Hadoop中的NameNode好比是人的心脏,非常重要,绝对不可以停止工作。在hadoop1时代,只有一个NameNode。如果该NameNode数据丢失或者不能工作,那么整个集群就不能恢复了。这是hadoop1中的单点问题,也是hadoop1不可靠的表现。hadoop2就解决了这个问题。
hadoop2.2.0中HDFS的高可靠指的是可以同时启动2个NameNode。其中一个处于工作状态,另一个处于随时待命状态。这样,当一个NameNode所在的服务器宕机时,可以在数据不丢失的情况下,手工或者自动切换到另一个NameNode提供服务。这些NameNode之间通过共享数据,保证数据的状态一致。多个NameNode之间共享数据,可以通过Nnetwork File System或者Quorum Journal Node。前者是通过linux共享的文件系统,属于操作系统的配置;后者是hadoop自身的东西,属于软件的配置。我们这里讲述使用Quorum Journal Node的配置方式,方式是手工切换。
集群启动时,可以同时启动2个NameNode。这些NameNode只有一个是active的,另一个属于standby状态。active状态意味着提供服务,standby状态意味着处于休眠状态,只进行数据同步,时刻准备着提供服务
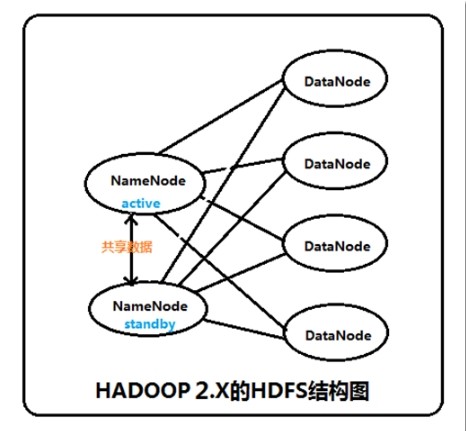
架构
在一个典型的HA集群中,每个NameNode是一台独立的服务器。在任一时刻,只有一个NameNode处于active状态,另一个处于standby状态。其中,active状态的NameNode负责所有的客户端操作,standby状态的NameNode处于从属地位,维护着数据状态,随时准备切换。
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了
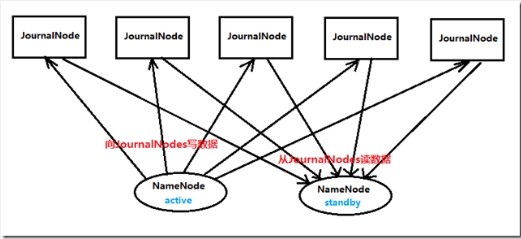
为了确保快速切换,standby状态的NameNode有必要知道集群中所有数据块的位置。为了做到这点,所有的datanodes必须配置两个NameNode的地址,发送数据块位置信息和心跳给他们两个。
对于HA集群而言,确保同一时刻只有一个NameNode处于active状态是至关重要的。否则,两个NameNode的数据状态就会产生分歧,可能丢失数据,或者产生错误的结果。为了保证这点,JNs必须确保同一时刻只有一个NameNode可以向自己写数据。
下面主要给大家说下搭建Hadoop 2.2.0版本HDFS的HA配置
安装配置jdk,SSH
一.首先,先搭建五台小集群,虚拟机的话,创建五个
下面为这五台机器分别分配IP地址及相应的角色:集群有个特点,三五机子用户名最好一致,要不你就创建一个组,把这些用户放到组里面去,我这五台的用户名都是hadoop,主机名随意起
192.168.0.25-----namenode1(主机),主机namenode,zookeeper,journalnode,zkfc----namenode1(主机名)
192.168.0.26-----namenode2(从机),备机namenode,zookeeper,journalnode,zkfc-----namenode2(主机名)
192.168.0.27-----datanode(从机),datanode,zookeeper,journalnode-----datanode(主机名)
192.168.0.28-----datanode2(从机),datanode,zookeeper,journalnode-----datanode2(主机名)
192.168.0.29-----datanode3(从机),datanode,zookeeper,journalnode-----datanode3(主机名)
如果用户名不一致,你就要创建一个用户组,把用户放到用户组下面:
sudo addgroup hadoop 创建hadoop用户组
sudo adduser -ingroup hadoop one 创建一个one用户,归到hadoop组下
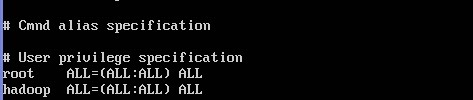
二.由于用户是普通用户,没有root一些权限,所以修改hadoop用户权限
用root权限,修改sudoers文件
nano /etc/sudoers 打开文件,修改hadoop用户权限,如果你创建的是one用户,就one ALL=(ALL:ALL) ALL
三.在这五台机子上分别设置/etc/hosts及/etc/hostname
hosts这个文件用于定于主机名与IP地址之间的对用关系
sudo -i 获取最高权限
nano /etc/hosts:

ctrl+o:保存,然后回车,ctrl+x:退出
hostname 这个文件用于定义主机名的,
注意:主机是主机名,从机就是从机名,例如:datanode在这里就是datanode
然后你可以输入:ping namenode2,看能不能ping通
四.要在这五台机子上均安装jdk,ssh,并配置好环境变量,五台机子都是这个操作::
做好准备工作,下载jdk-7u3-linux-i586.tar 这个软件包
1.sudo apt-get install openssh-server 下载SSH
ssh 查看,代表安装成功
2. tar zxvf jdk-7u3-linux-i586.tar.gz 解压jdk
3.sudo nano /etc/profile,在最下面加入这几句话,保存,这是配置java环境变量

4.source /etc/profile 使其配置生效
验证jdk是否安装成功,敲命令
5.java -version 可以看到JDK版本信息,代表安装成功

6:配置SSH 免密码登陆,记住,这是在hadoop用户下执行的
ssh-keygen -t rsa 之后一路回 车(产生秘钥,会自动产生一个.ssh文件

8.cd .ssh 进入ssh文件
cp id_rsa.pub authorized_keys 把id_rsa.pub 追加到授权的 key 里面去
9. ssh localhost 此时已经可以进行ssh localhost的无密码登陆

或者 ls .ssh/ 看看有没有那几个文件
