论文地址:https://arxiv.org/abs/2004.13922
github地址:https://github.com/ymcui/MacBERT
1.该篇论文主要工作:
(1)大量的实证研究,以重新审视中文预训练模型在各种任务上的表现,并进行了细致的分析。
(2)提出了一个新的预训练模型MacBERT,通过用其相似的单词来掩盖单词,从而缩小训练前和微调阶段之间的差距。
(3)为了进一步加快对中文NLP的研究,创建了中文预训练模型系列并发布到社区。
2.预训练模型对比
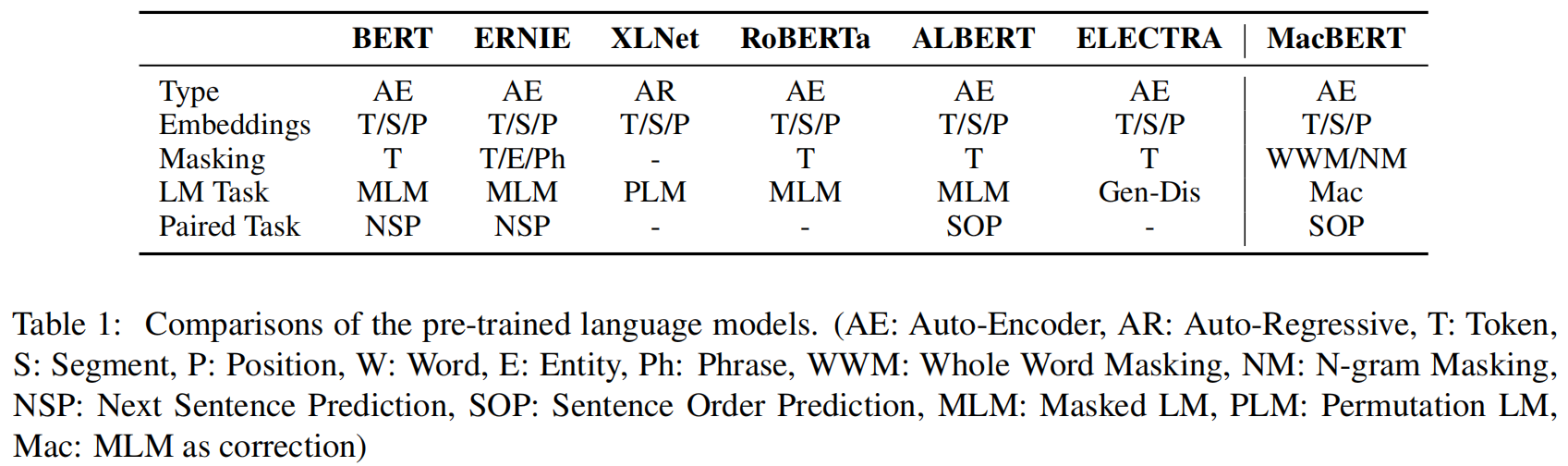
2.1 BERT
Bidirectional Encoder Representations from Transformers (Devlin et al.,2019) (根据Transformer的双向编码器表示),旨在通过在所有Transformer层中联合调节左右上下文,预训练深度双向表示。
BERT consists of two pre-training tasks: Masked Language Model (MLM) and Next Sentence Prediction (NSP).(bert包含两种任务:MLM 和 NSP)
MLM: Randomly masks some of the tokens from the input, and the objective is to predict the original word based only on its context.(随机mask一些输入的token,目标是:通过的mask上下文的token预测mask的单词。)
NSP: To predict whether sentence B is the next sentence of A.(预测B是否是A的下一个语句。)
Later, they further proposed a technique called Whole Word Masking (WWM) for optimizing the original masking in the MLM task.(进一步的通过全词mask的方式优化MLM任务中的mask方式。)In this setting,instead of randomly selecting WordPiece tokens to mask, we always mask all of the tokens corresponding to a whole word at once.(在这种策略下,代替随机mask WordPoece token,mask整个词相关的WordPoece token。)
2.2 ERNIE
Enhanced Representation through kNowledge IntEgration (ERNIE) is designed to optimize the masking process of BERT, which includes entity-level masking and phrase-level masking. (ERNIE设计优化bert的mask策略,包含实体水平的mask和短语水平的mask。)Different from selecting random words in the input, entity-level masking will mask the named entities, which are often formed by several words. (与输入随机选择词不同,实体水平的mask将mask命名实体的词,有可能是几个词。)Phrase-level masking is to mask consecutive words, which is similar to the N-gram masking strategy.(短语水平的mask是mask连续的几个词,与ngram mask策略相似的。)
2.3 XLNET
Yang et al. (2019) 认为,现有的基于自动编码的预训练语言模型,如BERT,存在预训练和微调阶段的差异,因为掩码符号[MASK]在微调阶段不会出现。为了缓解这个问题,提出了基于Transformer-XL (Dai et al., 2019)的XLNet。
To alleviate this problem, they proposed XLNet, which was based onTransformer-XL.(为了缓解bert预训练和微调阶段的误差,提出了XLNET,它是基于Transformer-XL。)XLNet mainly modifies in two ways. The first is to maximize the expected likelihood over all permutations of the factorization order of the input, where they called the Permutation Language Model (PLM). Another is to change the autoencoding language model into an autoregressive one, which is similar to the traditional statistical language models.(XLNET主要做了两方面的改变。首先,最大化所有输入排列的对数似然,它成为重排列语言建模PLM。其次,XLNET改变自编码语言模型为自回归语言模型,它是与传统的统计语言模型相似的。)
