QString中文乱码

QString::QString ( const char * str )
QString QTextCodec::toUnicode ( const Char * a , int size, ConverterState * state = 0 ) const
Converts a from the encoding of this codec to Unicode, and returns the result in a QString.
把字符串a从codecForCStrings所表示的编码转换到Unicode编码.
前面写的 str("中文"); 出现的乱码, 很有可能是因为codecForCStrings所表示的编码不对.在QTextCodeC中有这样一个函数:
| void | setCodecForCStrings ( QTextCodec * codec ) |
这是一个静态函数看它的实现代码, 在文件qtextcodec.h中:
inline void QTextCodec::setCodecForCStrings(QTextCodec *c) { QString::codecForCStrings = c; }
只有一句话, 就是设置codecForCStrings的值, 这就是用于把 char * 转换成Unicode的对象.
我们来试试重新设置一下 codecForCStrings 对象,修改一下它所表示的编码, 下面是修改后的代码:
#include <QCoreApplication>
#include <QString>
#include <QDebug>
#include <QTextCodec>
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
QTextCodec::setCodecForCStrings(QTextCodec::codecForName("GBK")); // 关键是这句
QString str("乱码");
qDebug() << str;
return a.exec();
}
编译运行看结果:

正如期待的一样, 可以正确的显示中文.
那么为什么加上那句就可以正确显示中文了呢?
QTextCodec::setCodecForCStrings(QTextCodec::codecForName("GBK")); // 关键是这句
加这句是认为字符串 "乱码" 是GBK编码的.结果非常的 "巧合" 它正好是GBK编码的.所以结果就正确了.
为什么设为GBK编码就可以了呢??
因为我用的是 Visual Studio 2008 编译的, vs2008 编译器编译时会把 字符串 用locale字符编码字符串
我的系统编码是GBK, 所以就正确了.
至于其它的编译器, 请参考链接中的文章...大牛写的.
vs2008, vs2005.编译时不管源码是什么编码都会把源码中的字符串转换成 locale 编码(中文系统就是GBK),
有两种方法处理中文:
1. QTextCodec::setCodecForCStrings(QTextCodec::codecForName("GBK")); // 关键是这句
2.QString str = QString::fromLocal8bit("中文");
vs2003, 1. 如果源码是 ANSI(中文系统中的GBK编码) 编码的, 则在程序中可以这样处理中文:
QString str = QString::fromLocal8bit("中文");
2. 如果源码是 UTF-8 编码的则在程序中可以这样处理中文:
QString str = QString::fromUtf8("中文");
gcc 和 vs2003一样的处理, 不过gcc有编译选项可以设置, 请参数后面的链接.
http://blog.csdn.net/dbzhang800/article/details/7540905
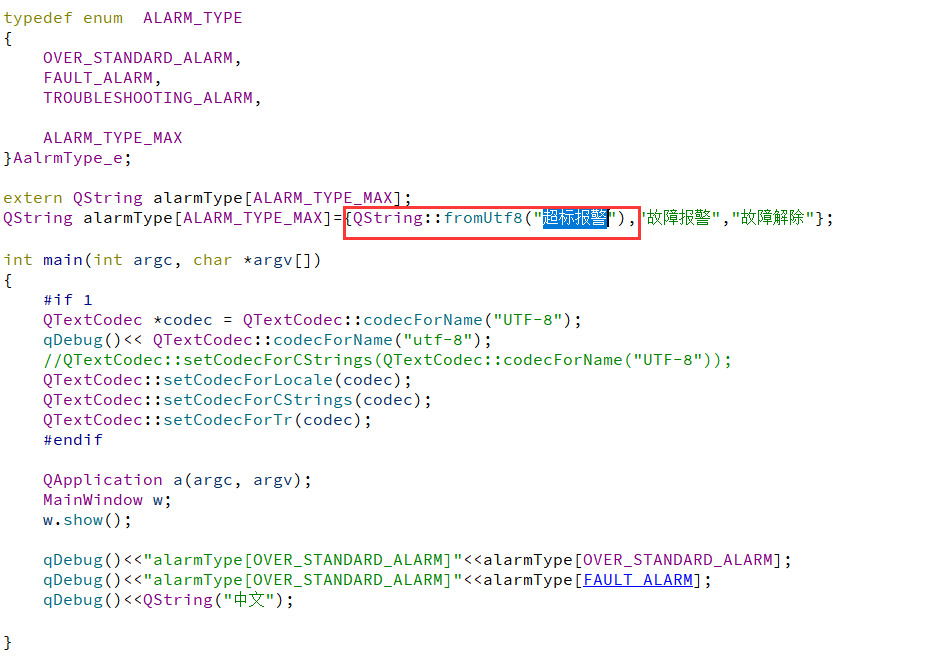
我发现在数组里必须要这样写:
FROM: http://tgstdj.blog.163.com/blog/static/748200402013213105251450/