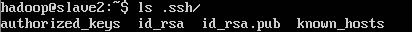
10.拷贝id_rsa.pub文件到其他机器
192.168.0.25 操作:
scp .ssh/id_rsa.pub 192.168.0.26:/home/hadoop/.ssh/25.pub
scp .ssh/id_rsa.pub 192.168.0.27:/home/hadoop/.ssh/25.pub
scp .ssh/id_rsa.pub 192.168.0.28:/home/hadoop/.ssh/25.pub
scp .ssh/id_rsa.pub 192.168.0.29:/home/hadoop/.ssh/25.pub
192.168.0.26 操作:
scp .ssh/id_rsa.pub 192.168.0.25:/home/hadoop/.ssh/26.pub
scp .ssh/id_rsa.pub 192.168.0.27:/home/hadoop/.ssh/26.pub
scp .ssh/id_rsa.pub 192.168.0.28:/home/hadoop/.ssh/26.pub
scp .ssh/id_rsa.pub 192.168.0.29:/home/hadoop/.ssh/26.pub
192.168.0.27 操作:
scp .ssh/id_rsa.pub 192.168.0.25:/home/hadoop/.ssh/27.pub
scp .ssh/id_rsa.pub 192.168.0.26:/home/hadoop/.ssh/27.pub
scp .ssh/id_rsa.pub 192.168.0.28:/home/hadoop/.ssh/27.pub
scp .ssh/id_rsa.pub 192.168.0.29:/home/hadoop/.ssh/27.pub
192.168.0.28 操作:
scp .ssh/id_rsa.pub 192.168.0.25:/home/hadoop/.ssh/28.pub
scp .ssh/id_rsa.pub 192.168.0.26:/home/hadoop/.ssh/28.pub
scp .ssh/id_rsa.pub 192.168.0.27:/home/hadoop/.ssh/28.pub
scp .ssh/id_rsa.pub 192.168.0.29:/home/hadoop/.ssh/28.pub
192.168.0.29 操作:
scp .ssh/id_rsa.pub 192.168.0.25:/home/hadoop/.ssh/29.pub
scp .ssh/id_rsa.pub 192.168.0.26:/home/hadoop/.ssh/29.pub
scp .ssh/id_rsa.pub 192.168.0.27:/home/hadoop/.ssh/29.pub
scp .ssh/id_rsa.pub 192.168.0.28:/home/hadoop/.ssh/29.pub
11.公钥都追加到 那个授权文件里
在192.168.0.25机子上操作:
cat .ssh/26.pub >> .ssh/authorized_keys
cat .ssh/27.pub >> .ssh/authorized_keys
cat .ssh/28.pub >> .ssh/authorized_keys
cat .ssh/29.pub >> .ssh/authorized_keys
在192.168.0.26机子上操作:
cat .ssh/25.pub >> .ssh/authorized_keys
cat .ssh/27.pub >> .ssh/authorized_keys
cat .ssh/28.pub >> .ssh/authorized_keys
cat .ssh/29.pub >> .ssh/authorized_keys
在192.168.0.27机子上操作:
cat .ssh/25.pub >> .ssh/authorized_keys
cat .ssh/26.pub >> .ssh/authorized_keys
cat .ssh/28.pub >> .ssh/authorized_keys
cat .ssh/29.pub >> .ssh/authorized_keys
验证ssh 192.168.0.26 hostname
namenode2
搭建Zookeeper集群
1.下载zookeeper-3.4.5版本:zookeeper-3.4.5.tar.gz,我是放在/home/hadoop下面
tar zxvf zookeeper-3.4.5.tar.gz 直接进行解压
2.配置etc/profile
sudo nano etc/profile 在末尾加入下面配置
export ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.4.5
export PATH=$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf:$PATH
source /etc/profile 使其配置生效
3.配置zookeeper-3.4.5/conf/zoo.cfg文件,这个文件本身是没有的,有个zoo_sample.cfg模板
cd zookeeper-3.4.5/conf 进入conf目录
cp zoo_sample.cfg zoo.cfg 拷贝模板
sudo nano zoo.cfg 修改zoo.cfg文件,红色是修改部分
---------------------------------------------------------------------------------------------------
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/hadoop/zookeeper-3.4.5/data
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the # administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=namenode1:2888:3888
server.2=namenode2:2888:3888
