Trident中有对状态数据进行读取和写入操作的一流抽象工具。状态既可以保存在拓扑内部,比如保存在内容中并由HDFS存储,也可以通过外部存储(比如Memcached或Cassandra)存储在数据库中。而对于Trident的API而言,这两种机制没有任何区别。
Trident以容错的方式来管理状态,当遇到重试或则错误时状态的更新是幂等的,在数据统计分析中,幂等性是一个很重要的指标,因为它可以保证即使数据被处理了多次,但是站在结果的角度看和处理一次完全一样。
我们来看一个例子,假定你正在对一个流做计数处理,并把计算结果写入到数据库。如果在数据库中使用一个值来表示这个计数,然后每处理一个tuple,就将这个计数值加1.当错误发生时,tuple会被重新处理。这就引发了一个问题,当进行状态更新时,你完全不知道事前是否已经处理成功这个tuple。这样就可能导致,原来处理过的tuple在这里对应的存储计数值任然加了1。
当然,若数据库中值存一个计数的话,是区分不出来这个tuple之前是否被正确处理的,这就需要更多的信息来支持。Trident提供了下面几个原语来实现只处理一次的语义。
1.tuples是被分成一组组小的集合来处理的。
2.每一个batch会给分配一个唯一的id(事物id,txid),当batch被重新处理时,txid是不变的
3.batch之间的状态更新是严格有序的,就是说batch2没有处理万的情况下batch3绝对不会被处理
有了这些原语就,在处理状态更新的时候就能知道这个batch之前有没有被处理过。然后采取合适的操作即可。下面我们看看每一种Spout类型都支持什么样的容错级别。
事务性Spout
Trident是以batch的方式来处理tuple的,同时每个batch会分配一个唯一的transaction id,Spout的特性根据他们所提供容错性保证机制来决定的,而且这种机制也会对每个批次发生作用。事务型Spout有如下特性:
1.一个batch无论被重发多少次,只有一个唯一且相同的事物id,同事所包含的tuple都是完全一致的
2.每个tuple必须且至多属于一个batch
事务性Spout很容易理解,但是在极端的情况下也会有一些问题。假设一批消息在被Bolt消费的过程中失败了,需要Spout重发,这时,如果刚好消息发送的中间件故障,Spout为了保证重发的时候每个batch包含的tuple一致,就智能等待消息中间件恢复了,整个处理就这样阻塞了。
来看一个例子
设计一个计算WordCount的Topology,将单词的出现的次数以KV的形式存储到数据库中。Key就是单词,V 对应单词出现的次数。可以将Value和事物ID一起存储到数据库中。每次更新Value前,先将当前的事物ID和数据库中存储的事物ID进行比较。如果一样就忽略,否则执行存储操作。例如下面的一个batch
batch(事物ID为3) 1.["man"] 2.["man"] 3.["dog"]
数据库中保存的信息如下:
1.man => [count=2,txid=1] 2.dog => [count=4,txid=3] 3.apple => [count=10,txid=2]
单词"man"对应的txid为3,而当前的txid为1,可以确定没有为这个batch中的tuple更新过这个单词的数量,所以直接更新txid为3,而dog对应的txid和当前的txid相同忽略更新,单词apple保持不变,更新后的数据如下:
1.man => [count=4,txid=3] 2.dog => [count=4,txid=3] 3.apple => [count=10,txid=2]
不透明事务性Spout
不透明事务型Spout不能保证相同txid对应的批次中的元组数据完全一致,有一下特性
tuple只在一个batch中被成功处理,如果tuple在一个batch中被处理失败,有可能会在另一个batch中被成功处理。也就是说一个tuple第一次在txid为2的batch中出现,以后有可能在txid为4的batch中再次出现。
不透明事务性Spout有很好的容错性,但是需要额外的存储空间。出了Value和txid,你还需要在数据库中存储之前的数据,我们还以数据库中存储计数为例。假设当前数据库中存储的信息如下:
{ value=4, preValue=1, txid=2 }
下一次batch的txid为3,计数值为2,和数据库中的txid不同这种情况下将value中的值放入到preValue中,新增的值加到Value上去,更新后的数据库信息如下:
{ value=6, preValue=4, txid=3 }
如果当前batch的txid任然为2,与数据库中存储的相同,怎么操作呢?我们知道,数据库中的value值是通过与这次的txid相同的上个batch更新而来的,但是batch可能已经变化了所以我们要忽略它,这种情况下需要做的就是更新value的值为prevalue加上本次的batch值,结果应该是这样的
{ value=3, preValue=1, txid=2 }
此方式的正确定是基于Trident保证了batch的强顺序性。Trident处理一个batch时,一定不会重复或则回溯到之前的batch。每个tuple只会在一个batch中被成功处理,所以更新是原子的。
非事物型Spout
非事务型Spout不能为批次提供任何保证。所以可能出现”至多一次”的处理,即在某个批次处理过程中失败了,但是不会在重新处理;也可能提供“至少一次”的处理,即可能会有多个批次分别处理某个元组。也就是没有办法实现“恰好一次”的语义。
Spout和State类型小结
下面是不同的spout/状态组合是否支持“恰好一次”处理语义:
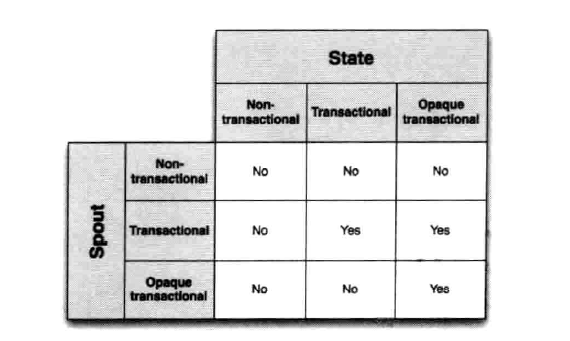
不透明事务状态有最强的容错性,但是因为存储txid和两个结果带来更大的开销。事务型状态只需要存储一个状态结果,但是只对事务型Spout有效。非事务型状态要求存储的数据更少,但是不能实现“恰好一次”的处理语义。所以在选择容错与存储空间中,需要根据具体的需要选择合适的组合。