2.4 RoBERTa
Robustly Optimized BERT Pretraining Approach (Liu et al., 2019) (健壮优化bert预训练方法)
aims to adopt original BERT architecture but make much more precise modifications to show the powerfulness of BERT,which was underestimated. They carried out careful comparisons of various components in BERT,including the masking strategies, training steps, etc.
(采用BERT原始架构,但做了更加精确的修改。对BERT中的各种成分进行了仔细比较,包括掩码策略、训练步骤等。)
After thorough evaluations, they came up with several useful conclusions to make BERT more powerful, mainly including 1) training longer with bigger batches and longer sequences over more data; 2)removing the next sentence prediction and using dynamic masking(在深入评估后,得出结论:1.在更多数据上,用更大的batch和更长的序列训练更长时间。2,移除NSP任务,使用动态掩码。)
2.5 ALBERT
(A Lite BERT 简化BERT) (Lan et al., 2019) primarily tackles the problems of higher memory assumption and slow training speed of BERT(主要解决了BERT需要更高内存假设和训练速度慢的问题).
ALBERT introduces two parameter reduction techniques(介绍了两种参数缩减技术). The first one is the factorized embedding parameterization that decomposes the embedding matrix into two small matrices(1.分解嵌入参数:将嵌入矩阵分解为两个小矩阵). The second one is the cross-layer parameter sharing that the Transformer weights are shared across each layer of ALBERT, which will significantly reduce the parameters(跨层数据共享:在ALBERT每一层间共享Transformer的权值,极大减少参数). Besides, they also proposed the sentence-order prediction (SOP) task to replace the traditional NSP pre-training task(此外,提出sentence-order prediction(SOP) 句子顺序预测任务,替代之前的NSP任务).
2.6 ELECTRA
Efficiently Learning an Encoder that Classifiers Token Replacements Accurately (Clark et al., 2020) (有效学习可精确替换分类器Token的编码器).employs a new generator-discriminator framework that is similar to GAN(采用了一种新的生成器-鉴别器(generator-discriminator)框架,类似于GAN (Goodfellow et al., 2014)).The generator is typically a small MLM that learns to predict the original words of the masked tokens(生成器通常是一个小的MLM,学习去预测被mask token的原始词). The discriminator is trained to discriminate whether the input token is replaced by the generator(鉴别器经过训练,鉴别输入token是否被替换).Note that, to achieve efficient training, the discriminator is only required to predict a binary label to indicate “replacement”, unlike the way of MLM that should predict the exact masked word(为了实现有效训练,鉴别器只需要预测一个二进制标签表示“替换”,不像MLM的方式,去预测确切的被掩码的词汇). In the fine-tuning stage, only the discriminator is used(微调阶段,只使用鉴别器).