server.3=datanode:2888:3888
server.4=datanode1:2888:3888
server.5=datanode2:2888:3888
------------------------------------------------------------------------------------------------------
注意:创建dataDir参数指定的目录,创建data文件夹,在这个文件夹下,还要创建一个文本myid
cd /home/hadoop/zookeeper-3.4.5
mkdir data 创建data
cd /home/hadoop/zookeeper-3.4.5/data 进入data文件夹下
touch myid 创建文本myid,在这个文本内写入1,因为server.1=namenode1:2888:3888 server指定的是1,
如果一会在其余机子配置,namenode2下面的myid是2,datanode下面myid是3,
datanode1下面myid是4,datanode下面myid是5,这些都是根据server来的
4.主机配置完以后,把zookeeper复制给其余机子
scp -r zookeeper-3.4.5 hadoop@namenode2:/home/hadoop/
scp -r zookeeper-3.4.5 hadoop@datanode:/home/hadoop/
scp -r zookeeper-3.4.5 hadoop@datanode1:/home/hadoop/
scp -r zookeeper-3.4.5 hadoop@datanode2:/home/hadoop/
记住:::::修改从机的myid.从机也要配置etc/profile
5.启动zookeeper,先hadoop集群启动
zkServer.sh start 这个启动是主机从机都要输入启动命令
bin/zkServer.sh status 在不同的机器上使用该命令,其中二台显示follower,一台显示leader
zkCli.sh -server 192.168.0.26:2181 启动客户端脚本
quit 退出
help 可是查看帮助命令
这样zookeeper集群就配置完了
配置hadoop集群2.2.0版本HDFS的HA配置
1.我把hadoop文件放在 /home/hadoop路径下,首先先进行解压
tar zxvf hadoop-2.2.0.tar.gz
2.hadoop配置过程,
配置之前,需要在hadoop本地文件系统创建以下文件夹:
/dfs/name
/dfs/data
/tmp/journal
给这些文件要赋予权限
sudo chmod 777 tmp/
sudo chmod 777 dfs/
这里要涉及到的配置文件有7个:
~/hadoop-2.2.0/etc/hadoop/hadoop-env.sh
~/hadoop-2.2.0/etc/hadoop/yarn-env.sh
~/hadoop-2.2.0/etc/hadoop/slaves
~/hadoop-2.2.0/etc/hadoop/core-site.xml
~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
以上个别文件默认不存在的,可以复制相应的template文件获得。
例如mapred-site.xml不存在
cd /home/hadoop/hadoop-2.2.0/etc/hadoop 进入到hadoop配置文件的目录中
cp mapred-site.xml.template mapred-site.xml 复制相应的模板文件
3.配置hadoop-env.sh
sudo nano /home/hadoop/hadoop-2.2.0/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/home/hadoop/jdk1.7.0_03 配置jdk
4.配置yarn-env.sh
sudo nano /home/hadoop/hadoop-2.2.0/etc/hadoop/yarn-env.sh
export JAVA_HOME=/home/hadoop/jdk1.7.0_03 配置jdk
5.配置slaves,写入一下内容
datanode
datanode1
datanode2
6.配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name> //fs.defaultFS 客户端连接HDFS时,默认的路径前缀。跟配置hdfs-site.xml中nameservice ID的值是一致的
<value>hdfs://mycluster</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.0.25:2181,192.168.0.26:2181,192.168.0.27:2181,192.168.0.28:2181,192.168.0.29:2181</value>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>1000</value>
</property>
</configuration>
7.配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.nameservices</name> //dfs.nameservices命名空间的逻辑名称,如果使用HDFS Federation,可以配置多个命名空间的名称,使用逗号分开即可。
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name> //dfs.ha.namenodes.[nameservice ID] 命名空间中所有NameNode的唯一标示名称。可以配置多个,
<value>nn1,nn2</value> // 使用逗号分隔。该名称是可以让DataNode知道每个集群的所有NameNode。当前,每个集群最多只能配置两个NameNode。
