ORM
ORM即Object Relational Mapping(对象关系映射)
对象关系映射(英语:(Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换 。从效果上说,它其实是创建了一个可在编程语言里使用的—“虚拟对象数据库”。
在Django中具体的对应方式为:
- 类名对应数据库中的表名
- 类名对应数据库中的表名
- 类属性对应数据库里的字段
- 类实例对应数据库表里的一行数据
- 类实例对象的属性对应这行中的字段的值
一.数据库的连接
Django默认使用的是sqlite,如果想使用mysql来存储数据,需要改变成相应的数据库引擎,具体如下:
1.修改setting文件
将
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
}
改成
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME':'mysite',
'USER': 'root',
'PASSWORD': '000000',
'HOST': '127.0.0.1',
'PORT': '3306',
}
}
2.引入pymysql驱动
在init.py文件中加上
import pymysql pymysql.install_as_MySQLdb()
二.表的创建
1.一个简单的创建
数据库表的创建在ORM中就是类的创建。
class student(models.Model):
name=models.CharField(max_length=20)
num=models.IntegerField()
school=models.ForeignKey(school,on_delete=models.CASCADE)
teacher=models.ManyToManyField(teacher)
def __str__(self):
return self.name
class school(models.Model):
name = models.CharField(max_length=20)
def __str__(self):
return self.name
class teacher(models.Model):
name = models.CharField(max_length=20)
def __str__(self):
return self.name
首先在models.py中简单的创建了三个表,然后需要在当前项目有manage.py文件目录下的cmd或者pycharm中的terminal下执行如下命令来同步数据库:
python manage.py makemigrations #为模型改变生成迁移文件
python manage.py migrate #应用数据库迁移
这时在数据库中就会显示有这3张表了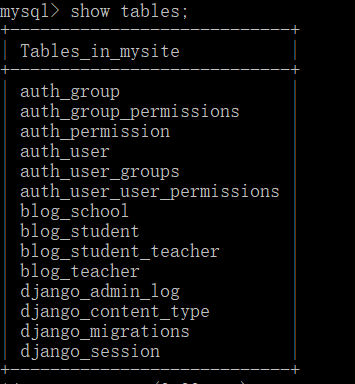
2.字段的类型与参数
几个常用的类型:
- CharField
- IntegerField
- TextField
- 等等
几个常用的参数:
- null
- default
- primary_key
- unique
- 等等
具体参考Django官方文档https://docs.djangoproject.com/en/2.1/ref/models/fields/
3.表与表之间的关联
1.外键
即一对多的关系
school=models.ForeignKey(school,on_delete=models.CASCADE)
在建表时为school添加外键约束,在数据库中的显示为
这里的id是自动创建的,school_id是school添加外键产生的
如果想要与另一张表的其他字段添加外键,需要在加上参数to_filed=’字段名’,同时这个字段必须是unique=True
2.一对一
一对一的创建即在外键创建好后给school_id添加UNIQUE=True的属性
3.多对多
teacher=models.ManyToManyField(teacher)
这样Django会默认添加一张表为
表示多对多的关系。
除了这种方式也可以手动创建一个表,手动添加两个外键来实现多对多。
三.增删改查
增删改查的操作会在视图函数中进行,所以要先引入到views.py中
from blog.models import *
1.增加
1.普通字段
create方式
student.objects.create(name="student1",num=1,school=school_obj)
或者
student.objects.create(**{"name":"student1","num"="1","school"=obj"})
save方式
student_obj=student(
name="student1",num=1,school=school_obj
)
student_obk.save()
或者
student_obj=student()
student_obj.name="student1"
student_obj.num=1
student_obj.school=school_obj
2.一对多关系的字段
直接设置外键的id
在student.objects.create中加
school_id=1
通过获取外键对象设置
obj = school.objects.get(name="school1")
student.objects.create(**{"name":"student2","num":2,"school":obj})
3.多对多关系的字段
teacher1=teacher.objects.get(id=1)
teacher2=teacher.objects.get(id=2)