3.MacBERT的结构
3.1 BERT-wwm & RoBERTa-wwm
In the original BERT, a WordPiece tokenizer (Wu et al., 2016) was used to split the text into WordPiece tokens, where some words will be split into several small fragments(原始BERT中,WordPiece tokenizer (Wu et al., 2016)将文本且分为多个小的片段). The whole word masking (wwm) mitigate the drawback of masking only a part of the whole word, which is easier for the model to predict(whole word masking(wwm)减轻了只mask某词一部分(word piece)的缺点,让模型更加易于预测). In Chinese condition, WordPiece tokenizer no longer split the word into small fragments, as Chinese characters are not formed by alphabet-like symbols(在中文条件下,由于汉字不是由类似字母的符号构成的,所以分词工具不能再将单词分割成更小块). We use the traditional Chinese Word Segmentation (CWS) tool to split the text into several words(使用传统中文词汇分割(CWS)工具将文本分割为多个词). In this way, we could adopt whole word masking in Chinese to mask the word instead of individual Chinese characters(然后采用全词掩码而非单字掩码). For implementation, we strictly followed the original whole word masking codes and did not change other components, such as the percentage of word masking,etc(实现过程中严格遵循全词掩码,且并没有改变其它组件,如掩码比率等). We use LTP (Che et al., 2010) for Chinese
word segmentation to identify the word boundaries(使用LTP (Che et al., 2010)进行中文分词,以识别词的边界)。