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name> //dfs.namenode.rpc-address.[nameservice ID].[name node ID] 每个namenode监听的RPC地址
<value>192.168.0.25:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>192.168.0.26:9000</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.mycluster.nn1</name>
<value>192.168.0.25:53310</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.mycluster.nn2</name>
<value>192.168.0.26:53310</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name> //dfs.namenode.http-address.[nameservice ID].[name node ID] 每个namenode监听的http地址。
<value>192.168.0.25:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>192.168.0.26:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://192.168.0.25:8485;192.168.0.26:8485;192.168.0.27:8485/mycluster</value>
//dfs.namenode.shared.edits.dir 这是NameNode读写JNs组的uri。通过这个uri,NameNodes可以读写edit log内容。URI的格 式"qjournal://host1:port1;host2:port2;host3:port3/journalId"。这里的host1、host2、host3指的是Journal Node的地址,这里必须是奇数个,至少3个;其中journalId是集群的唯一标识符,对于多个联邦命名空间,也使用同一个journalId。
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name> //dfs.client.failover.proxy.provider.[nameservice ID] 这里配置HDFS客户端连接到Active NameNode
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name> //dfs.ha.fencing.methods 配置active namenode出错时的处理类
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name> //dfs.journalnode.edits.dir 这是JournalNode进程保持逻辑状态的路径。
<value>/home/hadoop/tmp/journal</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
<property>
<name>ipc.client.connect.timeout</name>
<value>60000</value>
</property>
<property>
<name>dfs.image.transfer.bandwidthPerSec</name>
<value>4194304</value>
</property>
</configuration>
8.配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
9.配置yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value> <!—注释, rm1上配置为rm1, rm2上配置rm2-->
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>namenode1:2181</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>namenode1:2181</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<!-- RM1 configs -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>namenode1:23140</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>namenode1:23130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>namenode1:23188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>namenode1:23125</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>namenode1:23141</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>namenode1:23142</value>
</property>
<!-- RM2 configs -->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>namenode2:23140</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>namenode2:23130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>namenode2:23188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>namenode2:23125</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>namenode2:23141</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>namenode2:23142</value>
