务器解决。(可通过ps -aux |grep umount查询是否存在异常进程)
本次操作时就遇到了umount进程hang死的情况。
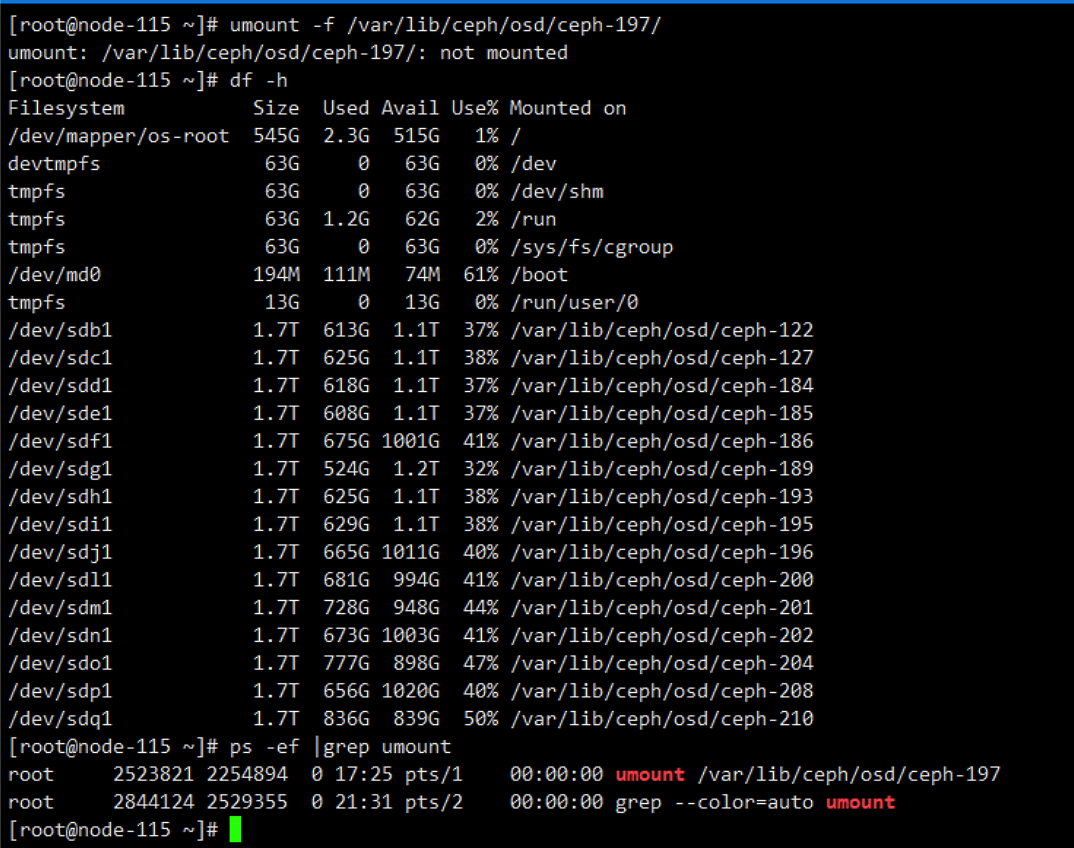
也无法kill掉这个进程,只能重启物理服务器了。
3.1 重启服务器
#注意,重启服务器前需要设置noout,否则重启会触发ceph集群数据均衡。
(1)检查ceph集群状态是否正常,同时不存在recovery/backfill的数据。
#ceph -s (集群状态为ok)
(2)全局设置noout
ceph osd dump |grep flags (查询集群当前标记)
ceph osd set noout
(3)登录需要重启的存储节点,执行如下命令停止节点中所有的OSD。
#systemctl stop ceph-osd.target
(4)通过ceph命令查询集群的状态,无recovery的数据后再进行重启操作。
#ceph -s
#ceph osd tree (查询osd的状态)
#ceph osd stat > /tmp/osdmap.log (查询当前集群中osdmap信息并记录)
#reboot #软重启
注意:本次在重启服务器,服务器在关机的时候hang住了,等了很久发现没起来,登录ipmi控制台查看,hang在关机步骤,决定在ipmi控制台进行硬重启下电操作。
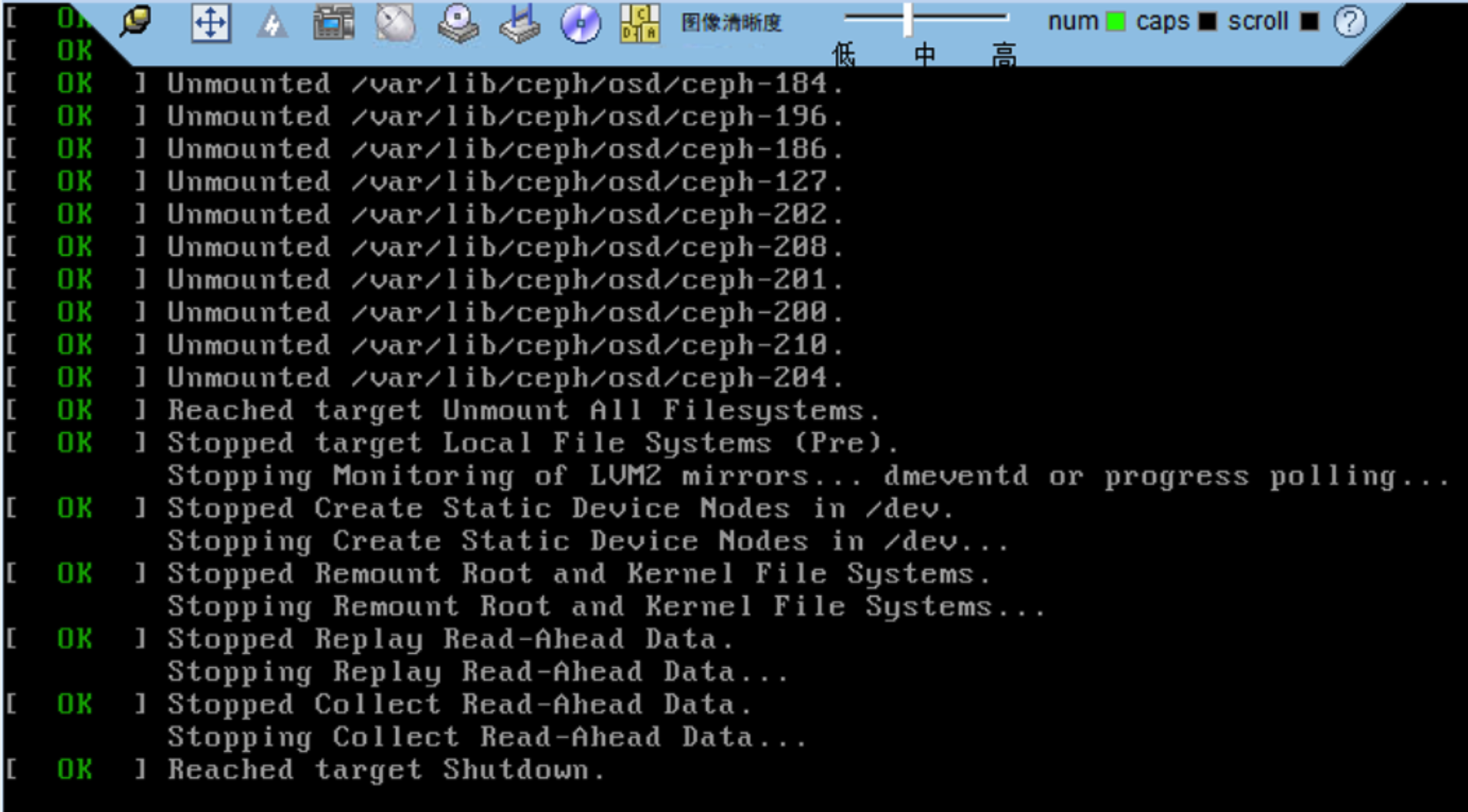
硬重启后,机器仍然无法进入系统,报错如下:
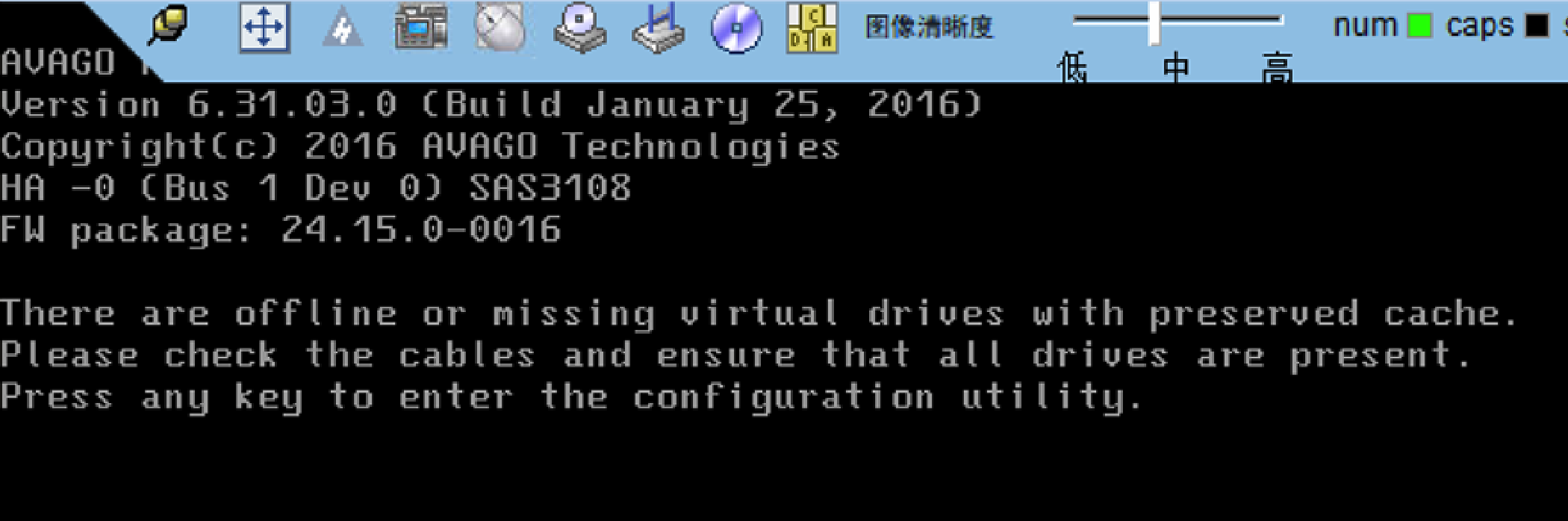
参考下面的博客解决掉了,虽然不是dell服务器,本环境是华为H2288V3服务器同样适用,因为故障盘是做的raid0,该故障盘的缓存还在,需要手动清理下故障盘的缓存。操作步骤参考下面链接。
服务器更换硬盘,启动系统报错:there are offline or missing virtual drivers with preserved cache
ok,服务器重启后,正常。进行下一步操作。