Note that the whole word masking only affects the selection of the masking tokens in the pre-training stage(wwm只会影响预训练阶段,掩码token的选择). The input of BERT still uses WordPiece tokenizer to split the text, which is identical to the original BERT(BERT输入仍然使用 WordPiece tokenizer来分割文本,等同于原始bert).
Similarly, whole word masking could also be applied on RoBERTa, where the NSP task is not adopted(类似地,wwm也能应用于RoBERTa,其中,不适用于NSP任务).
3.2 MacBERT
For the MLM task, we perform the following modifications .(对于MLM任务,仅做以下修改。)
1. We use whole word masking as well as Ngram masking strategies for selecting candidate tokens for masking, with a percentage of 40%, 30%, 20%, 10% for unigram to 4-gram.(我们使用全词mask和ngram mask的策略选择mask的token,对于ngram mask 策略,从unigram到4-gram的比例分别为40%, 30%, 20%, 10% 。)
2. Instead of masking with [MASK] token, which never appears in the fine-tuning stage, we propose to use similar words for the masking purpose. (在微调阶段没使用mask策略,为了替换mask token,我们采用mask token相似的词。)A similar word is obtained by using Synonyms toolkit , which is based on word2vec similarity calculations.(相似的词使用Synonyms工具计算得到,它是基于Wordvector相似度计算。) If an N-gram is selected to mask, we will find similar words individually.(如果使用N-grammask策略,我们将分别找到相似的词。) In rare cases, when there is no similar word, we will degrade to use random word replacement.(在少数情况下,如果没找相似的词,我们将使用随机的词替换。)