</property>
<!-- Node Manager Configs -->
<property>
<description>Address where the localizer IPC is.</description>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:23344</value>
</property>
<property>
<description>NM Webapp address.</description>
<name>yarn.nodemanager.webapp.address</name>
<value>0.0.0.0:23999</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/tmp/pseudo-dist/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/tmp/pseudo-dist/yarn/log</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
</configuration>
master配置完以后,可是直接把hadoop文件复制到从机,这样可以节省时间
命令是在hadoop用户下进行:这个只需要在主机运行就可以了
scp -r hadoop-2.2.0 hadoop@namenode2:/home/hadoop/
scp -r hadoop-2.2.0 hadoop@datanode:/home/hadoop/
scp -r hadoop-2.2.0 hadoop@datanode1:/home/hadoop/
scp -r hadoop-2.2.0 hadoop@datanode2:/home/hadoop/
0、首先把各个zookeeper起来,如果zookeeper集群还没有启动的话。
./bin/zkServer.sh start 记住每台机子都要启动
1、然后在某一个namenode节点执行如下命令,创建命名空间
./bin/hdfs zkfc -formatZK
2、在每个节点用如下命令启日志程序
./sbin/hadoop-daemon.sh start journalnode
3、在主namenode节点用./bin/hadoopnamenode -format格式化namenode和journalnode目录
./bin/hadoop namenode -format mycluster
4、在主namenode节点启动./sbin/hadoop-daemon.shstart namenode进程
./sbin/hadoop-daemon.sh start namenode
5、在备节点执行第一行命令,这个是把备namenode节点的目录格式化并把元数据从主namenode节点copy过来,并且这个命令不会把journalnode目录再格式化了!然后用第二个命令启动备namenode进程!
./bin/hdfs namenode –bootstrapStandby
./sbin/hadoop-daemon.sh start namenode
6、在两个namenode节点都执行以下命令
./sbin/hadoop-daemon.sh start zkfc
7、在所有datanode节点都执行以下命令启动datanode
./sbin/hadoop-daemon.sh start datanode
1.4 startupphase
下次启动的时候,就直接执行以下命令就可以全部启动所有进程和服务了:
但是还是要先启动zookeeper,启动日志程序,然后在全部启动
./sbin/start-dfs.sh
然后访问以下两个地址查看启动的两个namenode的状态:
http://192.168.0.25:50070/dfshealth.jsp
http://192.168.0.26:50070/dfshealth.jsp
1.5 stop phase
停止所有HDFS相关的进程服务,执行以下命令:
./sbin/stop-dfs.sh
1.6 测试HDFS的HA功能
在任意一台namenode机器上通过jps命令查找到namenode的进程号,然后通过kill -9的方式杀掉进程,观察另一个namenode节点是否会从状态standby变成active状态。
hd@hd0:/opt/hadoop/apps/hadoop$ jps
1686 JournalNode
1239 QuorumPeerMain
1380 NameNode
2365 Jps
1863 DFSZKFailoverController
hd@hd0:/opt/hadoop/apps/hadoop$ kill -9 1380
然后观察原来是standby状态的namenode机器的zkfc日志,若最后一行出现如下日志,则表示切换成功:
2013-12-31 16:14:41,114 INFOorg.apache.hadoop.ha.ZKFailoverController: Successfully transitioned NameNodeat hd0/192.168.0.25:53310 to active state
这时再通过命令启动被kill掉的namenode进程
./sbin/hadoop-daemon.sh start namenode
对应进程的zkfc最后一行日志如下:
2013-12-31 16:14:55,683 INFOorg.apache.hadoop.ha.ZKFailoverController: Successfully transitioned NameNodeat hd2/192.168.0.26:53310 to standby state
可以在两台namenode机器之间来回kill掉namenode进程以检查HDFS的HA配置!