student1=student.objects.get(id=1)
student1.teacher.add(teacher1,teacher2)
或
teacher1=teacher.objects.filter(id__gt=1,id__lt=10)
student1=student.objects.get(id=1)
student1.teacher.add(*teacher1)
或
teacher1=teacher.objects.filter(id=1)[0]
student1=student.objects.filter(id__gt=1)
teacher1.student_set.add(*student1)
或
student1=student.objects.filter(id=1)[0]
student1.teacher.add(2)
如果多对多关系的表是自己手动创建的,那么还可以直接添加该表的字段,利用两个外键的方式添加。
2.删除
1.删除普通表信息
先找到,再删除
student1=student.objects.filter(id=1)[0].delete()
由于django的级联删除,其他表中如student_teacher表中有student1的信息的数据也会删除
2.删除多对多表的信息
student1=student.objects.filter(id=1)[0]
student1.teacher.clear()#删除多对多表中student_id为student1的id的数据
student1.teacher.remove(2)#删除多对多表中teacher_id为2的数据
student1.teacher.remove(*list)#这里也可以为一个列表
反向即使用student_set,其他和正向同样道理
3.修改
1.普通字段的修改
student1=student.objects.get(id=2)
student1.name="sfencs"
student1.save()
``
或者
```python
student1=student.objects.filter(id=2).update(name="sfencs")
update是queryset的方法,可以更新多行数据。
save方法是将一行的所有字段都重新存储一遍,update方法只将要改变的字段存储,效率更高。
2.多对多表的字段的修改
student_obj.teacher.set([1,2,3])# set里是一个列表
先删除,再添加
4.查询
1.查询的有关函数
- filter(**kwargs)筛选
- all()所有结果
- get(**kwargs)得到一个结果,如果结果多于一个或没有都会报错
如果查询结果是一个结果集,即QuerySet对象,那么它还有以下方法
- values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列
- exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
- order_by(*field): 对查询结果排序
- reverse(): 对查询结果反向排序
- distinct(): 从返回结果中剔除重复纪录
- values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
- count(): 返回数据库中匹配查询(QuerySet)的对象数量。
- first(): 返回第一条记录
- last(): 返回最后一条记录
- exists(): 如果QuerySet包含数据,就返回True,否则返回False。
2.QuerySet对象
- 查询的结果集就是一个QuerySet对象
- QuerySet对象就像是一个列表,列表存储着查询出的结果,可以迭代,可以切片
- Django中QuerySet对象是惰性的,即你得到这个对象的时候并没有真正的在数据库中执行SQL语句,只有用到了QuerySet对象中的数据才会执行SQL语句
- 想判断QuerySet对象中是否有数据,若写成
if obj:
仍然会执行SQL语句,若使用
if obj.exists():
就可以避免这种问题。
- QuerySet对象的使用是有cache缓存的,即遍历第二次QuerySet对象的时候数据是从缓存中拿的,不会执行SQL语句
- 如果QuerySet对象数据量特别大,遍历时为了避免占用大量cache空间,可以将QuerySet对象转换成一个迭代器
3.基础查找
得到对象后,查找字段
student1=student.objects.filter(school_id=1)[0]
print(student1.num)
拿时外键对象的字段
student1 = student.objects.filter(id=2)[0]
print(student1.school.name)
拿多对多关系的字段
因为是多对多关系,得到的会是一个QuerySet对象
student1=student.objects.filter(id=2)[0]
print(student1.teacher.values('name'))
4.使用’__’进行的查找
一对多
school_name为外键对象的字段
school为student表中设置的外键字段
student1=student.objects.filter(id=2).values('school__name')
print(student1)
多对多
和一对多的查询方式一样
teacher为student表中设置的外键字段
student1=student.objects.filter(id=2).values('teacher__name')
print(student1)
反向一对多
student__name中的student为表名