4. 更换故障硬盘
4.1 全局设置nodeep-scrub noout
#ceph osd set nodeep-scrub
#ceph osd set noout
#ceph health detail (查看存在noout、nodeep-scrub的flag)
4.2 对需要更换的硬盘进行拔除,并更换成新硬盘。联系机房同事,进行磁盘更换。
4.3 登录硬盘故障的存储节点,对更换的新硬盘进行重组RAID0操作;下图为RAID相关参数说明请参考。

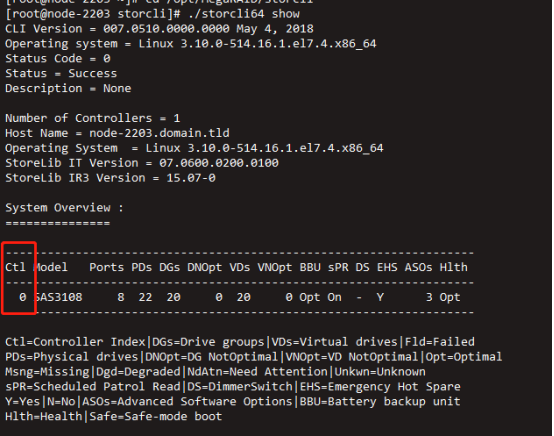
(1 )查询RAID卡的controller_id,例如以下查询到controller_id为0
/opt/MegaRAID/storcli/storcli64 show
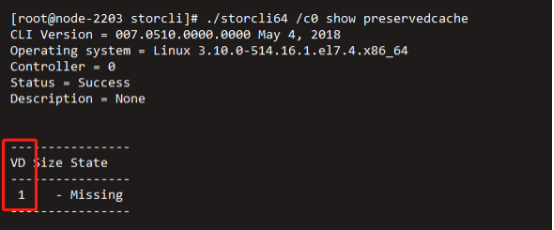
(2)查询RAID卡是否存在RAID信息保存的缓存数据,例如以下查询到的VD 1为残留信息。我们刚刚已经清理过了,所以本次查看是没有残留信息。
/opt/MegaRAID/storcli/storcli64 /c0 show preservedcache
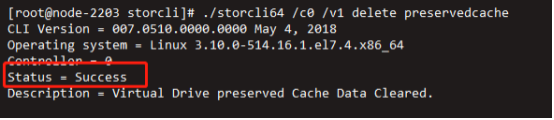
删除不使用的preservedcache信息。
/opt/MegaRAID/storcli/storcli64 /c0 /v1 delete preservedcache
(3)检查新更换硬盘的状态是否为UGOOD,DG的标识是否为-;(UGOOD意为未进行配置的好盘)
/opt/MegaRAID/storcli/storcli64 /c0 show all |more
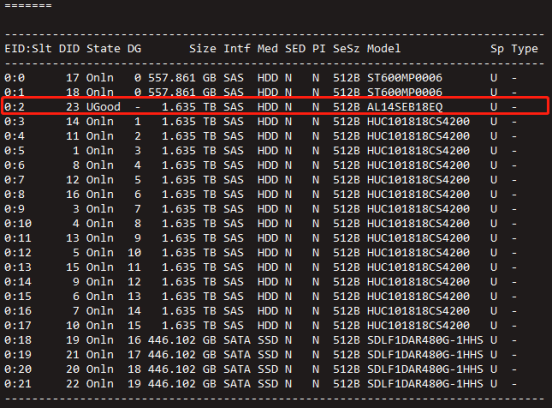
(4)(可选)如果检查新更换的硬盘状态不为UGOOD,状态为JBOD或则Ubad可通过以下命令进行硬盘状态的重置。
/opt/MegaRAID/storcli/storcli64 /ccontroller_id/eenclosure_id/sslot_id set good