搭建hbase集群
1.下载并解压hbase-0.98.0-hadoop2-bin.tar.gz到/home/hadoop下面
tar zxvf hbase-0.98.0-hadoop2-bin.tar.gz
2.修改 hbase-env.sh ,hbase-site.xml,regionservers 这三个配置文件如下:
2.1修改 hbase-env.sh
sudo nano /home/hadoop/ hbase-0.98.0-hadoop2 /conf/hbase-env.sh
export JAVA_HOME=/home/hadoop/jdk1.7.0_03
export HBASE_HOME=/home/hadoop/hbase-0.98.0-hadoop2
export HADOOP_HOME=/home/hadoop/hadoop-2.2.0
export PATH=$PATH:/home/hadoop/hbase-0.98.0-hadoop2/bin
export HBASE_MANAGES_ZK=false
注意:如果hbase想用自身的zookeeper, HBASE_MANAGES_ZK属性变为true.
2.2修改 hbase-site.xml
sudo nano /home/hadoop/ hbase-0.98.0-hadoop2/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value> //因为是多台master,所以hbase.roodir的值跟hadoop配置文件hdfs-site.xml中dfs.nameservices的值是一样的
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>namenode1,namenode2,datanode,datanode1,datanode2</value>
</property>
<property>
<name>hbase.master.port</name> //当定义多台master的时候,我们只需要提供端口号,单机配置只需要hbase.master的属性
<value>60000</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>60000</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value> //hbase.zookeeper.property.clientPort配置的这个端口号必须跟zookeeper配置的clientPort端口号一致。
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/zookeeper-3.4.5/data</value> //hbase.zookeeper.property.dataDir配置跟zookeeperper配置的dataDir一致
</property>
</configuration>
2.3修改 regionservers
sudo nano /home/hadoop/ hbase-0.98.0-hadoop2/conf/regionservers
写入以下内容:
datanode
datanode1
datanode2
复制hbase到从机
scp -r /home/hadoop/hbase-0.98.0-hadoop2 hadoop@datanode:/home/hadoop/
scp -r /home/hadoop/ hbase-0.98.0-hadoop2 hadoop@datanode1:/home/hadoop/
scp -r /home/hadoop/ hbase-0.98.0-hadoop2 hadoop@datanode2:/home/hadoop/
然后启动hbase,输入命令,记住:一定要先启动hadoop集群,才能启动hbase
bin/start-hbase.sh
在备节点上只用启动hbase的节点:bin/hbase-daemon.sh start master
我们也可以通过WEB页面来管理查看HBase数据库。
HMaster:http://192.168.0.25:60010/master.jsp
可以输入jps查看HMaster

然后输入如下命令进入hbase的命令行管理界面:quit 退出
bin/hbase shell

bin/stop-hbase.sh 关闭hbase
启动顺序:zookeeper-------hadoop-------hbase
http://www.cnblogs.com/junrong624/p/3580477.html