result=school.objects.filter(student__name='student1').values('name')
print(result)
反向多对多
也和反向多对多一样
result=teacher.objects.filter(student__id=2).values('name')
print(result)
其他查询条件
- id__lt=3 表示id小于3
- id__gt=1 表示id大于1
- id__in=[1, 2, 3] 表示id在列表中
- name__contains=”fenc” 表示name中包含fenc
- name__icontains=”ven” 表示不区分大小写的包含
- id__range=[1,3] 表示id在1到3之间,包括1,3
- name__startswith=’cs’ 表示以cs开头的
- name__endswith=’cs’ 表示以cs结尾的
- name__istartswith 不区分大小写
- name__iendswith 不区分大小写
- 等等
5.聚合查询aggregate
聚合查询是对QuerySet对象进行计算得到一个结果值作为字典中的值放到一个字典中
这里先引入一些聚合方法
from django.db.models import Avg,Min,Sum,Max
举例:
result=student.objects.all().aggregate(Max('num'))
print(result)
得到的是一个字典:{‘num__max’: 3}
若你想给这个字典的key换一个名字,可以使用:
result=student.objects.all().aggregate(new_name=Max('num'))
输出:{‘new_name’: 3}
也可以同时进行多个聚合查询
result=student.objects.all().aggregate(Avg('num'),Min('num'),new_name=Max('num'))
6.分组查询annotate
分组查询就像是SQL语句中的group by
可以如下使用,即以school_id分组,计算每组的max(num)
result=student.objects.values('school_id').annotate(Max('num'))
也可以对QuerySet对象使用
在查询得出的结果集中进行分组
result=student.objects.filter(school_id__lt=2).values('school_id').annotate(Max('num'))
7.F查询
执行F查询前还得先引入
from django.db.models import F
F查询可以将对象中的值作为变量使用,例如:
result=student.objects.filter(id__gt=F('school_id'))
或者
result=student.objects.update(num=F('school_id')+1)
8.Q查询
惯例先引入
from django.db.models import Q
Q查询是应用在查询条件上的。
在普通的查询当中,且可以用逗号‘,’表示,可是如果我们想使用或的关系怎么办,使用Q来完成它
student1=student.objects.filter(Q(num=1) | Q(school_id=1))
相当于用Q将条件封装,在Q对象之间使用&或者|或者~
如果想将普通发关键字参数查询与Q查询一起使用,必须将关键字参数查询放到Q的后边
9.扩展查询extra
Django 的查询语法难以简练地表达复杂的 WHERE 子句,于是使用扩展查询extra,其原理相当于给SQL语句中添加子语句
extra(select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
这些参数都是可写可不写的
简单举例:
直接暴力上中文了
student1=student.objects.extra(select={'是否大于2':'num>2'})
print(student1.values('是否大于2')[0]['是否大于2'])
SQL语句其实执行的是SELECT (num>2) AS 是否大于2 FROM `blog_student
可以为select传递参数
student1=student.objects.extra(select=({'是否大于2':'num>%s'}),select_params = ('2',))
可以排序
加‘-’为从大到小,不加为从小到大
student1=student.objects.extra(select=({'是否大于2':'num>%s'}),select_params = ('2',))
student1=student1.extra(order_by=['-是否大于2'])
语句中会添加SELECT (num>’2’) AS 是否大于2 FROM blog_student ORDER BY 是否大于2 DESC
也可以设置where条件,并且给where设置参数
student1=student.objects.extra(select=({'是否大于2':'num>%s'}),select_params = ('2',),where=['id<%s'],params=['4'])
SQL语句为SELECT (num>’2’) AS 是否大于2 FROM blog_student WHERE (id<’4’) ORDER BY 是否大于2 DESC
10.日志查看对应执行的SQL语句
在setting.py中加上下边的代码
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
LOGGING