3. We use a percentage of 15% input words for masking, where 80% will replace with similar words, 10% replace with a random word, and keep with original words for the rest of 10%.(我们采用15%的输入的word进行mask,其中80%的词替换为相似的词,10%的词随机替换,10%的词保持不变。)
For the NSP task, we perform sentence-order prediction (SOP) task as introduced by ALBERT, where the negative samples are created by switching the original order of two consecutive sentences.(对于NSP任务,我们采用albert的SOP任务,SOP中的负样本是交换两个句子的顺序。)
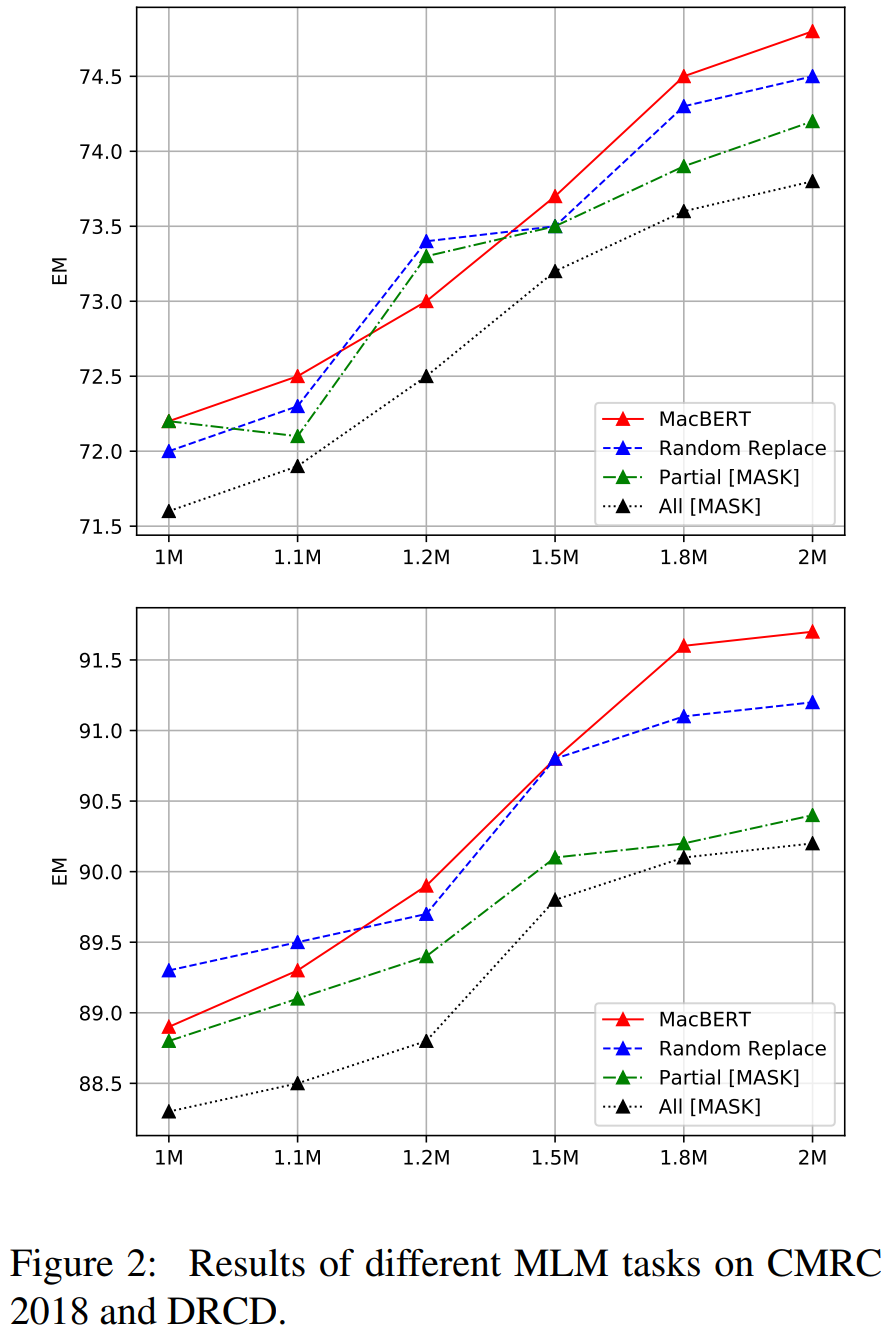
4.消融实验
消融实验是很重要的部分,因为它能再次显示出作者提出方法的动机。
这里w/o Mac表示去掉同义词替换,w/o NM表示去掉N-gram masking,实验表示,去掉它们都会损害性能。除此之外,实验还表明NSP-like任务相对MLM任务来说,对模型没那么重要(这也提醒我们应该花更多时间研究改进MLM任务上),SOP任务要比NSP任务要好。
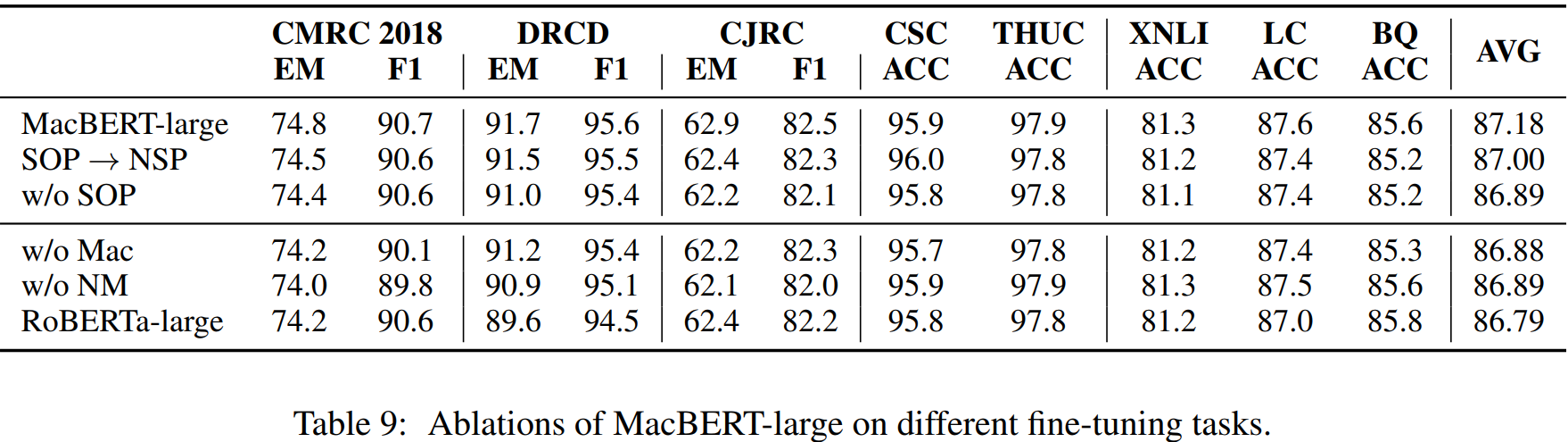
为了讨论改进MLM任务的影响,采用了下面四种对比,首先我们沿用前面的对15%的words进行【MASK】,其中的10%用原来的token代替
-
MacBERT:80%用同义词代替,10%用随机词;
-
Random Replace:90%用随机词代替;
-
Partial Mask:同原生的BERT一样,80%用【MASK】代替,10%用随机词;
-
ALL Mask:90%用【MASK】代替。
实验结果自然是MacBERT表现最好,除此之外,预训练时,保留【MASK】作为输入会极大地影响下游任务的性能。甚至把【MASK】用随机的token代替(即Random Replave),都会比原生BERT(即Partial Mask)要好。
5.总结
MacBERT 在bert的各个改进版本之上的,持续优化训练的策略:(1)对于MLM任务,使用全词mask和ngram mask策略,mask的词使用相似词替换,减少训练和微调之间的误差:(2)使用albert的SOP任务;在下游的任务中,比之前的bert版本效果均要好。
参考:
https://arxiv.org/abs/2004.13922
https://blog.csdn.net/weixin_40122615/article/details/109317504
https://blog.csdn.net/weixin_42546799/article/details/119612565