(5)创建RAID0;
/opt/MegaRAID/storcli/storcli64 /ccontroller_id add vd r0 drives=enclosure_id:startid-endid wb
/opt/MegaRAID/storcli/storcli64 /c0 add vd r0 drives=0:11 wb
#本环境为了更好的利用到raid卡的cache,所以配置wb模式,经过测试,wb模式性能更高。但是配置wb模式前提是确定raid卡是有电池保护的。
Cache读写模式:
wt:当磁盘子系统接收到所有传输数据后,控制器将给主机返回数据传输完成信号。
wb:控制器Cache收到所有的传输数据后,将给主机返回数据传输完成信号。
awb:在RAID卡无电容或电容损坏的情况下,强制使用“wb”模式。
5. 添加新的OSD
注:每次只添加一个OSD,等待数据平衡完成后再添加下一个。
1. 检查待扩容OSD节点的网络是否正常。
#ip a |grep gl (获取br-storagepub、br-storage网络ip地址)
#ping {IP} (检查与其他存储节点br-storagepub、br-storage网络通信是否正常)
#telnet {IP} 6800 (检查与其他存储节点6800端口通信是否正常)
#ovs-appctl bond/show ovs-bond0 //检查Bond0的状态是否正常;
#ovs-appctl bond/show ovs-bond1 //检查Bond1的状态是否正常;
2. 检查ceph集群数据recovery和backfill的优先级是否修改过,默认1。
#cat /etc/ceph/ceph.conf |grep "osd_recovery_op_priority|osd_max_backfills"
3. 查询待扩容的OSD与日志盘对应关系可使用以下命令
#ceph-disk list
#ls -al /var/lib/ceph/osd/ceph-*/journal |awk '{print $11}' |xargs -n1 ls -al
确认本次添加的osd为node-115上的sdk,对应的journal盘是sdt1
4. 更换后的osd磁盘做分区。
ssh node-115
parted /dev/sdk mklabel gpt
parted /dev/sdk mkpart primary 2048s 100%
(1)对数据盘打标签(本次只更换数据盘,所以操作该步骤)
#sgdisk --typecode=1:4fbd7e29-9d25-41b8-afd0-062c0ceff05d /dev/sdk
(2)日志盘打标签(日志盘不更换的情况下无需操作)
sgdisk --typecode=1:45B0969E-9B03-4F30-B4C6-B4B80CEFF106 /dev/sdt
sgdisk --typecode=2:45B0969E-9B03-4F30-B4C6-B4B80CEFF106 /dev/sdt
sgdisk --typecode=3:45B0969E-9B03-4F30-B4C6-B4B80CEFF106 /dev/sdt
sgdisk --typecode=4:45B0969E-9B03-4F30-B4C6-B4B80CEFF106 /dev/sdt
5. ceph的mon节点添加OSD,即控制节点中添加。
#ceph-deploy --overwrite-conf osd prepare node-115:/dev/sdk1:/dev/sdt1
#ceph-deploy --overwrite-conf osd activate node-115:/dev/sdk1:/dev/sdt1
#watch ceph -s (数据平衡完毕后再扩容下一块osd)
待所有osd扩容后需取消全局设置的noin nodeep-scrub noout。
#ceph -s (无recovery、backfill数据)
#ceph osd unset nodeep-scrub
#ceph osd unset noout
#ceph -s (集群状态ok后扩容工作结束)